Distributed lock - part 1
最近看了一些关于分布式锁的文章,很有意思,进行一下总结梳理。今天这一篇,我们会聚焦于为什么需要分布式锁,分布式锁能够保证什么,以及常见的分布式锁实现方式。
Distributed lock
在单机多线程环境下,我们可以通过以下方式进行同步:
- 互斥锁mutex
- 信号量semaphore
- 用户态互斥锁futex
那如果在分布式环境下,需要处理资源抢占问题时,我们经常想到的就是分布式锁和一致性共识协议。事实上,分布式锁就是一个简化版的共识协议,我们可以从一个分布式锁需要保证的几个性质来理解这一点:
- Mutual exclusion: 同一个时刻只有一个客户端持有锁
- Deadlock free: 不会因为出现死锁,进而导致有客户端始终无法获取到锁的情况
- Fault tolerance: 一个分布式锁不能因为单点故障进而导致客户端始终无法获取到锁的情况
熟悉分布式系统的同学很快就能联想到,其实上面的三点本质上就是在描述两个重要性质:safety和liveness。其中safety对应低一点,liveness对应后两点。简单来说,safety是系统的invariant,无论何时系统都需要保证invariant成立。而liveness则是强调系统无论什么环境下,都要能最终保证其工作最终能够完成。
举个例子,著名的哲学家进餐的解决方法和分布式锁需要保证的safety和liveness性质如出一辙:
- safety: 因为叉子不能共享,一个正在吃饭的哲学家两侧的哲学家不能在同时吃饭。
- liveness: 没有哲学家会挨饿,也就是有限时间内饿了的哲学家都能吃上饭。
其实用TLA+来验证很多分布式算法时,验证的条件就是safety和liveness。我们后面会试着用TLA+来描述一个分布式锁的实现。
如果一个分布式锁能够保证safety和liveness,本质上就是一致性共识协议,也就是所有客户端通过分布式锁服务要能对当前谁持有锁达成共识。那为什么不直接用一致性共识协议呢?原因有以下几点:
- 一个完整的共识协议,比如Paxos和Raft,其工程实现难度会比一个分布式锁服务复杂很多。又或者说,我们可以基于共识协议来实现分布式锁,比如著名的ZooKeeper和etcd。他们暴露了相对容易使用的分布式锁接口,但其内部仍然是是使用Paxos或者Raft来达成共识。
- 上一点也提到,分布式锁的接口只关注于获取锁和释放锁,比一致性共识更加容易理解和使用。
- 一个分布式锁服务可以独立部署,并供多个业务使用。
分布式锁有几种常见的实现方式:
- 基于数据库的实现:不管是不是内存型数据库,都是往数据库中写入一条携带uuid或者自增id的记录。通过检查这条记录中的id信息是否和客户端匹配,进而获知自己是否上锁成功。
- 借助分布式应用程序协调服务:比如前面提到的ZooKeeper或者etcd,它们的客户端都提供了能够实现分布式锁的接口。
不同分布式协调服务的实现原理不尽相同,不在本文描述范围之内。本文重点还是关注基于数据库的实现,主要以Redis为例,整体思想大同小异。
选择Redis为例的一个重要原因是,关于Redis分布式锁在几年前有两个大牛也下场进行了一波争论。
基于单机数据库的实现方式
一种最简单的方式就是所有客户端,通过往数据库中写入一条记录表示获取锁,而删除掉这条记录就代表释放锁。当然获取锁的时候需要检查记录是否存在,比如通过IF NOT EXISTS这样的关键词。比如在Redis中就可以通过这样一条命令来完成,其中SETNX代表SET if Not eXists。
SETNX lock 1 // 1是客户端id
- 如果Redis中一开始没有lock这条记录,那么执行这条命令的客户端1就会成功写入lock,代表获取锁成功。此时就可以去对分布式锁保护的共享资源进行相应操作。
- 如果此时客户端2执行上锁逻辑就会返回失败,即获取锁失败。
- 当客户端1进行完相应操作后,通过
DEL lock删掉这条记录,代表释放锁。之后其他客户端就可以继续尝试写入lock获取锁。
如何避免锁不释放
上面的方案非常直观,但有一个明显的问题,如果客户端上锁成功之后没有释放,此后其他客户端都无法获取锁,违背了liveness性质。没有释放的情况很多:
- 应用程序忘了释放
- 客户端进程出现了stop-the-world的GC
- 客户端进程挂掉了,节点宕机,机房断电等等
想要解决这个问题,一个通常的做法就是对这个数据增加一个过期时间TTL(Time to Live)。当这个数据存活时间达到TTL之后,数据库就会自动将其删除,也就是锁自动释放。这个过期时间设置长短,需要考虑操作共享资源需要多长时间。比如在Redis中,我们可以对lock这条数据设置10秒的过期时间。
SETNX lock 1
EXPIRE lock 10
那么Redis能否保证这两个命令能原子完成呢?答案是否定的,也就会出现第一个命令成功,而第二个命令失败的情况,仍然会出现无法上锁成功的情况。Redis后来提供了原子的命令,保证两个操作能够原子执行。
// 下面的两个命令都等价于SETNX lock 1和EXPIRE lock 10
// 但能保证原子执行
SET lock 1 NX EX 10 // EX代表秒
SET lock 1 NX PX 10000 // PX代表毫秒
如何避免释放掉其他客户端上的锁
增加了TTL,就可能出现另一种问题:客户端1操作共享资源期间,由于各种原因,时间超过了TTL,此时Redis就会把客户端1上的锁释放。进而客户端2就会获取到锁,如果此时客户端1刚好操作完共享资源,开始释放锁,不就把客户端2的锁给释放了吗?
