Jemalloc 5.3.0 internals, part 1
Jemalloc 5.3.0这个版本在分层和概念与之前版本有不少出入,再加上之前研究的core_analyzer也能分析Jemalloc的page allocator,希望通过学习进一步加深理解。整个介绍会分成几篇,第一篇聚焦于用户层面的malloc以及Jemalloc的逻辑层。
简介
Jemalloc中各个层次的命名十分容易混乱,即便5.3.0的虽然做了一些简化,但新老版本的概念和命名完全不同,极其容易混淆。我只能尽可能自顶向下的介绍,尽可能减少理解成本。

当在用户空间执行malloc后,Jemalloc内部实际是有非常多层缓存的。缓存的引入,能够使malloc在每一层都有fast path和slow path,只有当fath path失败时,才会回退到slow path。多层缓存能够进一步减少对操作系统的直接内存申请,目前主流的malloc都是有多层缓存。
在Jemalloc中,一次malloc可能需要历经如下的层次tcache <- arena <- slab <- page allocator <- os:
首先是每个线程都有一个缓存称为tcache如果tcache仍有剩余空间,则直接从tcache分配。如果tcache分配失败,则需要从arena中获取一些内存,重新赋予tcache。同理,如果arena获取内存失败,则会向slab(也叫extent)层面获取内存以供arena使用。tcache、arena和slab这三层是逻辑层次,并不负责和操作系统进行交互。
所有的数据都是通过page allocator向内核申请内存获取的,它作为物理层负责实际管理操作系统的内存page。page allocator是一个接口,目前有两种实现:
- pac (page allocator classic)
- hpa (huge page allocator):这里不要被命名所误导,所谓的huge是指它能够管理操作系统的huge page。
我们这一篇先来看逻辑层,后续再详细分析page allocator。
核心概念和主路径
operator new
-> newImpl
-> imalloc_fastpath
-> malloc_default
-> imalloc
-> imalloc_body
-> imalloc_no_sample
-> iallocztm
-> arena_malloc
-> tcache_alloc_small
-> tcache_alloc_large
-> arena_malloc_hard
我们先看下主路径,从new开始,最终落到三个函数tcache_alloc_small、tcache_alloc_large和arena_malloc_hard:
void *arena_malloc(tsdn_t *tsdn,
arena_t *arena,
size_t size,
szind_t ind,
bool zero,
tcache_t *tcache,
bool slow_path) {
assert(!tsdn_null(tsdn) || tcache == NULL);
if (likely(tcache != NULL)) {
if (likely(size <= SC_SMALL_MAXCLASS)) {
return tcache_alloc_small(
tsdn_tsd(tsdn), arena, tcache, size, ind, zero, slow_path);
}
if (likely(size <= tcache_maxclass)) {
return tcache_alloc_large(
tsdn_tsd(tsdn), arena, tcache, size, ind, zero, slow_path);
}
/* (size > tcache_maxclass) case falls through. */
assert(size > tcache_maxclass);
}
return arena_malloc_hard(tsdn, arena, size, ind, zero);
}
在我的环境下,SC_SMALL_MAXCLASS为14336,tcache_maxclass为32768。即大小在[0, 14336]为small,大小在[14337, 32768]为large,大于32K 的不会走tcache。对于small和large对象,都是统一通过page allocator向操作系统获取一个page或者huge page之后,将其按extent划分,最终赋给一个slab来进行分配和管理的。
size class & bin
和主流的malloc一样,jemalloc在分配内存时候是会有一些内存碎片的。比如malloc(10)时,实际会在jemalloc中会分配16个字节的内存。即用户指定的内存大小可能会被round up到一个稍大一点的size class。
不同size class的对象是由不同的slab负责分配的,但在前面的图中我们可以看到,slab处于逻辑层和物理层的交界处,用户的malloc是不会直接和slab打交道的。那么是如何管理用户不同大小的内存分配和slab之间的映射关系呢?
