Introduction to Aurora DSQL
介绍一下Amazon最新推出的Aurora DSQL~
Keynotes
- Aurora DSQL is a relational SQL database optimized for transactional workload.
- Scalable up and down.
- Serverless.
- Active-active, and multi-region.
- PostgreSQL compatiable.
Single-Region clusters
Aurora DSQL既能够在单个Region,也能够在多个Region中运行。单个Region架构下可以容忍AZ的异常,而多个Region架构可以容忍Region异常。我们先从单Region的架构看起,整个架构分为5层:
- Transaction and session router
- Query processor
- Adjudicator (下图中没有画出)
- Journal
- Storage
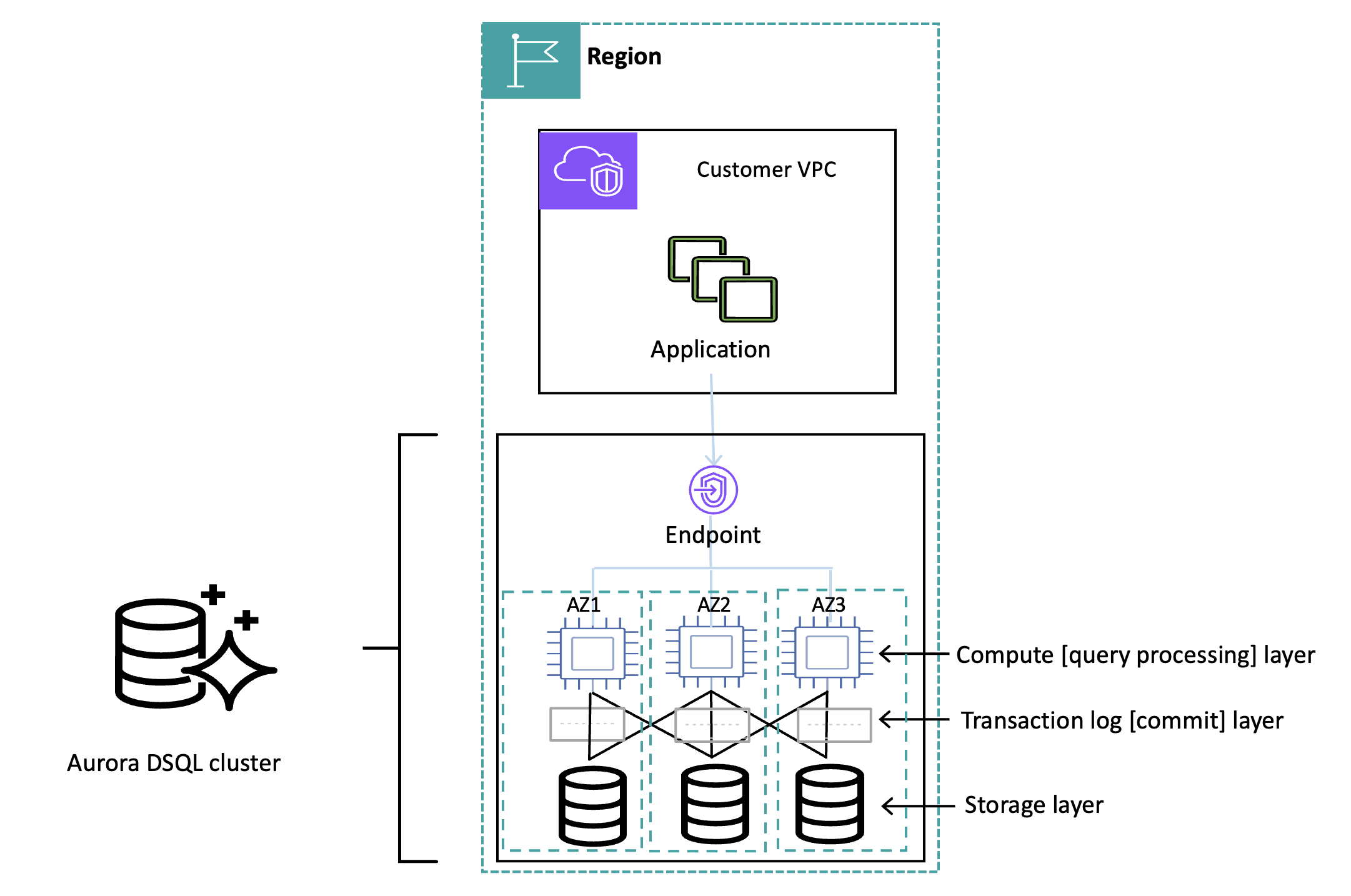
- 最上层是一个Endpoint接入层,主要负责路由用户请求、load balance等等。用户通过Endpoint接入Aurora DSQL进行事务操作。
-
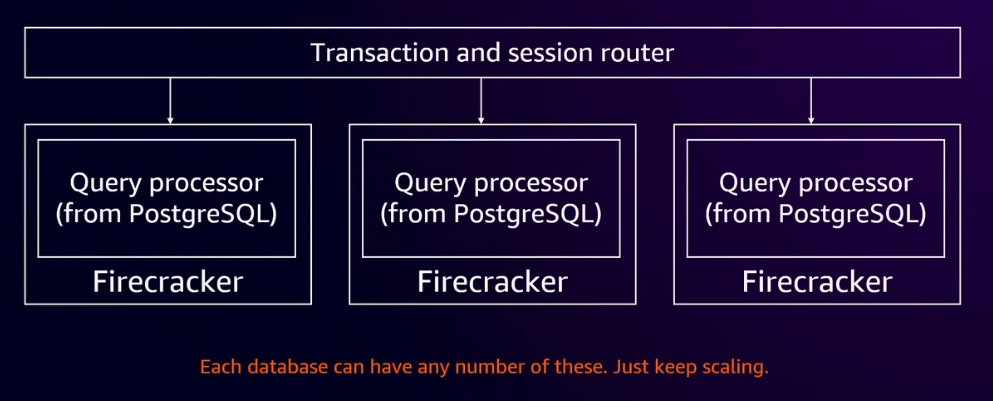
Query processor是查询层,负责解析query,生成、优化以及运行执行计划。每个Query processor运行在一个轻量的Firecracker容器中,以便serverless的启动和回收。Query processor之间没有任何通信,本身也无状态,能够进行水平扩展。