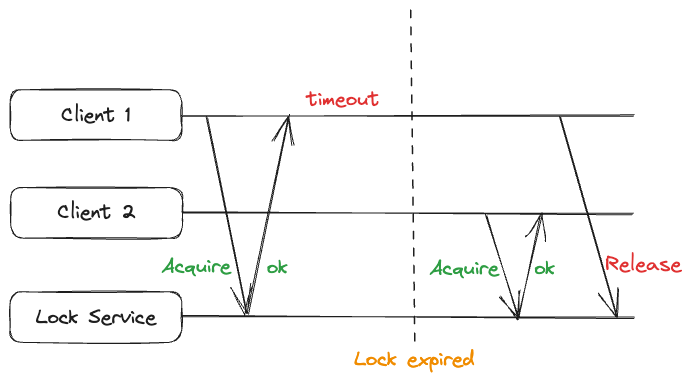
解决这个问题的关键就在于判断当前持有锁的客户端是不是自己。回顾以下我们获取锁的命令是SET lock 1 NX EX 10,其中1是客户端的id。之所以要把自身id写入到锁之中,就是为了在释放锁时检查持有锁的id。这是一个典型的read-modify-write操作,实际上就是要原子的执行如下伪代码:
If get(lock) == $id
del(lock)
然而Redis没有提供这样原子执行的命令,而是通过调用Lua脚本的形式可以保证原子性。
if redis.call("GET", KEYS[1]) == ARGV[1]
then
return redis.call("DEL", KEYS[1])
else
return 0
end
如果get和del不是原子执行的,也会出现违反safety的现象。到这里,一个基于单机数据库的分布式锁服务基本就完成了。然而,如果这个单机数据库发生了单点故障呢?这时候我们就只能将分布式锁服务替换成一个分布式服务了。
基于主从数据库的实现方式
如果我们基于主从数据库来实现一个分布式锁服务,最大的困难就在于主从复制是异步完成的。一种违背safety性质的情况如下:
- 客户端从主库获取锁成功
- 主库在复制分布式锁这条记录之前crash,此时从库中并没有相关记录
- 从库被升为主库,此时其他客户端就可以获取锁。此时就会有两个客户端都以为已经成果获取锁,因此可能同时操作共享资源。
基于数据库Quorum的实现方式
主从数据库作为分布式锁服务的最大问题在于,客户端每次只和其中一个数据库节点进行通信,而主从数据库之间是异步复制,导致主库和从库之间有可能没有对哪个客户端获取成功锁达成共识,进而导致违背互斥。
想要解决这个问题,首先我们仍然需要多个数据库节点,但客户端在上锁时要么直接和多个数据库同时通信,并获取其中大多数的授权。要么多个数据库之间有一个一致性共识协议,客户端每次只和leader节点通信,由leader节点负责确保大多数节点达成了共识,并告知客户端上锁成功。后一种方法,其实已经和ZooKeeper和Etcd非常接近了。
Redlock
Redis的作者后来基于Qruorum提出了Redlock这种分布式锁解决方案,这个方案有2个前提:
- 多个Redis都是主库,不使用从库和哨兵实例
- 主库要部署多个,官方推荐至少5个实例
Redlock的主要流程如下:
- 获取当前时间
T1,然后客户端依次对多个Redis实例进行加锁(方式和单个Redis上锁命令相同) - 为了避免在某个节点长时间获取不到锁而阻塞,每次获取锁操作也有一个timout,并且远小于锁的过期时间TTL。如果对单个节点获取锁的时间超过timeout则认为失败,立即向下一个节点获取锁
- 当往所有节点都发送加锁命令后并取得结果(无论结果是成功、失败还是超时),此时获取当前时间T2,获取多把锁的总消耗时间就是
T2 - T1。只有在超过半数节点都上锁成功,并且T2 - T1 < TTL,则认为成功获取锁。 - 如果在第3步获取锁成功,需要重新计算当前锁的有效时间,避免在锁过期之后仍然操作共享资源。即分布式锁最早失效时间
MIN_VALIDITY = 过期时间TTL - (T2 - T1)。如果考虑时钟漂移,那么MIN_VALIDITY = 过期时间TTL - (T2 - T1) - 时钟漂移。即在T2 - MIN_VALIDITY这段时间,客户端能够确保唯一持有分布式锁。当使用完共享资源后,也会向所有Redis实例发送释放锁的命令。 - 如果在第3步获取锁失败,要向所有Redis实例发送释放锁的命令。
我们可以结合Redlock是如何保证safety和liveness性质来理解这个方案。
Safety Arguments
分几种情况来看:
- 如果客户端用大于等于TTL的时间来对所有Redis节点进行上锁,此时第3步会检查失败,并开始向所有节点释放锁。此时客户端并没有获取锁成功,可能有其他客户端获取锁成功,不违背safety。
- 如果客户端用小于TTL的时间对所有Redis节点进行上锁,此时第3步会检查成功,认为该客户端获取分布式锁成功。此时是如何保证safety成立呢?