注意在Jemalloc 5.3.0中已经没有之前版本的huge class,只有small class和large class。
这里又会引入一个新的概念bin:每个线程都有一个固定大小的bin数组,当用户进行内存分配时,首先查表获取对应的size class大小,获取到在bin数组中的下标,然后就能通过数组找到对应的bin,最终就可以获取到bin中的slab进行内存分配。需要注意的是,逻辑层的tcache和arena中分别有不同的bin数据结构:tcache中是cache_bin_t,实际是个栈;arena中则是bin_t,通过其内部的链表和堆管理slab。二者也是一个缓存关系,优先使用tcache中的bin,分配失败则从arena中的bin进行reill。
求size class以及bin下标的代码如下:先根据用户传入的size,调用sz_size2index将下标保存到ind中,然后调用sz_index2size进行查表,根据下标获取对应size class保存到usize中。
注意不同环境下的size class是不同的,因此没有什么可比性
bool aligned_usize_get(size_t size,
size_t alignment,
size_t *usize,
szind_t *ind,
bool bump_empty_aligned_alloc) {
assert(usize != NULL);
if (alignment == 0) {
if (ind != NULL) {
*ind = sz_size2index(size);
if (unlikely(*ind >= SC_NSIZES)) {
return true;
}
*usize = sz_index2size(*ind);
assert(*usize > 0 && *usize <= SC_LARGE_MAXCLASS);
return false;
}
*usize = sz_s2u(size);
} else {
if (bump_empty_aligned_alloc && unlikely(size == 0)) {
size = 1;
}
*usize = sz_sa2u(size, alignment);
}
if (unlikely(*usize == 0 || *usize > SC_LARGE_MAXCLASS)) {
return true;
}
return false;
}
我们简单总结一下逻辑层,它分为tcache、arena和slab。当用户申请内存分配时:
- 根据申请大小,求出size class以及bin的下标
- tache根据下标找到对应cache bin,尝试使用cache bin进行内存分配,如果失败,回退到arena进行refill,可以理解为重新初始化一个tcache
- arena根据下标找到对应的bin,通过bin中的slab进行refill tcache,最终重新使用tcache进行内存分配
这里补充几点:small class对应bin下标更小。small class的bin下标对应范围是
[0, SC_NBINS),SC_NBINS中的SC可能是small class的缩写,而 large class的bin下标范围是[SC_NBINS, nhbins)。
接下来我们会结合代码详细解释不同size class的内存是如何分配的。
tcache_alloc_small
对于small class其主要逻辑是:
- 首先在线程对应的tcache中检查是否能分配,即
cache_bin_alloc - 如果tcache不能分配,需要让tcache从arena中进行补充:
- 在
arena_choose选择对应的arena,这里是根据tsd,即thread specific data来进行选择的 - 如果tcache没有启用,直接退回到
arena_malloc_hard - 如果tcache启用,然后通过arena完成refill tcache,最后在
tcache_alloc_small_hard中完成分配
- 在
void *tcache_alloc_small(tsd_t *tsd,
arena_t *arena,
tcache_t *tcache,
size_t size,
szind_t binind,
bool zero,
bool slow_path) {
void *ret;
bool tcache_success;
assert(binind < SC_NBINS);
cache_bin_t *bin = &tcache->bins[binind];
ret = cache_bin_alloc(bin, &tcache_success);
assert(tcache_success == (ret != NULL));
if (unlikely(!tcache_success)) {
bool tcache_hard_success;
arena = arena_choose(tsd, arena);
if (unlikely(arena == NULL)) {
return NULL;
}
if (unlikely(tcache_small_bin_disabled(binind, bin))) {
/* stats and zero are handled directly by the arena. */
return arena_malloc_hard(tsd_tsdn(tsd), arena, size, binind, zero);
}
tcache_bin_flush_stashed(tsd,
tcache,
bin,
binind,
/* is_small */ true);
ret = tcache_alloc_small_hard(
tsd_tsdn(tsd), arena, tcache, bin, binind, &tcache_hard_success);
if (tcache_hard_success == false) {
return NULL;
}
}
assert(ret);
if (unlikely(zero)) {
size_t usize = sz_index2size(binind);
assert(tcache_salloc(tsd_tsdn(tsd), ret) == usize);
memset(ret, 0, usize);
}
if (config_stats) {
bin->tstats.nrequests++;
}
return ret;
}
我们分成几部分进行理解:tcache,arena,以及arena和tcache如何交互。
tcache
首先会尝试从tcache中分配,tcache是thread cache缩写,调用路径如下
tcache_alloc_small
-> cache_bin_alloc
-> cache_bin_alloc_impl
tcache中有多个cache_bin,一个tcache对应一个线程。
struct tcache_s {
tcache_slow_t *tcache_slow;
cache_bin_t bins[TCACHE_NBINS_MAX];
};
其核心数据结构是cache_bin_s,即cache_bin_t,其核心作用是用于tcache和arena之间交互。
The cache_bins are the mechanism that the tcache and the arena use to communicate. The tcache fills from and flushes to the arena by passing a cache_bin_t to fill/flush.