- Adjudicator:一个单独的服务,负责检查事务之间的冲突,并确定事务提交时间。它负责数据库的并发控制,定位和FoundationDB的resolver非常相似。Adjudicator也可以基于key space进行分片,从而水平扩展,它的分片方式可以和数据的分片方式不同。
- Journal:负责持久化数据。Aurora DSQL的所有数据都是写入到一个分布式的日志服务中,ACID中的atomicity和durability都是由这个日志服务保证的。这延续了Aurora中的一个核心思想:The log is the database。
- Storage:负责读取数据,本质上是Journal的一个索引,可以水平扩展。
理解这个架构的关键在于理解Journal和Storage这两层。“日志就是数据库”的设计思想能够极大简化数据库的各个组件,但这个思想对读取数据是非常不方便的。想象一下每次读取数据,都要从头到尾遍历整个日志,以获取最新的数据显然是不现实和低效的。在Aurora DSQL中,Journal进行数据的持久化,而Storage就是Journal的一个索引,它及时消费Journal中最新写入的数据,并转换为方便查询的数据结构。因此Storage本质上只需要记录上一次最新消费的日志点位,不断回放日志即可。
Storage能够按key space进行分片,每个分片负责索引一部分数据。另外也可以针对同一个分片的数据,创建多个Storage,多个Storage之间没有leadership,本质上他们都是Journal的消费者。
