Dynamic Filter
What is dynamic filter?
Introduce
在Velox中,当一个执行计划需要进行HashJoin时,会将HashJoinNode翻译为两个算子HashProbe和HashBuild,且这两个算子属于不同的Pipeline。
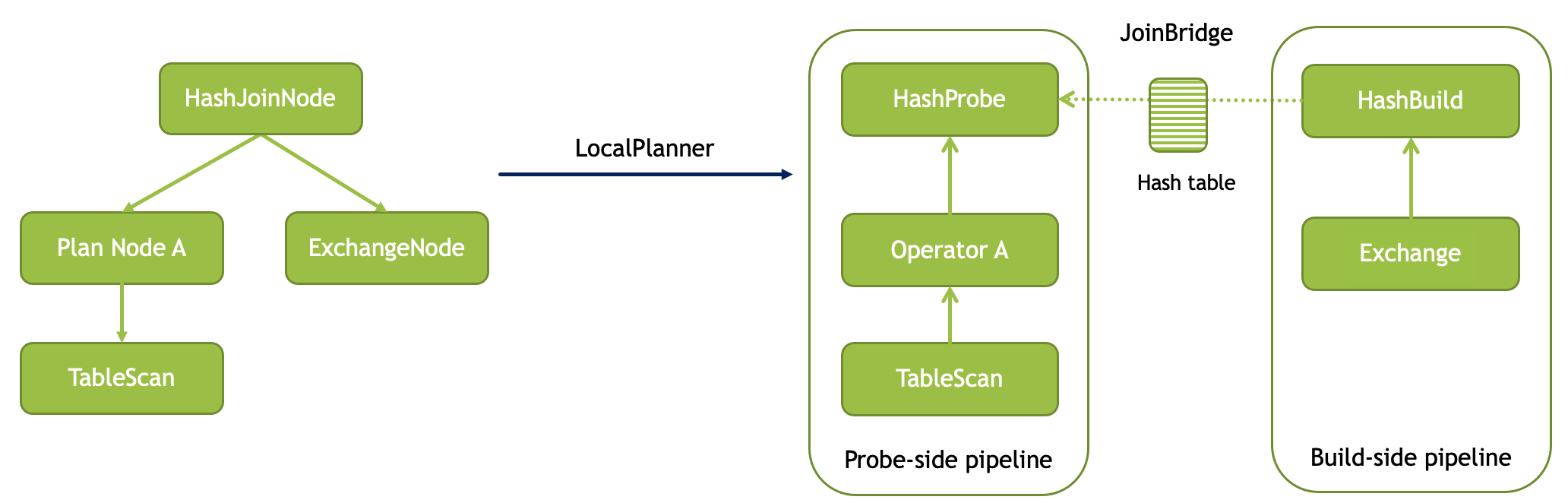
如上所示,Build侧的pipeline最后一个算子为HashBuild。在执行过程中,Probe侧的pipeline会一直阻塞住,等待Build侧的pipeline先执行。当HashBuild完成所有工作后,会将完成的HashTable通过HashJoinBridge告知HashProbe,此时HashProbe侧的pipeline会开始执行。底层的TableScan不断扫描数据最终输入给HashProbe,这个算子再根据HashTable进行Join。
上述流程是一个非常典型的HashJoin执行流程,也就是所谓的小表join大表。一般会假设对于Probe侧的数量量会远大于Build侧,因此如何减少Probe侧输入的数据量就成了提升Join性能的关键。比如Impala/Doris之类的AP系统,或者是PolarDB这类数据库,在此基础上都会在此基础上做各种优化:
- 根据Build和Probe的数据量,决定使用不同的HashJoin方式,比如Bucket HashJoin(或者叫Shuffle/Partition HashJoin,都是将数据进行分片,然后各自进行HashJoin)或者是Broadcast HashJoin(Build数据较少,将Build的结果广播至所有Probe节点再进行HashJoin)。
- 本文要介绍的Dynamic Filter(也称为Runtime Filter)
Dynamic Filter
Dynamic Filter顾名思义,这个Filter是在运行时才产生的,主要思想在于:如果已经知道了Build侧的所有数据之后,我们能否将这些信息告知底层的Scan,从而尽可能减少底层Scan所需要扫描的数据量,或者是减少输入到HashProbe的数据量。我们分成几步看待这个问题:
如何利用Build侧的数据?
