2PC in TLA+, step 2
在上一篇里我们实现了一个最简单的2PC,其中无论RM还是TM都不会crash。在这一篇中我们会引入RM随时可能crash的情形,看看需要对2PC的实现进行多少修整。
2PC with RM crash
首先我们引入一个新的RM状态"unavailable",{"working", "prepared", "committed", "aborted"}中状态都可以转换为"unavailable"。
当RM发生故障时,就会转换为"unavailable",此时RM的消息队列会清空。同时我们允许RM根据自身日志恢复到故障之前的状态:
fair process (RManager \in RM)
variables msg = <<>>, crash_state = "";
{
RM_MAIN:
while (rmState[self] \notin {"committed", "aborted"}) {
recv(msg);
\* rm收到消息后可以选择处理消息 或者挂
either {
RM_HANDLE:
if (rmState[self] = "working" /\ msg.type = "prepare") {
rmState[self] := "prepared";
} else if (rmState[self] = "prepared" /\ msg.type = "commit") {
rmState[self] := "committed";
} else if ((rmState[self] = "working" \/ (rmState[self] = "prepared" /\ tmState["state"] = "abort"))
/\ msg.type = "abort") {
rmState[self] := "aborted";
} else {
assert FALSE;
}
} or {
await RMMAYFAIL;
RM_CRASH:
crash_state := rmState[self];
rmMsg[self] := <<>>;
rmState[self] := "unavailable";
RM_RECOVER:
rmMsg[self] := <<>>;
rmState[self] := crash_state;
}
}
}
RM在收到TM发送来的消息之后,RM可以处理这个消息,或者是还没来得及处理就挂掉了(either-or语句)。如果发生故障,RM会清空自身消息队列,并记录crash_state用于之后恢复,然后将自身状态修改为unavailable。恢复时根据日志也就是crash_state进行恢复,然后初始化消息队列。
然后我们需要调整canAbort以激活这个路径(上一篇的canAbort实际上是不可能成立的),一旦有RM处于aborted或者unavailable状态,那么这个事务就需要abort。
define {
canCommit == \A rm \in RM : rmState[rm] \in {"prepared"}
canAbort == \E rm \in RM : rmState[rm] \in {"aborted", "unavailable"}
}
其余不需要进行任何改动,我们可以试着运行以下看看结果。
First Try
TLC设置如下:同样是3个RM,然后允许RM挂掉,Invariants和Temporal Properties不用修改。
运行以后,TLC提示遇到了死锁。可以看到RM3在除了prepare消息之前发生了crash。当恢复之后,之前的消息已经不可恢复,而TM也不会再发送新的prepare消息,三个RM的状态将一直停留在prepared, prepared和working。