整体上看,Aurora DSQL的每一层都能够动态、独立的进行水平扩展。用户或者是云服务提供商可以根据workload,自动进行各个组件的scale up或者scale down。
这个架构并不新鲜,好几个数据库和论文中都能看到看到Aurora DSQL的缩影:FoundationDB,Calvin,Aurora等等。
Transaction workflow
这部分我们先看一下事务中的数据流,然后看一下每个事务的大致流程。
对于读来说,用户通过AZ Endpoint接入之后,将查询发送给Query Processor,它根据数据分片确定数据在哪个Storage中,即可完成查询。这个流程中不涉及Adjudicator和Journal。
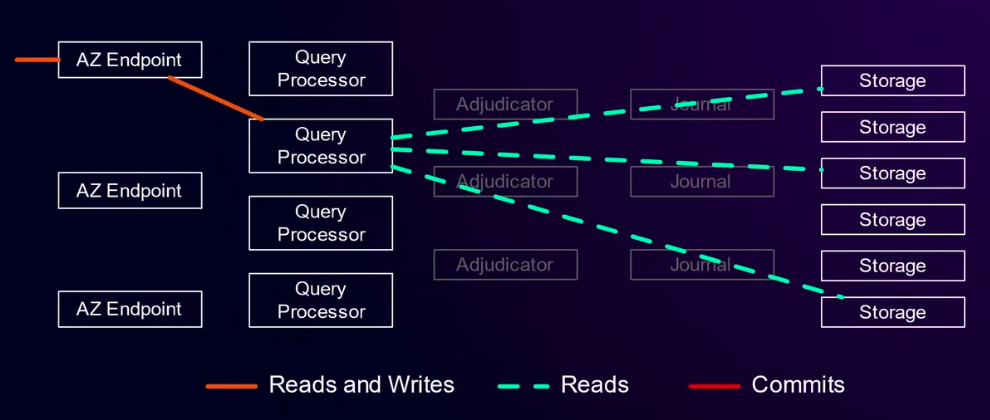
而在写中,Query Processor会确定需要写入的数据,然后提交给Adjudicator,由Adjudicator进行事务冲突检查。如果没有冲突,会确定一个事务提交时间,交给Journal。Journal完成持久化之后,Storage会获取日志中自己负责部分的最新改动,并应用到本地。
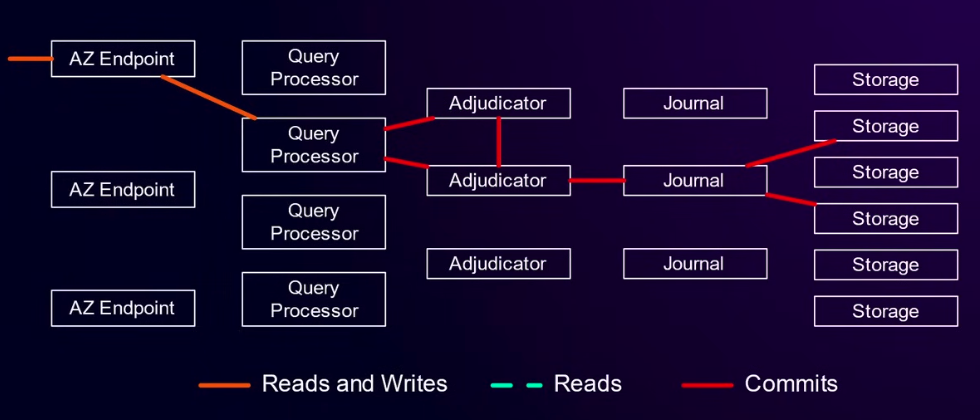
关于Storage是同步还是异步消费Journal,官方博客描述的是一个同步过程:In a single-Region configuration, Aurora DSQL commits all write transactions to a distributed transaction log and synchronously replicates all committed log data to user storage replicas in three AZs. 