当Build侧执行完成后,此时已经知道Build的所有数据,我们有以下几种使用方式:
- 将所有数据转换为一个In-list Filter
- 将所有数据构造成一个Bloom Filter
- 如果数据分布非常集中,可以构造一个MinMax Filter
利用这个Filter,Scan侧可能就能少扫描数据,或者是减少输入到Probe的数据。
如何将Dynamic Filter下推?
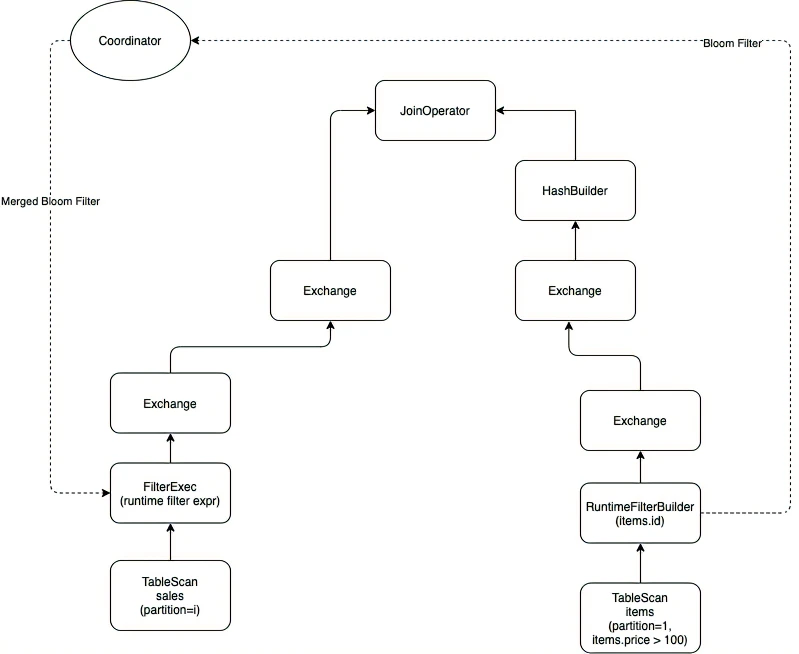
这部分各个系统的处理方式都很相似,假设这里使用Bloom Filter作为要下推的Dynamic Filter。由于可能有多个Build节点,每个Build节点会生成自己扫描数据所生成的Bloom Filter,因此需要一个Coordinator来进行合并。当收集到所有Bloom Filter后,Coordinator会进行合并,生成最终的Dynamic Filter,并告知Probe。此后TableScan扫描的数据就会经过过滤,大大减少输入至HashJoin的数据量,提升Join性能。
有所不同的地方在于,在Impala/Doris/PolarDB中,Probe侧不会一直阻塞等待Dynamic Filter,而是等待一个固定时长(Impala和Doris默认是1秒),无论这段时间之内有没有收到Coordinator发送来的Dynamic Filter,都会开始扫描数据。当收到Dynamic Filter之后,后续扫描出来的数据才会经过过滤。这样做的主要优点在于把Dynamic Filter变成一个异步优化,减少Dynamic Filter带来的额外开销影响。另外在Build和Probe两边数据量接近的情况下,显然阻塞等待Build侧也是不合适的。
但在Velox中,Dynamic Filter是阻塞等待的。主要原因是由于Velox的Runtime机制,HashProbe必须等待HashBuild,而HashBuild完成之后,Dynamic Filter也可以构造完成并开始下推。
为什么不能总是减少扫描数据量?