要解决这个问题,TM不再只能prepare/commit/abort一次,而应当不断重试直至成功。我们把TM改成一个while循环,只有当所有RM都退出时,TM才能退出循环。循环内部每次就根据rmState来判断是发送prepare/commit/abort消息中的哪一种。
fair process (TManager = 0)
variables idx = 1;
{
TM:
while (~ \A rm \in RM : pc[rm] = "Done") {
either {
await canCommit;
tmState["state"] := "commit";
call broadcast([type |-> "commit"]);
} or {
await canAbort;
tmState["state"] := "abort";
call broadcast([type |-> "abort"]);
} or {
\* 这里简单粗暴点 直接每次都再广播 实际可以查询rmState 只发送给没有prepare的RM
await tmState["state"] = "init";
await ~(canCommit \/ canAbort);
call broadcast([type |-> "prepare"]);
}
}
}
运行之前需要把之前RM中的
assert FALSE分支去掉,否则会直接挂,比如一个处于prepared状态的此时可能会再次收到prepare消息。
Second Try
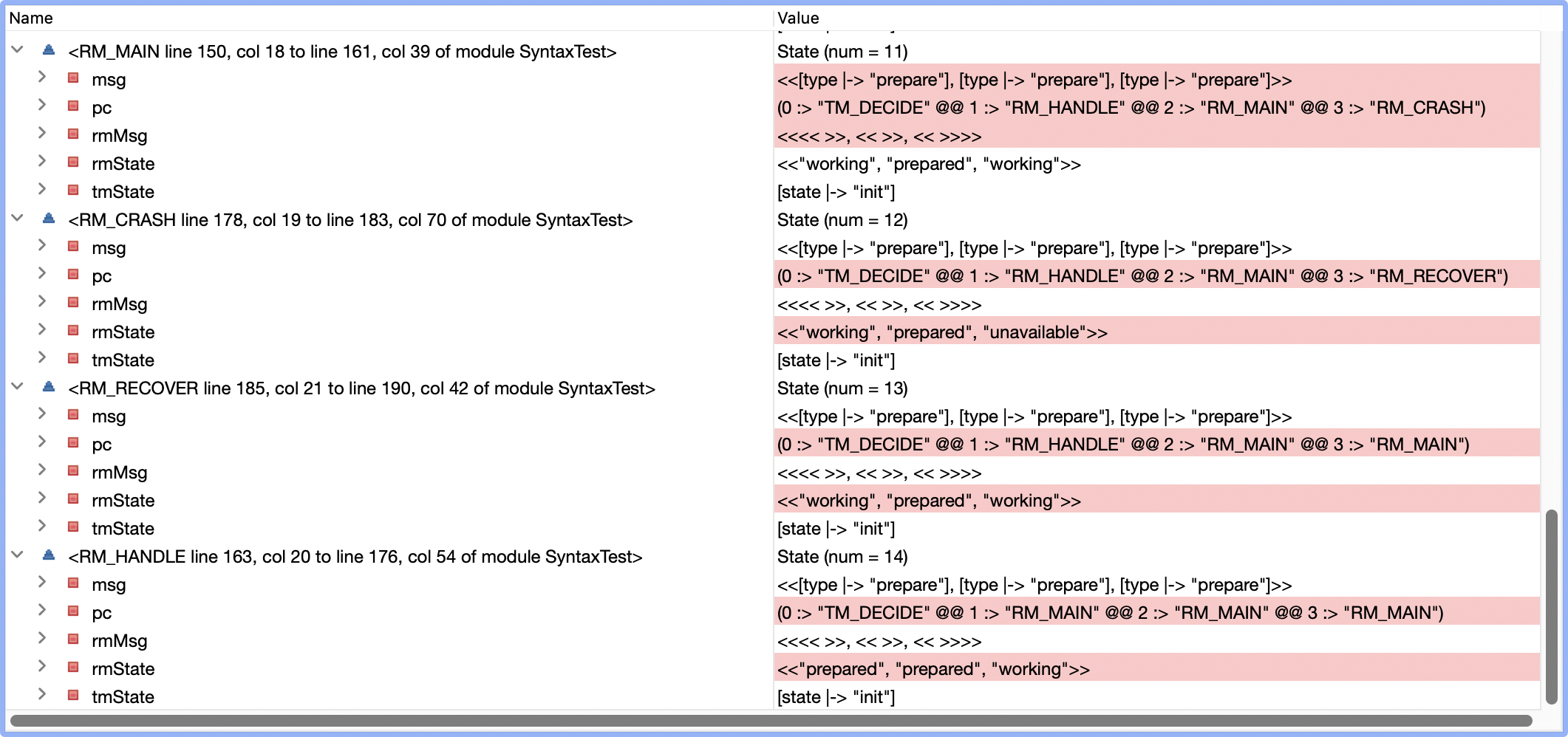
运行之后报错Temporal properties were violated,也就是不能满足在有限时间内事务会commit或者abort,Error Trace如下,省略了其他变量