而在reinvent的演讲中,提到了给定时间t,去Storage读数据时可能会遇到读不到的情况,会自动重试。不过既然Aurora DSQL描述自己系统是Strong consistency,那么无论消费是同步还是异步,在用户视角肯定都需要保证能够读取到最新数据。
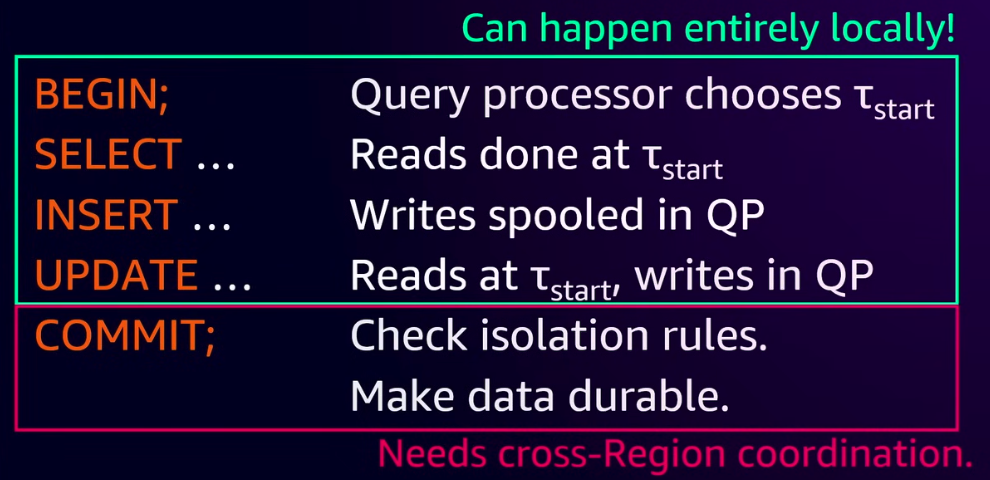
按Aurora DSQL的说法,它目前只提供了一种隔离级别Strong snapshot isolation,也就是PostgreSQL中的REPEATABLE READ。Strong snapshot isolation这个用词不太准确,实际上应该是snapshot isolation + strong consistency。Aurora DSQL的冲突检测是一个典型的OCC,事务的大致流程如下:

- 每个事务开始时,会从一个Time Sync Service获取一个事务开始时间,之后都用这个时间进行数据读取,保证所有数据都是从一个相同的快照获得。
- 所有的写入,都是read-modify-write,因此只需要在commit之前只需要缓存在Query Processor中既可以
- 在commit时,Query Processor将事务的读写集合提交给Adjudicator。Adjudicator会基于乐观冲突检测,完成以下事情
- 根据事务开始时间,以及写集合,检查是否有其他事务在事务开始时间之后写入了这些key