/*
* Responsible for caching allocations associated with a single size.
*
* Several pointers are used to track the stack. To save on metadata bytes,
* only the stack_head is a full sized pointer (which is dereferenced on the
* fastpath), while the others store only the low 16 bits -- this is correct
* because a single stack never takes more space than 2^16 bytes, and at the
* same time only equality checks are performed on the low bits.
*
* (low addr) (high addr)
* |------stashed------|------available------|------cached-----|
* ^ ^ ^ ^
* low_bound(derived) low_bits_full stack_head low_bits_empty
*/
typedef struct cache_bin_s cache_bin_t;
struct cache_bin_s {
void **stack_head;
cache_bin_stats_t tstats;
uint16_t low_bits_low_water;
uint16_t low_bits_full;
uint16_t low_bits_empty;
};
cache_bin_s维护同一大小的若干对象,本质上是一个有容量大小限制的栈,[low_bits_full, low_bits_empty)范围内的地址是合法地址。
- 栈为空时,
stack_head指向low_bits_empty - 分配对象时,
stack_head往low_bits_full的方向移动 - 当栈非空时,
stack_head指向地址最低的一个对象地址
上面代码注释里的low addr和high addr疑似有问题,代码中我看
stack_head分配时是往高地址方向移动,而free时则是往低地址移动。
tcache中分配内存和释放内存的代码如下:
// alloc
void* cache_bin_alloc_impl(cache_bin_t *bin, bool *success, bool adjust_low_water) {
/*
* success (instead of ret) should be checked upon the return of this
* function. We avoid checking (ret == NULL) because there is never a
* null stored on the avail stack (which is unknown to the compiler),
* and eagerly checking ret would cause pipeline stall (waiting for the
* cacheline).
*/
/*
* This may read from the empty position; however the loaded value won't
* be used. It's safe because the stack has one more slot reserved.
*/
void *ret = *bin->stack_head;
uint16_t low_bits = (uint16_t)(uintptr_t)bin->stack_head;
void **new_head = bin->stack_head + 1;
/*
* Note that the low water mark is at most empty; if we pass this check,
* we know we're non-empty.
*/
if (likely(low_bits != bin->low_bits_low_water)) {
bin->stack_head = new_head;
*success = true;
return ret;
}
if (!adjust_low_water) {
*success = false;
return NULL;
}
/*
* In the fast-path case where we call alloc_easy and then alloc, the
* previous checking and computation is optimized away -- we didn't
* actually commit any of our operations.
*/
if (likely(low_bits != bin->low_bits_empty)) {
bin->stack_head = new_head;
bin->low_bits_low_water = (uint16_t)(uintptr_t)new_head;
*success = true;
return ret;
}
*success = false;
return NULL;
}
// dealloc
bool cache_bin_dalloc_easy(cache_bin_t* bin, void* ptr) {
if (unlikely(cache_bin_full(bin))) {
return false;
}
bin->stack_head--;
*bin->stack_head = ptr;
cache_bin_assert_earlier(bin, bin->low_bits_full, (uint16_t)(uintptr_t)bin->stack_head);
return true;
}
refill tcache
如果当前tcache分配失败,则需要从arena中重新refill一个tcache,最终在新的tcache进行内存分配:
tcache_alloc_small