可以看到RM2在state 10会挂掉,在state 11开始recover,此后有分别在state 22和23再次crash和recover。最终一直在state 13 - state 26之内不断循环,而整个过程中RM2从来没有进入到过prepared状态(途中有收到过prepare消息 图中被省略了)。
这个问题本质上就在于,当我们允许RM无限次crash,而某个RM在理论上可以刚好在每次收到prepare消息时挂掉,随后重启,RM开始重发preapre消息,这个循环可以不断进行下去,导致事务无法推进下去。
为了解决这个问题,我们限制RM只能在某个状态crash一次(当然真实世界不是这样的),把crash分支的等待条件改为如下,如果之前的crash_state和当前状态相同,就不会再crash了。
await RMMAYFAIL /\ (crash_state /= rmState[self]);
Third Try
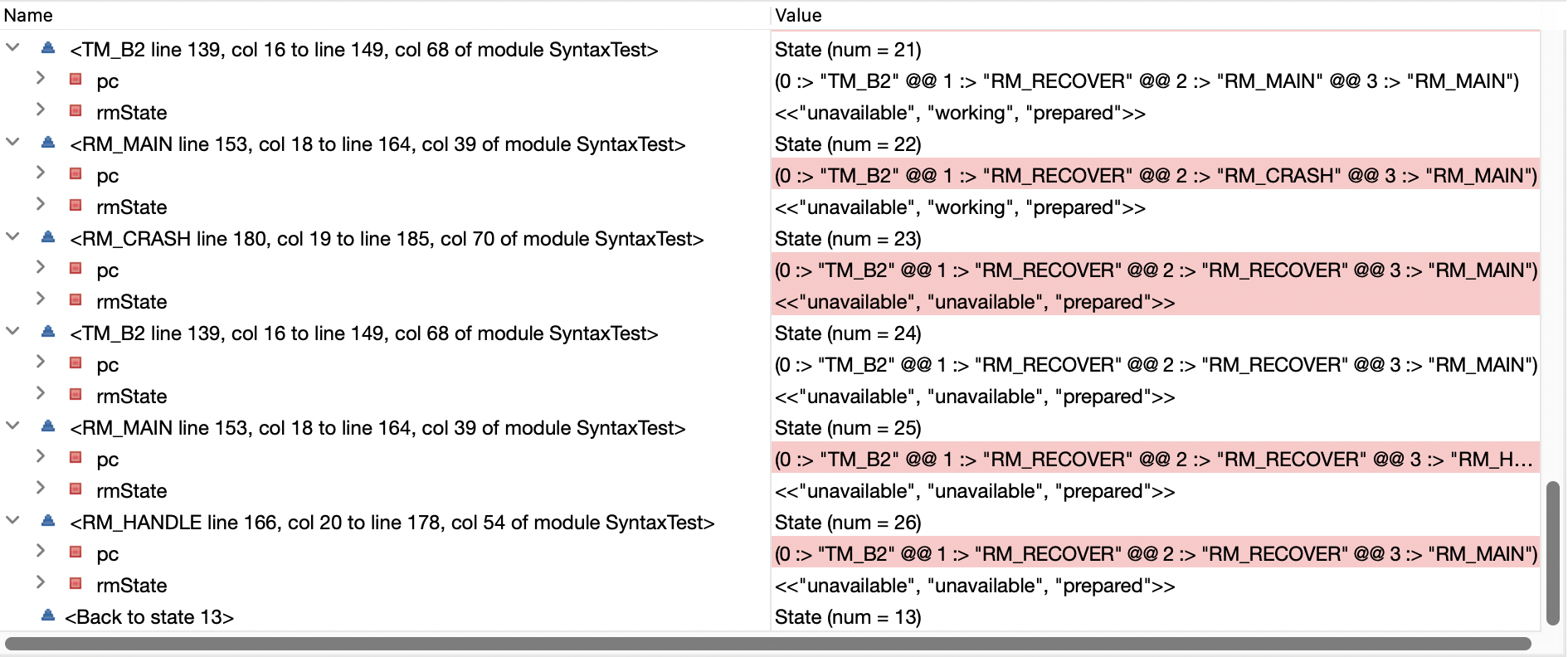
再次运行,TLC又一次提示死锁,Error Trace如下:


state 11时RM1处于unavailable状态,于是TM决定abort掉这个事务,修改tmState为abort,state 17时TM给所有RM都发送了abort消息。然而由于各个RM都在之后挂掉重启,没有RM处理了abort消息。到state 22时,所有RM都变成working状态。然而此时canCommit = FALSE且canAbort = FALSE,导致事务无法推进。
修正的方式就是,如果TM一定决策commit或者abort后,必须反复重试,直至所有RM状态都修改完。所以修改了commit和abort分支的await条件如下所示:
