Calling Functions
最近一直没空学些东西,这两天看了Calling Functions: A Tutorial这个演讲,它详尽的阐述了在函数调用时,编译器如何选择了正确的函数。从这个视角,能把很多概念串联起来(或者说能把一些常见写法和对应的术语对应起来),也能理解这个过程中背后设计的思想。
Overview
整个过程分为如下的步骤,相关术语都尽量保留了英文。注意整个过程是单向的。
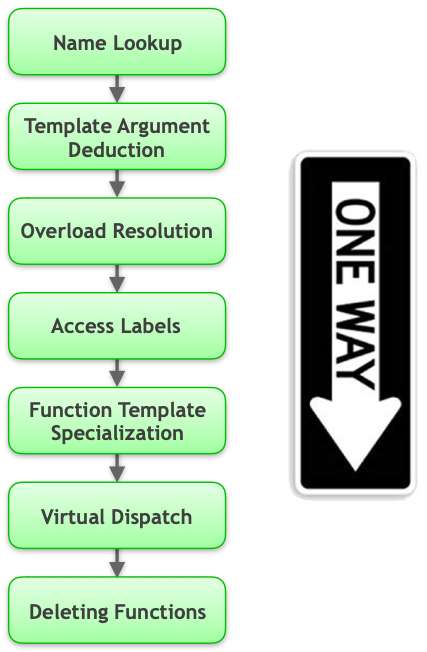
- Name Lookup(名称查找):在当前作用域内选择所有具有特定名称且可见的候选函数。如果未找到,则继续进入下一个外层作用域。这一过程最终形成一个候选集合。
- Template Argument Deduction(模板实参推导):对于候选集合中的函数模板,根据给定的模板实参推导所有函数模板参数,并将其添加到重载集中。SFINAE也是发生在这一步。
- Overload Resolution(重载决议):从候选集合中找到最佳匹配项。这一步可能会进行实参类型转换。
- Access Labels(访问标签):检查最佳匹配函数在调用点是否可访问。
- Function Template Specialization(函数模板特化):如果最佳匹配来自某个模板,则从所选函数模板的所有特化版本中选择最终调用的函数。
- Virtual Dispatch:如果最佳匹配是虚函数,则需要挑选到most derived子类的对应虚函数。
- Deleting Functions:检查最佳匹配函数是否已被通过
=delete显式删除。
每个阶段的术语,根据语境不同,会中英文混用
Name Lookup
首先第一步就是名称查找,整体上遵循的核心原则就是:
- Unqualified lookup: 按作用域层级(包括作用域内的
using),由内而外找到第一个匹配的名字 - Qualified lookup: 只在指定的类或者namespace中查找。
- 二者的区别就在是否带
::
可以对照下面几个例子加深理解,不做过多解释。
void f(double); // (1)
namespace N1 {
void f(int); // (2)
} // namespace N1
int main() {
f(1.0); // Unqualified lookup; calls (1)
f(42); // Unqualified lookup; calls (1)
N1::f(42); // Qualified lookup; calls (2)
}
对于Unqualified lookup,从调用处开始,最先找到的变量名或者函数名会把外层的名称都隐藏掉。因此h中优先查找N1这个namespace中的f,因此调用的是N1中的f。
void f(double); // (1)
namespace N1 {
void f(int); // (2): Function (2) hides function (1)
void g() { N1::f(1.0); }
void h() { f(1.0); }
} // namespace N1
int main() {
N1::g(); // Qualified lookup; calls (2)
N1::h(); // Unqualified lookup; calls (2)
}
注意,Name Lookup阶段,变量名也会被考虑在内:
void f(double); // (1)
namespace N1 {
constexpr int f = 1; // (2): Variable (2) hides function (1)
void g() { N1::f(1.0); }
void h() { f(1.0); }
} // namespace N1
int main() {
N1::g(); // Ill-formed, f cannot be used as a function
N1::h(); // Ill-formed, f cannot be used as a function
}
class Base {
virtual void f(int); // (1)
virtual void f(double); // (2)
};
class Derived : public Base {
void f(double) override; // (3): Function(3) hides function(1) and (2)
};
int main() {
Derived d{};
d.f(42); // Calls (3)
}
Argument Dependent Lookup
前面我们基本只讲了基本类型,当Name Lookup涉及到struct或者class时,编译器就会额外考虑类所在的namespace了。比如下面例子中,S这个类型来自于N1这个namespace,所以Name Lookup时就会查找N1这个namespace。
Remember that ADL only works for user-defined types.