-> tcache_alloc_small_hard
-> arena_cache_bin_fill_small
-> cache_bin_alloc
主要步骤如下:
cache_bin_info_ncached_max计算需要refill多少内存nfill- 调用
arena_cache_bin_fill_small,从arena中refill tcache - 此时
cache_bin已经重新生效,重新调用cache_bin_alloc进行内存分配 (第一次调用cache_bin_alloc是在tcache_alloc_small中)
void *tcache_alloc_small_hard(tsdn_t *tsdn,
arena_t *arena,
tcache_t *tcache,
cache_bin_t *cache_bin,
szind_t binind,
bool *tcache_success) {
tcache_slow_t *tcache_slow = tcache->tcache_slow;
void *ret;
assert(tcache_slow->arena != NULL);
unsigned nfill = cache_bin_info_ncached_max(&tcache_bin_info[binind]) >>
tcache_slow->lg_fill_div[binind];
arena_cache_bin_fill_small(tsdn, arena, cache_bin, &tcache_bin_info[binind], binind, nfill);
tcache_slow->bin_refilled[binind] = true;
ret = cache_bin_alloc(cache_bin, tcache_success);
return ret;
}
对应函数参数含义:
tsdn: thread specific dataarena: 从哪个arena补充tcache: 对应哪个tcachecache_bin: 对应tcache中的某个cache_binbinind: 是bin的索引,用于从tcache_bin_info中获取对应的bin_infotcache_success: 用于返回是否成功
arena_cache_bin_fill_small
small allocation最复杂的一步就是从arena refill tcache。首先会在arena_bin_choose中获取arena对应的bin,然后从bin中refill到tcache中。bin的数据结构如下:
在Jemalloc 5.3.0中,slab或者extent对应代码中的edata,指bin中用于分配相同大小对象的一个数据结构。
typedef struct bin_s bin_t;
struct bin_s {
malloc_mutex_t lock;
bin_stats_t stats;
/*
* Current slab being used to service allocations of this bin's size
* class. slabcur is independent of slabs_{nonfull,full}; whenever
* slabcur is reassigned, the previous slab must be deallocated or
* inserted into slabs_{nonfull,full}.
*/
edata_t *slabcur;
edata_heap_t slabs_nonfull;
edata_list_active_t slabs_full;
};
slabcur指向当前用来分配内存的slabslabs_nonfull是一个最小堆,每次slabcur分配失败时,就会将slabcur保存到slabs_full中,并从slabs_nonfull中取地址最低的slab用于后续分配slabs_full则用于保存所有已经分配满的slab
这几个成员之间的转换关系如下所示:
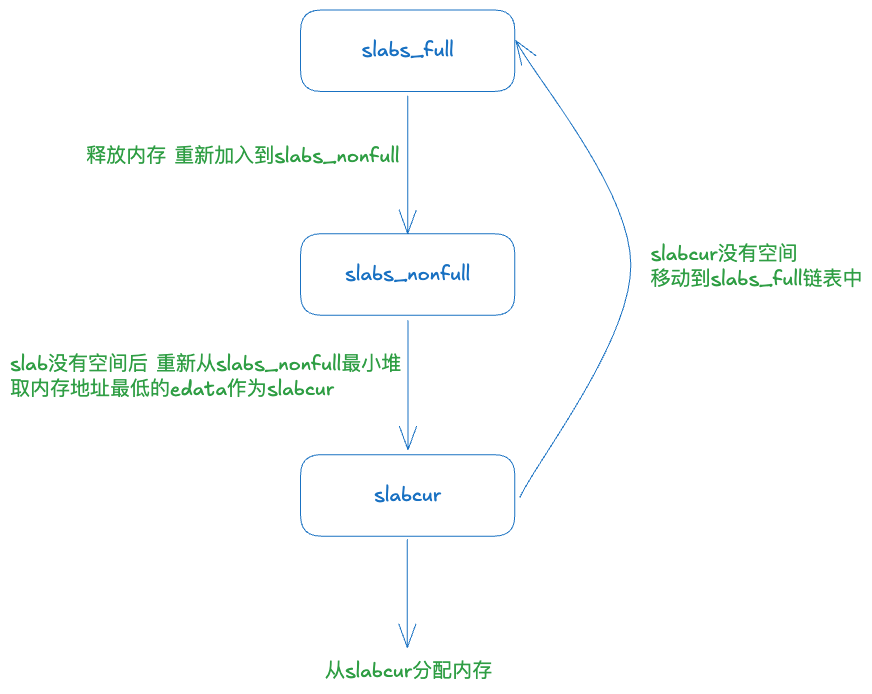
refill的核心逻辑就是一直循环直到获取到足够多空间:
- 先尝试使用
slabcur进行refill。(arena_slab_reg_alloc_batch) - 如果
slabcur空间不够,则需要从slabs_nonfull中取一个slab,并设置为slabcur。(arena_bin_refill_slabcur_no_fresh_slab) - 如果
slabs_nonfull也为空,此时需要获取一个新的slab,此时有两个选择:- 如果
fresh_slab不为空,代表之前分配过一个新的slab,将fresh_slab设置为slabcur,之后会重新走上述流程。(arena_bin_refill_slabcur_with_fresh_slab) - 如果
fresh_slab为空,需要通过arena_slab_alloc分配一个新的slab,设置为fresh_slab,之后会重新走上述流程。
- 如果
-
从
slabs_nonfull最小堆中获取一个空的slab,然后设置为slabcur的代码实现如下static bool arena_bin_refill_slabcur_no_fresh_slab(tsdn_t *tsdn, arena_t *arena, bin_t *bin) { malloc_mutex_assert_owner(tsdn, &bin->lock); /* Only called after arena_slab_reg_alloc[_batch] failed. */ assert(bin->slabcur == NULL || edata_nfree_get(bin->slabcur) == 0); if (bin->slabcur != NULL) { arena_bin_slabs_full_insert(arena, bin, bin->slabcur); } /* Look for a usable slab. */ bin->slabcur = arena_bin_slabs_nonfull_tryget(bin); assert(bin->slabcur == NULL || edata_nfree_get(bin->slabcur) > 0); return (bin->slabcur == NULL); } static edata_t *arena_bin_slabs_nonfull_tryget(bin_t *bin) { edata_t *slab = edata_heap_remove_first(&bin->slabs_nonfull); if (slab == NULL) { return NULL; } if (config_stats) { bin->stats.reslabs++; bin->stats.nonfull_slabs--; } return slab; } -