fair process (TManager = 0)
variables idx = 1;
{
TM:
while (~ \A rm \in RM : pc[rm] = "Done") {
either {
await canCommit \/ tmState["state"] = "commit";
tmState["state"] := "commit";
call broadcast([type |-> "commit"]);
} or {
await canAbort \/ tmState["state"] = "abort";
tmState["state"] := "abort";
call broadcast([type |-> "abort"]);
} or {
\* 这里简单粗暴点 直接每次都再广播 实际可以查询rmState 只发送给没有prepare的RM
await tmState["state"] = "init";
await ~(canCommit \/ canAbort);
call broadcast([type |-> "prepare"]);
}
}
}
当然对于类似Percolator或者CRDB这一类的2PC变种是做了相应优化的,实践上不一定需要所有RM状态都变成committed或者aborted。
Fourth Try
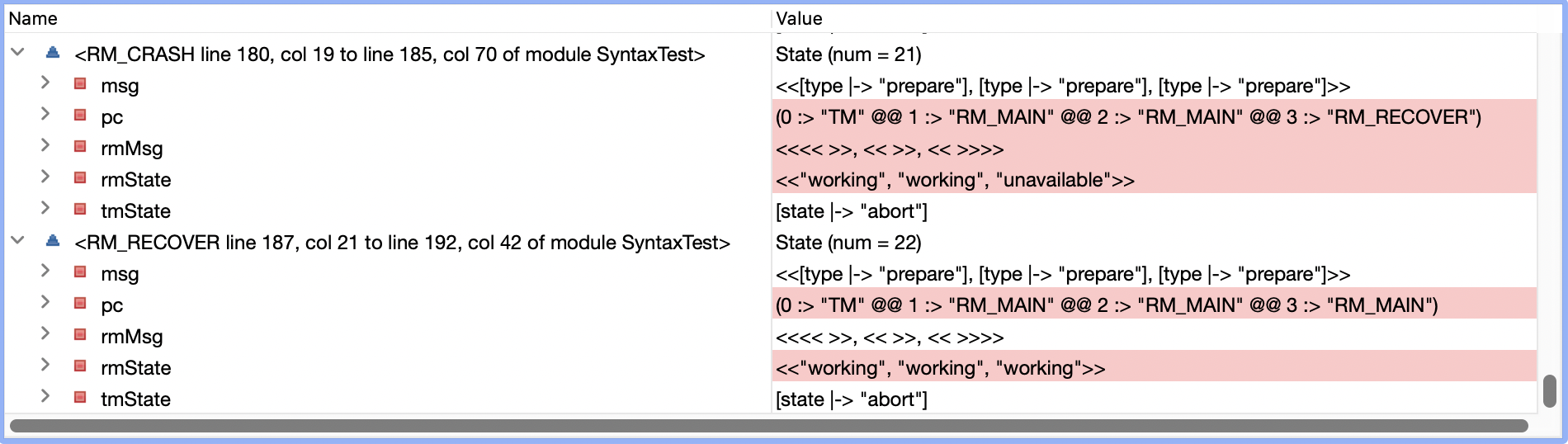
运行之后,TLC报了新的错误,Invariant Consistency is violated!也就是有的RM状态是committed,有的RM状态是aborted,这对于一个事务来说是不可接受的。我们来看看Error Trace:
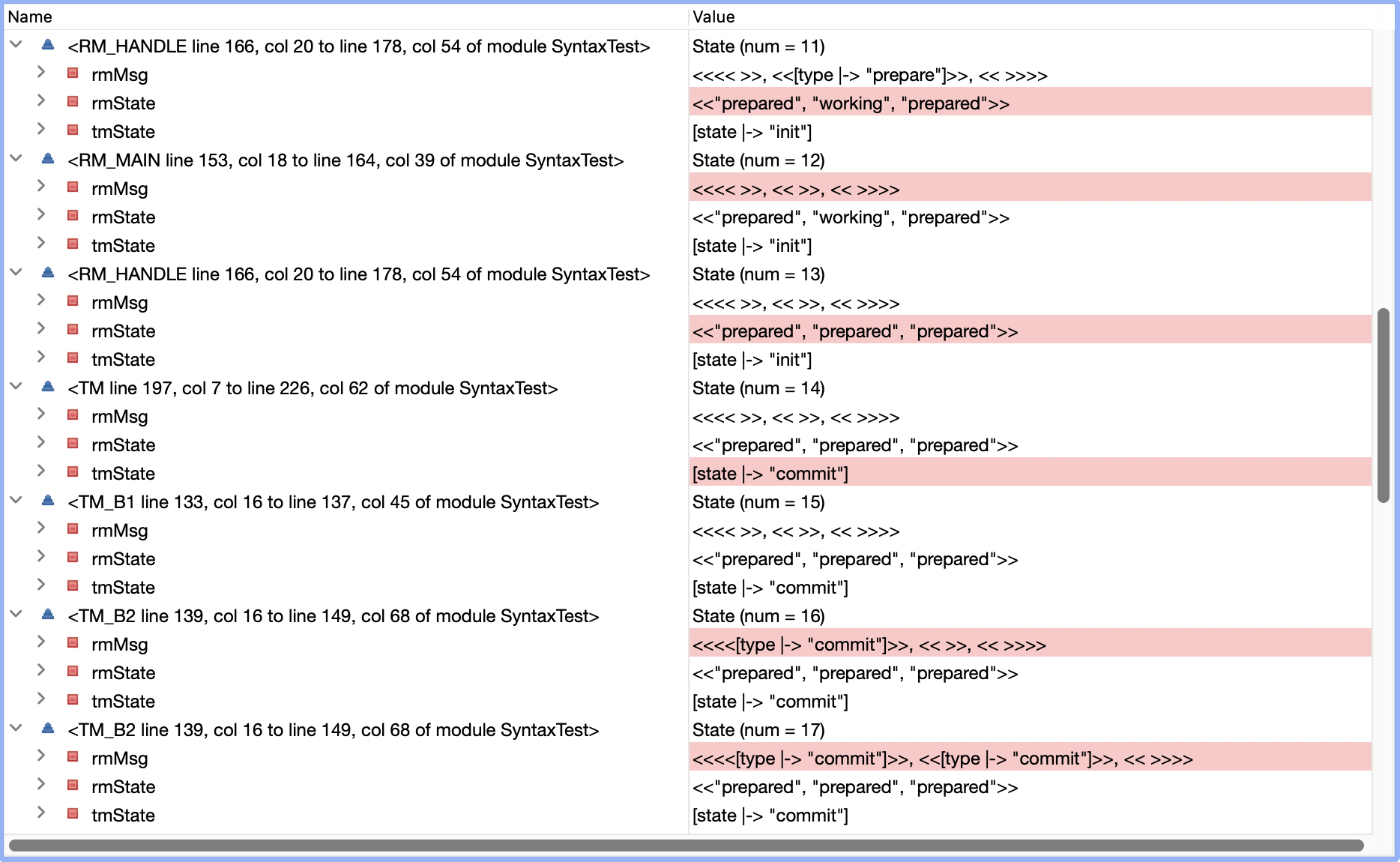