由于客户端至少向大多数的Redis节点成功写入了记录,因此成功写入的这些Redis节点保存的这条记录TTL相同(客户端上锁时指定的过期时间相同),而这些节点中这条记录的过期时间不尽相同(客户端往不同节点写入这条记录的时间不同)。
这里需要注意,客户端是从大多数Redis节点获取锁成功,有小部分Redis节点是可能超时或者获取锁失败的,我们也无需考虑。在这些成功写入的节点中,最早写入成功的时间Tmin一定大于T1(因为从T1之后才发送了请求),而最晚写入的时间Tmax一定小于T2(因为T2时刻已经获取到了所有节点加锁结果)。那么这个分布式锁最早失效的时间就是最早成功写入记录这个节点的失效时间(因为这个节点过期,可能就会导致不满足Quorum)。由于我们无法精确知道Tmin,我们可以转而使用T1来进行如下推导:
第一个写入成功的Redis节点这条记录的过期时间
= TTL + Tmin
> TTL + T1
> TTL - (T2 - T1)
> TTL - (T2 - T1) - CLOCK_DRIFT
= MIN_VALIDITY
由此得到分布式锁的最早失效时间MIN_VALIDITY = TTL - (T2 - T1) - CLOCK_DRIFT。在[T2, MIN_VALIDITY]这段时间之内,大多数节点的这条记录都没有过期。换句话说,其他客户端是不可能在这段时间之内往大多数节点写入这条记录,即不可能获取分布式锁。因此Redlock能够保证safety。
推导过程中要引入T2和时钟漂移的原因在于,客户端往所有节点写入记录的时间也需要记录在内。
Liveness Arguments
Liveness成立主要依赖以下三方面:
- Redis会根据本地时间进行过期锁的清理
- 客户端在获取锁失败或者获取成功并使用完资源后时,会往所有节点发送释放锁的命令
- 当客户端获取锁失败之后,会等待一段时间然后再重试(常见的back-off重试,避免并发场景下多个客户端始终无法获取Quorum)
由于有这几种清理和重试的机制,保证了多个Redis组成的分布式锁服务不会出现时钟无法获取分布式锁的情况。
不过Redis自己的官方文档中,描述了这样一种场景:如果每次客户端获取到分布式锁之后,在客户端向Redis发送释放锁的命令之前,客户端被网络隔离,在锁过期时间TTL之前,其他节点无法获取到分布式锁。如果网络时断时续这种情况一直出现,也就会导致整个分布式锁的可用性大大降低。
What if Redis crashed?
如果Redis没有开启任何持久化,当节点crash时,Redlock是否能满足safety呢?答案是否定的。比如一个客户端在ABCDE这5个节点中的ABCDE上锁成功,成功获取了分布式锁。如果此时A进程crash并重启,那么其他客户端就可以从ADE获取到同一个分布式锁。
想要完全避免这个问题,一种办法是每次Redis都需要把记录落盘,即开启fsync=always,性能肯定会大打折扣。另一种办法就是当Redis节点重启之后,只有经过一个TTL时间,才能对外服务。这样也就避免了A重启之后再次上锁成功的问题(因为之前的锁一定已经过期)。这个办法的缺点在于如果节点频繁重启,也会大大影响可用性。
然而,当Redlock提出之后,DDIA的作者Martin Kleppman就质疑了这个算法,后来Redis的作者Antirez也下场进行了反驳。两个人都是大牛,到底谁说的更有道理呢?我们在下一篇再继续。