- 如果有,则commit失败,Query Processor进行回滚并返回Endpoint
- 如果没有,则确定一个事务提交时间
t。并保证之后写入这些数据的事务的提交时间一定不低于t。

可以看到它的冲突检测和FoundationDB非常相似,Adjudicator需要感知最近一段时间的事务分别写入了哪些数据,进行冲突检测,并确定事务提交时间。注意上图中有这样一句话,Never allow another conflicting transaction to pick a lower Tcommit,对于有冲突的事务,能够保证时间戳关系,那对于没有冲突的事务呢?按我的猜测是不保证时间戳关系的,也就是不能保证外部一致性。
一个事务的流程总结如下:

Multi-Region clusters
Aurora DSQL能够支持多个Region的部署形式:
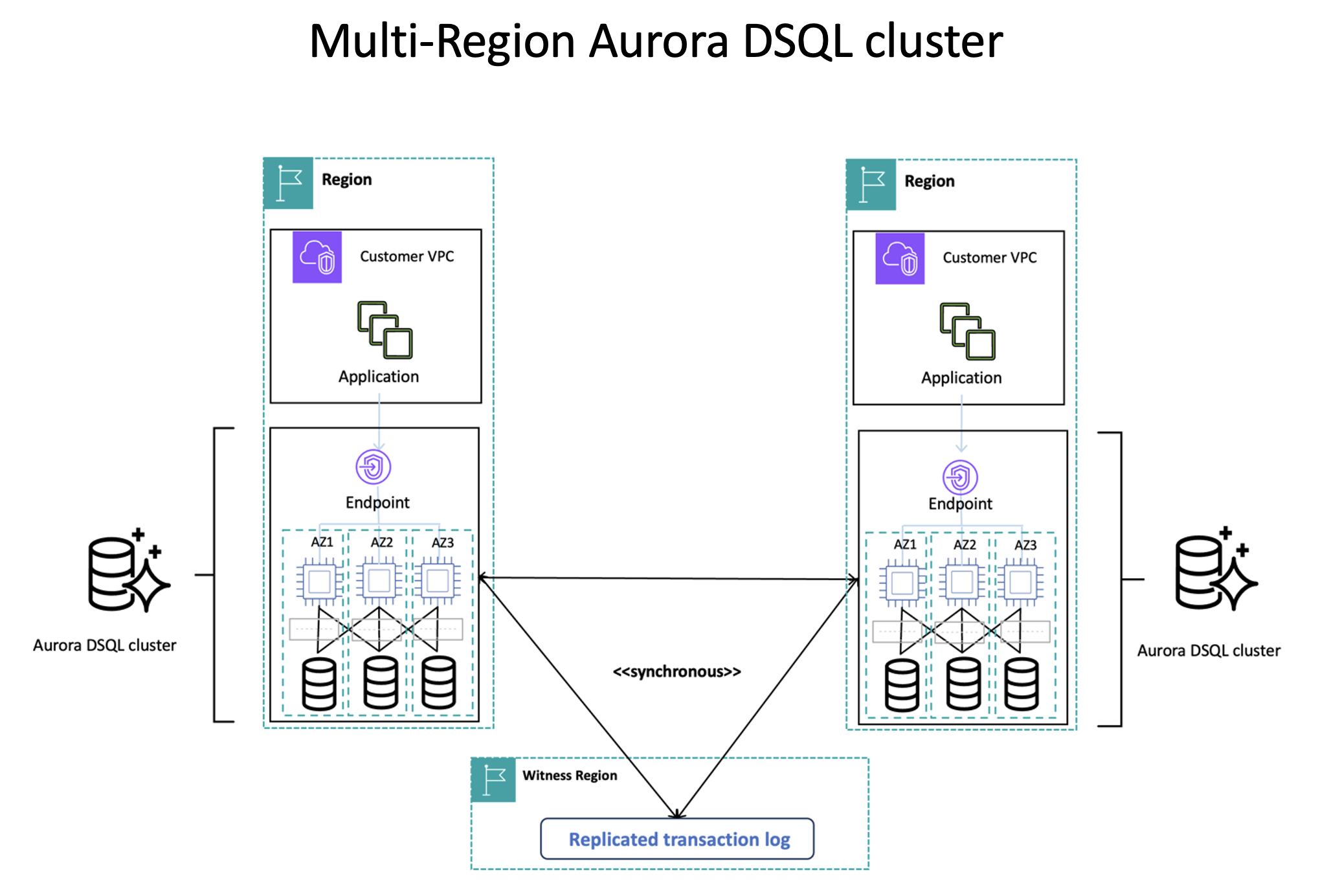
以两个Region为例,Aurora DSQL会添加一个Witness Region用来保证多数派。两个主要的Region通过各自的Endpoint接入,然后进行事务操作。Aurora DSQL描述为active-active,既多个Region都能进行数据写入,并能够保证强一致。我们简单看下是怎么做到这一点的:
首先对于一个事务来说,在所有commit之前的步骤都是可以在单个Region之内完成的,只有在commit的时候,需要进行跨Region的协调。这样可以避免很多其他geo-distributed数据库中,RTT时间过长的问题。
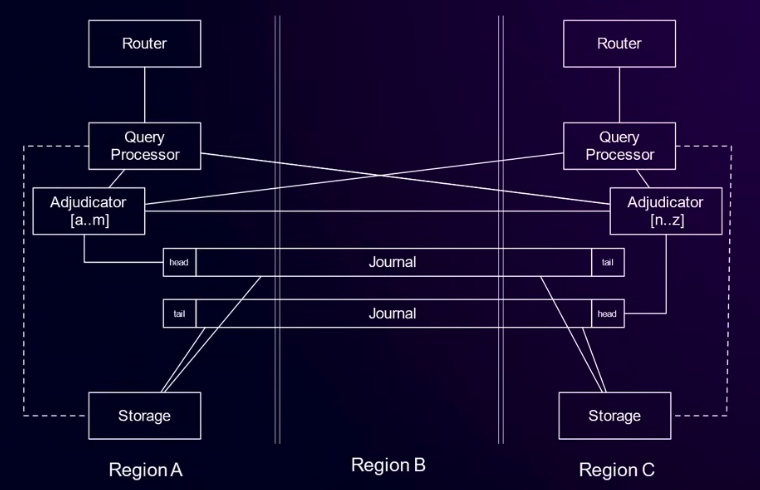