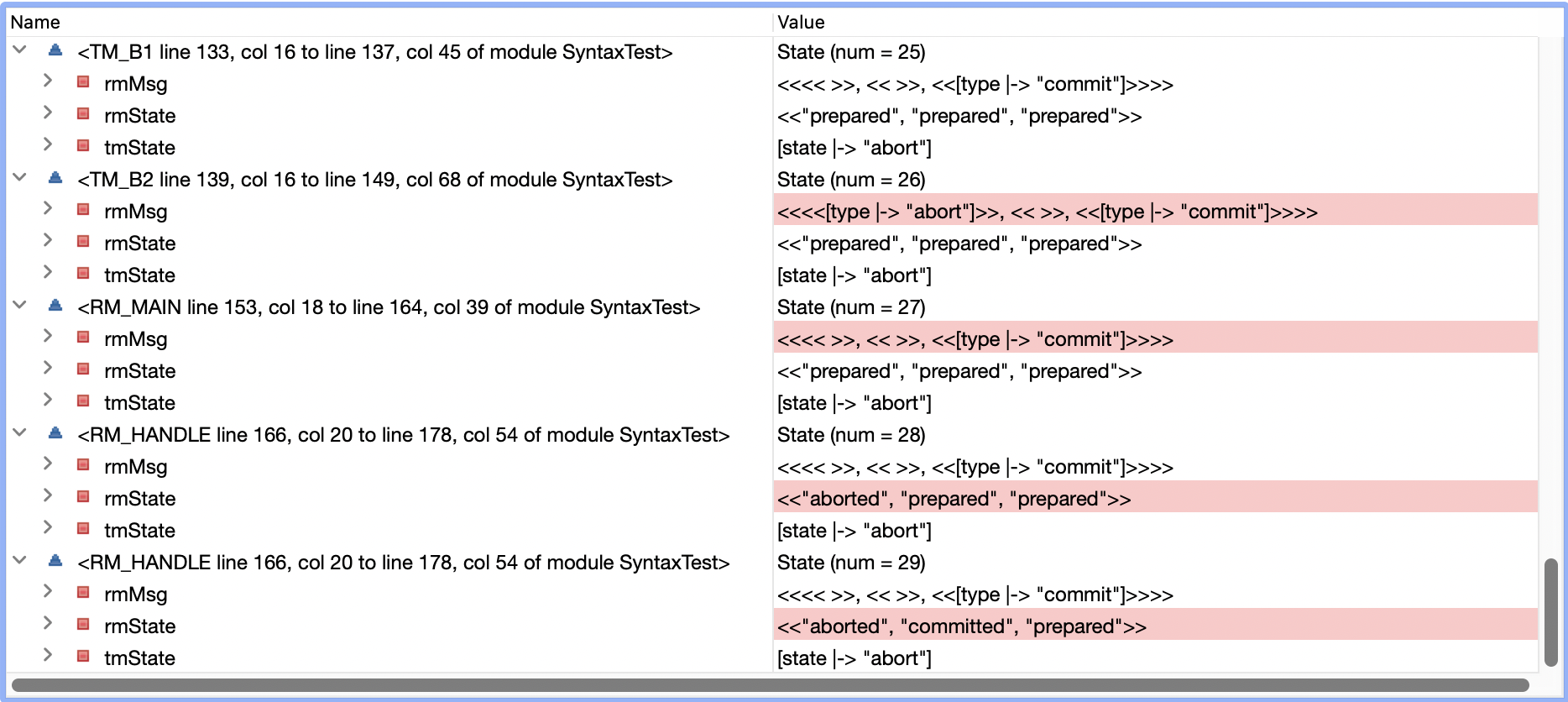
- state 11时所有RM都是
prepared状态,TM决定commit - state 18时TM给所有RM都发送了commit消息
- state 22时,RM1还没有处理commit消息,变为
unavailable状态 (RM2和RM3收到 也还未处理) - state 23时,TM发现RM1挂掉,因为只要有RM挂掉,事务就需要abort,TM决定abort
- state 26时,TM给RM1发送abort消息
- state 28时,RM1收到并处理完成abort消息,变成
aborted状态 - state 29时,RM2开始处理TM之前发送的commit消息,变成
committed状态
RM1和RM2的结果不一致- -b,问题出在哪里呢?我们知道,一个事务一旦决定commit之后,就不能再abort,否则就会像上面例子一样出现不一致的状态。同理,一个事务一旦决定abort之后,也不能再commit。所以我们修改canCommit和canAbort如下
canCommit == /\ \A rm \in RM : rmState[rm] \in {"prepared"}
/\ tmState["state"] /= "abort"
canAbort == /\ \E rm \in RM :rmState[rm] \in {"aborted", "unavailable"}
/\ tmState["state"] /= "commit"
Fifth Try
再次运行,TLC不再会报错了,在我的mac上运行了5分钟之后,状态数量已经来到了千万级别,占用磁盘也接近1G。这个状态搜索空间显然太大了,由于TLC默认是采用BFS进行搜索,所以我们也许有理由相信,现在的实现没有问题,但是有没有办法能让状态搜索空间显著降低呢?