分配一个新的slab的代码如下,最终调用
pa_alloc。pa 是page allocator的缩写,对应代码在pa.h中,这部分我们在下一篇文章再展开。static edata_t *arena_slab_alloc(tsdn_t *tsdn, arena_t *arena, szind_t binind, unsigned binshard, const bin_info_t *bin_info) { bool deferred_work_generated = false; witness_assert_depth_to_rank(tsdn_witness_tsdp_get(tsdn), WITNESS_RANK_CORE, 0); bool guarded = san_slab_extent_decide_guard(tsdn, arena_get_ehooks(arena)); edata_t *slab = pa_alloc(tsdn, &arena->pa_shard, bin_info->slab_size, /* alignment */ PAGE, /* slab */ true, /* szind */ binind, /* zero */ false, guarded, &deferred_work_generated); if (deferred_work_generated) { arena_handle_deferred_work(tsdn, arena); } if (slab == NULL) { return NULL; } assert(edata_slab_get(slab)); /* Initialize slab internals. */ slab_data_t *slab_data = edata_slab_data_get(slab); edata_nfree_binshard_set(slab, bin_info->nregs, binshard); bitmap_init(slab_data->bitmap, &bin_info->bitmap_info, false); return slab; } -
从新分配的fresh_slab中refill的相关代码如下
static void arena_bin_refill_slabcur_with_fresh_slab( tsdn_t *tsdn, arena_t *arena, bin_t *bin, szind_t binind, edata_t *fresh_slab) { malloc_mutex_assert_owner(tsdn, &bin->lock); /* Only called after slabcur and nonfull both failed. */ assert(bin->slabcur == NULL); assert(edata_heap_first(&bin->slabs_nonfull) == NULL); assert(fresh_slab != NULL); /* A new slab from arena_slab_alloc() */ assert(edata_nfree_get(fresh_slab) == bin_infos[binind].nregs); if (config_stats) { bin->stats.nslabs++; bin->stats.curslabs++; } bin->slabcur = fresh_slab; }
tcache_alloc_large
large class流程和tcache_alloc_small非常类似
- 首先在线程对应的tcache中检查是否能分配,即
cache_bin_alloc - 如果tcache不能分配,需要让tcache从arena中进行补充:
- 在
arena_choose选择对应的arena - 然后通过arena完成refill tcache,最后在
large_malloc中分配
- 在
前面的部分和small class完全相同,我们只看large_malloc的逻辑:
void *large_malloc(tsdn_t *tsdn, arena_t *arena, size_t usize, bool zero) {
assert(usize == sz_s2u(usize));
return large_palloc(tsdn, arena, usize, CACHELINE, zero);
}
void *large_palloc(tsdn_t *tsdn, arena_t *arena, size_t usize, size_t alignment, bool zero) {
size_t ausize;
edata_t *edata;
UNUSED bool idump JEMALLOC_CC_SILENCE_INIT(false);
assert(!tsdn_null(tsdn) || arena != NULL);
ausize = sz_sa2u(usize, alignment);
if (unlikely(ausize == 0 || ausize > SC_LARGE_MAXCLASS)) {
return NULL;
}
if (likely(!tsdn_null(tsdn))) {
arena = arena_choose_maybe_huge(tsdn_tsd(tsdn), arena, usize);
}
if (unlikely(arena == NULL) ||