Aurora DSQL是通过Adjudicator之间的协调,保证数据的强一致的。我们结合下面这张图来理解:
- Region A和Region C提供了Endpoint用于接入
- Region B是witness region,只提供Journal用于保证日志多数派存活,即数据会写入到Region B的Journal中。实际部署下,B可能会在地理上更靠近A或者C一些,以保证写入的延迟不会太高。
- A和C中的Adjudicator在事务commit时,会进行协调。不过协调原理未知,应该是2PC的某个变种,否则无法保证关于事务提交时间的共识。
当C出现异常时,用户时无法通过C的Endpoint进行操作,而A一侧由于witness region B的存在,能够进行正常读写。注意此时原本处于C的Adjudicator都被调度到了A中。
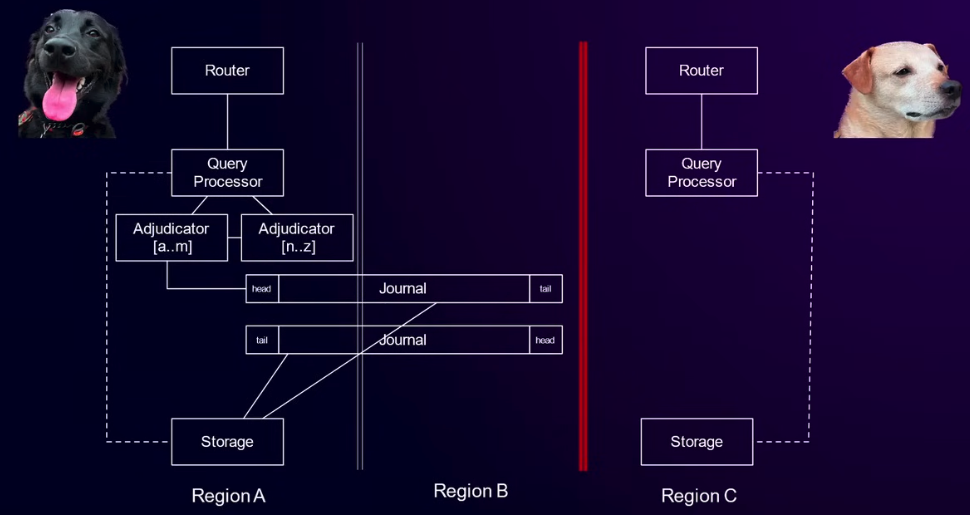
由此看,Aurora DSQL是一个CP系统。在发生Region故障时:
- 健康的Region中读路径没有任何改变,而写入只需多数派Journal成功即可
- Adjudicator需要移动到健康的Region中
- witness region保证了Journal的多数派存活
- 没有任何数据都是,但是异常Region无法再提供读写
到这Aurora DSQL大概就介绍完了,有点意思。
Reference
AWS re:Invent 2024 - Deep dive into Amazon Aurora DSQL and its architecture (DAT427-NEW)