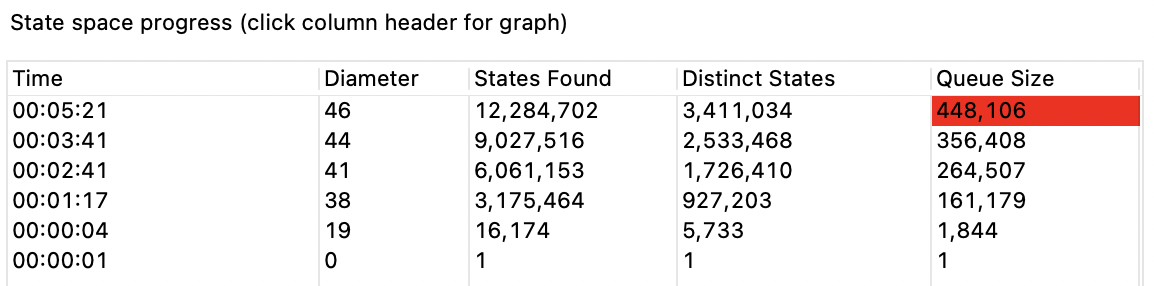
答案是有的,在我们之前的实现中,RM的消息是通过一个无限大小的FIFO队列来完成的,由于TM可以将相同消息发送多次,就有可能导致RM的消息队列过长,也就导致这个模型无法被完全验证。由于TM能发送的消息类型是有限的,我们其实可以将消息队列从Sequence改为Set,也就能完成消息的去重功能,就能大大减少状态搜索空间,最后运行结果如下:
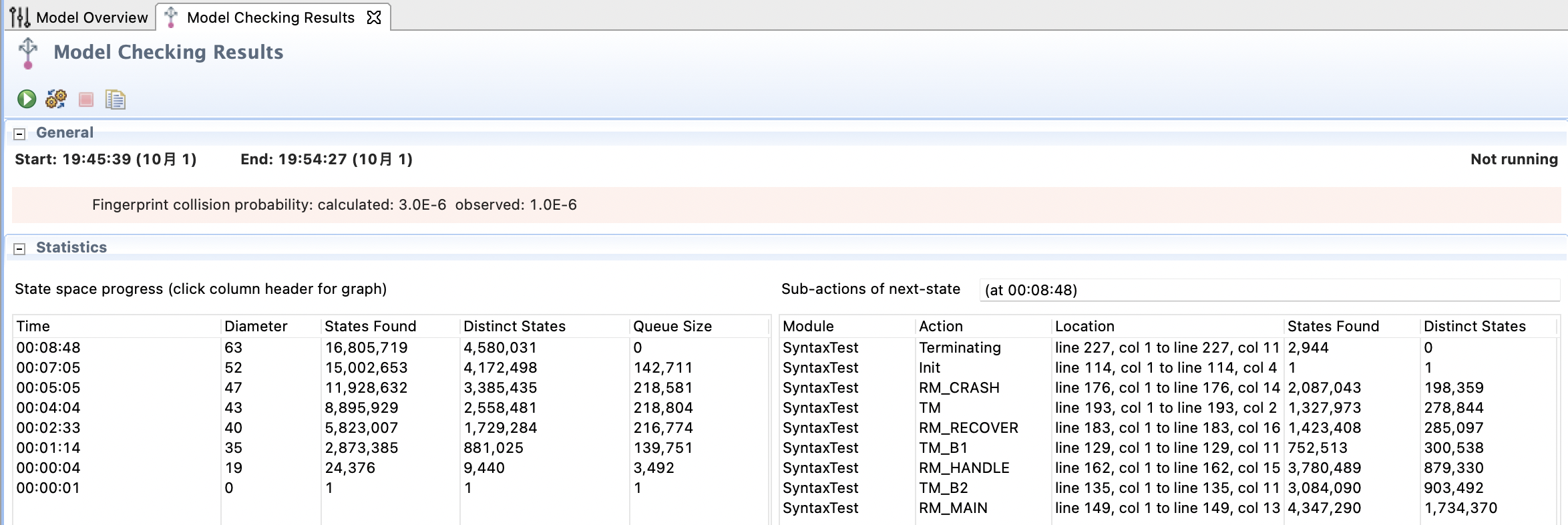
这个图是有3个RM,如果改成两个,速度会快很多,大概10s就完成
Lessons Learned
仅仅允许RM挂掉这一个修改,就需要对specification进行如此多的修改,文中的其实只是踩过的很小一部分。通过TLA+来验证算法是否正确,要求我们对于算法模型中的任何一个逻辑都要认真思考以及准确的表达出来。一旦有任何理解不到位或者词不达意的描述,就会导致无法通过验证。通过不断的验证 → 修改specification本身(有时候也会放宽Invariants和Temporal Properties限制)→ 再次验证的这样循环,我们都在驱使specification向更精确的方向对算法进行描述。当我们更精确的描述时,又再次驱使你的大脑思考,这个过程虽然痛苦,但是具有正反馈,非常值得体验。
另外,在写specification时候,我们到底应该对哪些部分做一些假设,哪些部分详细描述,还有待更深刻的体会。做出某些假设(比如这个例子中网络就是稳定的,不会出现丢包),能够简化specification的实现,同时也能够减少状态搜索空间。而详细描述的部分,一定是我们想要重点验证的部分。同时在实现的时候还需要各种技巧,如何保证精确描述,同时尽量减少状态搜索空间,还有不少东西需要学习。