(edata = arena_extent_alloc_large(tsdn, arena, usize, alignment, zero)) == NULL) {
return NULL;
}
/* See comments in arena_bin_slabs_full_insert(). */
if (!arena_is_auto(arena)) {
/* Insert edata into large. */
malloc_mutex_lock(tsdn, &arena->large_mtx);
edata_list_active_append(&arena->large, edata);
malloc_mutex_unlock(tsdn, &arena->large_mtx);
}
arena_decay_tick(tsdn, arena);
return edata_addr_get(edata);
}
- 在
arena_choose_maybe_huge中挑选arena - 通过arena来获取一个edata,实际上也是在
arena_extent_alloc_large中调用了pa_alloc。 - 保存edata,注意对于small class会将获取的edata赋值给bin中的
slabcur,而对large class则是调用edata_list_active_append,将这个edata添加到arena的large这个链表中。
所以对于large class来说,每个arena中只有一个edata链表用来保存large class对象,其余部分和small class基本相同。
arena_malloc_hard
最后就是大块内存如何分配:
void *arena_malloc_hard(tsdn_t *tsdn, arena_t *arena, size_t size, szind_t ind, bool zero) {
assert(!tsdn_null(tsdn) || arena != NULL);
if (likely(!tsdn_null(tsdn))) {
arena = arena_choose_maybe_huge(tsdn_tsd(tsdn), arena, size);
}
if (unlikely(arena == NULL)) {
return NULL;
}
if (likely(size <= SC_SMALL_MAXCLASS)) {
return arena_malloc_small(tsdn, arena, ind, zero);
}
return large_malloc(tsdn, arena, sz_index2size(ind), zero);
}
- 首先在
arena_choose_maybe_huge中挑选arena - 如果分配内存小于
SC_SMALL_MAXCLASS,调用arena_malloc_small进行分配,这一步和和arena refill tcache的流程有些类似- 首先在
arena_bin_choose中获取arena对应的bin - 然后在
arena_bin_malloc_no_fresh_slab中设置bin中的slabcur - 最终在
arena_bin_malloc_with_fresh_slab通过slabcur进行内存分配
- 首先在
- 否则调用
large_malloc(和large class中的流程,不再重复介绍)
static void *arena_malloc_small(tsdn_t *tsdn, arena_t *arena, szind_t binind, bool zero) {
assert(binind < SC_NBINS);
const bin_info_t *bin_info = &bin_infos[binind];
size_t usize = sz_index2size(binind);
unsigned binshard;
bin_t *bin = arena_bin_choose(tsdn, arena, binind, &binshard);
malloc_mutex_lock(tsdn, &bin->lock);
edata_t *fresh_slab = NULL;
void *ret = arena_bin_malloc_no_fresh_slab(tsdn, arena, bin, binind);
if (ret == NULL) {
malloc_mutex_unlock(tsdn, &bin->lock);
/******************************/
fresh_slab = arena_slab_alloc(tsdn, arena, binind, binshard, bin_info);
/********************************/
malloc_mutex_lock(tsdn, &bin->lock);
/* Retry since the lock was dropped. */
ret = arena_bin_malloc_no_fresh_slab(tsdn, arena, bin, binind);
if (ret == NULL) {
if (fresh_slab == NULL) {
/* OOM */
malloc_mutex_unlock(tsdn, &bin->lock);
return NULL;
}
ret = arena_bin_malloc_with_fresh_slab(tsdn, arena, bin, binind, fresh_slab);
fresh_slab = NULL;
}
}
if (config_stats) {
bin->stats.nmalloc++;
bin->stats.nrequests++;
bin->stats.curregs++;
}
malloc_mutex_unlock(tsdn, &bin->lock);
if (fresh_slab != NULL) {
arena_slab_dalloc(tsdn, arena, fresh_slab);
}
if (zero) {
memset(ret, 0, usize);
}
arena_decay_tick(tsdn, arena);
return ret;
}
到这里Jemalloc的逻辑层已经介绍完了,后面会继续挖物理层。