Dynamic Filter很多时候并不能减少扫描的数据量,而只能减少输入到join的数据量,这里Filter类型以及数据存储有关,不同系统的实现也有所差别。
- 不能减少的情况
如果下推的是一个Bloom Filter类型的Dynamic Filter,此时由于并不完全清楚Build侧的数据,因此必须扫描全部数据,再通过Bloom Filter进行过滤。Impala/Doris/PolarDB都支持使用Bloom Filter,此时并不能减少扫描数据量,并且由于Bloom Filter的构造和使用代价会更高,多数系统都会限制Bloom Filter的个数。
- 可以减少的情况
如果下推的是一个In-list Filter或者MinMax Filter,如果底层的存储是HDFS,可能就能基于文件进行过滤。如果是Impala使用Kudu来存储数据,那有可能进行column predicate下推,过滤性能可能会更好。这种情况下能够减少扫描的数据量,而Dynamic Filter过滤性能最好时,能够把整个文件都跳过扫描。
Dynamic Filter的理论基础
A INNER JOIN B = (A LEFT SEMI-JOIN B) INNER JOIN B
A INNER JOIN B = A INNER JOIN (B LEFT SEMI_JOIN A)
生成的Dynamic Filter即是给left semi-join的join condition,即生成的join condition要求A left semi-join B的结果必须是A innner join B的结果的超集。超集意味着和Dynamic Filter允许有假阳性,即Dynamic Filter可以不是一个精确的filter。它可以多捞一些数据,也就是满足Dynamic Filter的数据有可能在后面的inner join时仍然被过滤掉。
Dynamic Filter in Velox
我们以这样一个语句来介绍Velox中的Dynamic Filter。
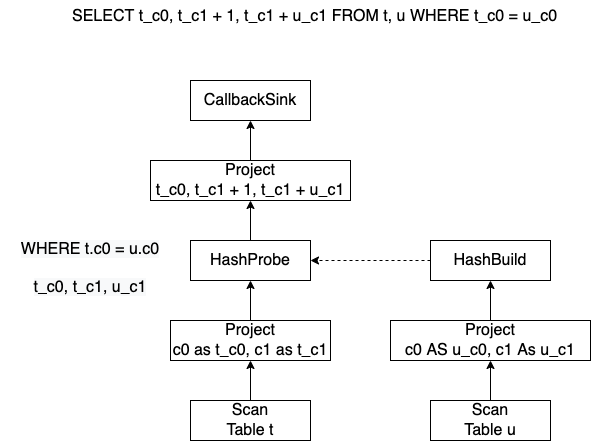
HashJoin被翻译为了HashProbe和HashBuild,HashJoin的条件是WHERE t_c0 = u_c0,HashProbe输出列为t_c0, t_c1和u_c1。
生成的Task和对应Drivers如下
Task:
-- Project
-- HashJoin
-- Project
-- TableScan
-- Project
-- Values
Drivers:
{Driver: TableScan(0) FilterProject(1) HashProbe(2) FilterProject(3) CallbackSink(4)}
{Driver: Values(0) FilterProject(1) HashBuild(2)}
相关的执行过程如下:
HashProbe会一直阻塞,等待HashBuild完成,相关函数如下
HashProbe::isBlocked
-> HashProbe::asyncWaitForHashTable
- 当
HashBuild完成,将HashTable放到HashJoinBridge中,之后HashProbe会唤醒,HashProbe此时会尝试开始设置Dynamic Filter。
相关逻辑在HashProbe::asyncWaitForHashTable和Driver::canPushdownFilters中。核心逻辑就是从keyChannels_看有没有任何列可以启用Dynamic Filter (所谓keyChannels_也就是HashProbe的join字段,对应例子中的t_c0)
我们对应这个例子来看,HashProbe的keyChannels_为t_c0,所在的Pipeline算子如下
{Driver: TableScan(0) FilterProject(1) HashProbe(2) FilterProject(3) CallbackSink(4)}
在Driver::canPushdownFilters中会从后往前检查HashProbe之前的算子,即先检查FilterProject(1),再检查TableScan(0)。检查的主要方式就是找到每个join字段所在列最开始是从哪个算子生成的,以及这个算子能否支持增加Dynamic Filter。
具体步骤如下,对于FilterProject,我们发现t_c0这一列不是由这个算子生成的,而是从Project的输入c0直接复制而来的,所以我们要沿着pipeline去查c0这一列是在哪里生成的。然后发现c0是在TableScan中生成的,并且TableScan能够增加Dynamic Filter,此时在HashProbe中增加一个Dynamic Filter。
- 在
Driver::runInternal中如果发现某个算子有dynamic filter,会尝试将这个算子的dynamic filter push down到前面的算子中(也就是TableScan中)。这部分逻辑都是在Driver::pushdownFilters中完成,主要逻辑和Driver::canPushdownFilters很相似。 - 当TableScan收到DynamicFilter之后,扫描的数据量可能就会减少,或者至少减少输出给HashProbe的数据量,提升性能
另外,由于pipeline的调用顺序,HashProbe可能会在调用Driver::pushdownFilters之前,就会调用HashProbe::getOutput,此时必须返回nullptr。整套流程说起来其实比较简单,但涉及的代码细节挺多,后面会再写一篇,结合源码详细解释Dynamic Filter的下推过程。
Reference
Runtime Filtering for Impala Queries (Impala 2.5 or higher only) (apache.org)
Impala - Runtime Filter的原理及实现-云社区-华为云 (huaweicloud.com)
云数据仓库 for Apache Doris Runtime Filter-开发指南-文档中心-腾讯云 (tencent.com)