void f(double); // (1)
namespace N1 {
void f(int); // (2)
struct S {};
void f(S); // (3)
} // namespace N1
int main() {
N1::S s{};
f(s); // Argument dependent lookup (ADL); calls (3)
}
对于这个例子,需要注意的是,在Name Lookup阶段编译器会将3个
f函数都作为候选,在后续的Overload Resolution才决定3是最佳匹配。
关于ADL,一个很常见的例子就是std::swap。如下所示:
namespace N1 {
struct S {};
void swap(S&, S&); // (1)
} // namespace N1
template <typename T>
void g(T& a, T& b) {
std::swap(a, b);
}
template <typename T>
void h(T& a, T& b) {
using std::swap;
swap(a, b);
}
int main() {
N1::S s1{};
N1::S s2{};
g(s1, s2); // Qualified lookup, calls std::swap
h(s1, s2); // Unqualified lookup, calls swap(S,S)
}
g(s1, s2)由于是Qualified lookup,所以只会调用std::swap。而h(s1, s2)是Unqualified lookup,因此ADL会额外查找到N1中的swap函数。即为了让ADL能生效,需要使用Unqualified lookup。至于h中的using std::swap;,只是为了将std::swap加入到Name Lookup的结果中,而最终挑选则是在后续的Overload Resolution阶段才完成。
Two-Phase Lookup
对于模板,事情会更复杂一点。Name Lookup的查找规则分为两阶段:
- 模板定义时查找不依赖模板参数的名字
- 模板实例化时查找依赖模板参数的名字
void f(double); // (1)
template <typename T>
void g(T t) {
f(t);
}
void f(int); // (2)
namespace N1 {
struct S {};
void f(S); // (3)
} // namespace N1
int main() {
N1::S s{};
g(s); // Argument dependent lookup (ADL); calls (3)
g(42); // Regular lookup (no ADL); calls (1)
}
以上面代码为例,g(s)由于ADL的介入,所以会调用f(S),不多赘述。而g(42)则“出人意料”的调用了f(double)。这里就和模板的两阶段查找密切相关:
- 定义模板函数
g时,此时编译器看到f(t)会进行Unqualified lookup,因此候选集合中只有f(double)。而f(int)的声明在模版定义之后,因此不会在第一阶段找到。 - 模版实例化
g(42)时,只通过ADL查找依赖模板参数的名字,即只查找与int类型关联的命名空间和类,由于int为内置类型,因此不会找到额外函数。因此最终就挑选候选集中唯一的f(double)。
Template Argument Deduction
在Name Lookup之后,此时的候选集合中包含若干非模版函数和若干模板函数。对于模板函数,此时要进行模板实参推导(或者叫模版参数推导)。这一步可以参考引用中的相关材料,不做单独展开了。
Overload Resolution
重载决议主要分成以下两步:
- 从给定的候选函数集合中,选出所有与给定参数数量匹配且能够被调用(无论是否需要转换)的函数。
- 从可行候选集合中寻找最佳匹配,确定一个与给定参数匹配程度最高的函数。
即经过Name Lookup和Template Argument Deduction之后,我们已经有一个候选集合。而Overload Resolution的第一步,就要在这个候选集合中,挑选出可以调用的函数集合(即符合函数调用习惯的)。如下所示,对于单个参数的函数f,列出了一些能被调用和不能被调用的例子。
struct Widget {
Widget(int);
};
// Viable candiates
void f(int); // Exact/identity match
void f(const int&); // Trivial conversions
void f(double); // Standard conversions
void f(Widget); // User-defined conversions
void f(int, int = 0); // Default arguments
void f(integral auto); // Matching constraints
void f(...); // Ellipsis argument
// Non-viable candidates
void f(); // Less parameters than arguments
void f(int, double); // More parameters than arguments
void f(std::string); // No conversion available
void f(floating_point auto); // Violated constraints
int main() {
f(42); // Call 'f()' with a single 'int' argument
}
这里能看到即便对于1个参数的函数,也有这么多种写法,编译器的任务就是在其中挑选最匹配的一个函数进行调用。这里根据函数参数的不同,由高到低分为不同优先级:
- Exact/identity match
- Trivial conversion (比如int → const int&)
- Promotion (内置类型的向上转型,比如short → int)
- Promotion + trivial conversion
- Standard conversion (比如int → float, float → int, Derived → Base, int → short)
- Standard conversion + trivial conversion
- User-defined conversion
- User-defined conversion + trivial conversion
- User-defined conversion + standard conversion
- Ellipsis argument
编译器优先挑选优先级更高的函数,如果同一个优先级最终有多个写法,则编译器无法找到best match,也就是通常所说的调用存在歧义the call is ambiguous。
而多个参数的函数会更复杂:首先对其中每个参数,都应用单个参数的规则。如果某个函数在至少一个参数上被认为更优,而在所有其他参数上都不差于其他函数,则该函数被选为最佳匹配。否则,该调用存在歧义。
重载决议的详细规则也十分复杂,完整过程可以参考这里。
Access Labels
当重载决议完成后,如果最佳匹配是一个成员函数,则会检查该成员函数能否被调用。如下所示:
class Object {
public:
void f(int); // (1)
private:
void f(double); // (2)
};
int main {
Object obj{};
obj.f(1.0); // (2) is selected; access violation!
}
- Name Lookup挑选了两个函数都作为候选集合
- Overload Resolution认为
f(double)是best match - 然后检查
f(double)是否可访问,发现违背了类的封装报错
这里我们可以大致讨论下为什么以这个顺序进行检查,一个很重要的原因就是:给定一个类的成员函数和传入的参数,无论它是在类中调用还是类之外调用,最终都应当对应同一个函数。如果先检查成员函数是否可用,则显然会破坏这个约定。
Function Template Specialization
当重载决议完成后,如果最佳匹配来自某个模板,则从所选函数模板的所有特化版本中选择最终调用的函数。注意:在重载决议过程中,并没有考虑模版函数特化。即
- 编译器首先进行重载决议,在所有主模板和普通函数中选择最佳匹配
- 只有当选中某个主模板后,才会检查该主模板是否有特化版本
- 特化版本本身不参与重载决议
template <typename T> void f(T); // (1): primary template
template <> void f(char*); // (2): explicit template specializtion of (1)
template <typename T> void f(T*); // (3): primary template
int main() {
char* cp{nullptr};
f(cp); // Calls function (3)
}
如上面例子所示,只有1和3两个主模板会参与重载决议,而3会1更匹配一些,因此最终挑选的是3。而2由于不参与重载决议,因此肯定不会被挑选。
可以对比下面的两个例子,加深理解:
template <typename T> void f(T); // (1): primary template
template <typename T> void f(T*); // (3): primary template
template <> void f(char*); // (2): explicit template specializtion of (2)
int main() {
char* cp{nullptr};
f(cp); // Calls function (2)
}
template <typename T> void f(T); // (1): primary template
template <typename T> void f(T*); // (3): primary template
template <> void f<char*>(char*); // (2): explicit template specializtion of (1)
int main() {
char* cp{nullptr};
f(cp); // Calls function (3)
}
Virtual Dispatch
当重载决议完成后,如果最佳匹配是一个类中的虚成员函数。编译器此时会确定使用虚函数表,确定对应虚函数在虚函数表的偏移量。最终生成代码是一个间接调用,即调用某个虚函数表中的第N个函数。而运行时根据变量实际的类型,决定使用哪个类的虚函数表。
Deleting Functions
到最后这步,此时best match已经完全确定,此时会检查被选中的函数是否被delete了。注意一个函数被标为delete,它仍然会参与重载决议。也就是说,best match可能是一个被标为delete的函数。一个函数完全没有被声明和被声明为delete的核心区别就是它是否参与重载决议。
void f(int); // (1)
void f(double) = delete; // (2)
int main() {
f(42); // Calls function (1)
f(1.0); // Compilation error: Call to deleted function
}
Reference
- Calling Functions: A Tutorial - Klaus Iglberger - CppCon 2020
- C++ Templates The Complete Guide, 2nd Edition
- CppCon 2014: Scott Meyers “Type Deduction and Why You Care”
- Overload resolution - cppreference.com