explore x86_64 main(), part 2
在上一篇,我们已经了解了内核和ld.so在运行一个可执行文件中的作用,并且已经成功跳转到了可执行文件的入口_start。这一篇会继续探索,看看从_start开始最终怎么调用到main函数。
__libc_start_main
首先我们简单回顾一下:在glibc2.39和动态链接环境下,_start仍然是用户程序的入口。但由于ld.so已经进行了很多工作,可执行文件的__libc_start_main负责的工作比老版本的glibc少了很多:
- 注册
ld.so的退出函数rtld_fini - 通过
call_init调用全局构造函数 - 通过
__libc_start_call_main,进而调用main函数
全局对象的构造
我们用CppCon中的例子为例,看看C++中的全局对象和静态对象是什么时候构造的。
#include <iostream>
struct Foo {
static int numFoos;
Foo() {
numFoos++;
}
~Foo() {
numFoos--;
}
};
int Foo::numFoos;
Foo globalFoo;
int main() {
std::cout << "numFoos = " << Foo::numFoos << "\n";
}
$ g++ -O0 -ggdb -o global global.cpp
在入口处打断点时,我们发现此时Foo::numFoos为0,也就是说这时候全局对象还没构造
(gdb) b _start
Breakpoint 1 at 0x401090
(gdb) r
Starting program: /home/doodle.wang/code/main-cpp/global
Breakpoint 1.2, 0x00007ffff7fe4540 in _start () from /lib64/ld-linux-x86-64.so.2
(gdb) p Foo::numFoos
$1 = 0
我们通过watch -l来检查什么时候Foo::numFoos会发生变化:
(gdb) p &Foo::numFoos
$2 = (int *) 0x404154 <Foo::numFoos>
(gdb) watch -l *0x404154
Hardware watchpoint 2: -location *0x404154
(gdb) c
Continuing.
Hardware watchpoint 2: -location *0x404154
Old value = 0
New value = 1
Foo::Foo (this=0x404158 <globalFoo>) at global.cpp:7
7 }
(gdb) bt
#0 Foo::Foo (this=0x404158 <globalFoo>) at global.cpp:7
#1 0x00000000004011dd in __static_initialization_and_destruction_0 () at global.cpp:14
#2 0x0000000000401210 in _GLOBAL__sub_I__ZN3Foo7numFoosE () at global.cpp:18
#3 0x00007ffff782a304 in call_init (env=<optimized out>, argv=0x7fffffffe1c8, argc=1) at ../csu/libc-start.c:145
#4 __libc_start_main_impl (main=0x401176 <main()>, argc=1, argv=0x7fffffffe1c8, init=<optimized out>, fini=<optimized out>, rtld_fini=<optimized out>,
stack_end=0x7fffffffe1b8) at ../csu/libc-start.c:347
#5 0x00000000004010b5 in _start ()
此时main函数还没有执行,准确来说,是在_start和main函数之间,由call_init调用了全局对象的构造函数,对应代码如下:
/* Initialization for dynamic executables. Find the main executable
link map and run its init functions. */
static void call_init(int argc, char** argv, char** env) {
/* Obtain the main map of the executable. */
struct link_map* l = GL(dl_ns)[LM_ID_BASE]._ns_loaded;
/* DT_PREINIT_ARRAY is not processed here. It is already handled in
_dl_init in elf/dl-init.c. Also see the call_init function in
the same file. */
if (ELF_INITFINI && l->l_info[DT_INIT] != NULL)
DL_CALL_DT_INIT(l, l->l_addr + l->l_info[DT_INIT]->d_un.d_ptr, argc, argv, env);
ElfW(Dyn)* init_array = l->l_info[DT_INIT_ARRAY];
if (init_array != NULL) {
unsigned int jm = l->l_info[DT_INIT_ARRAYSZ]->d_un.d_val / sizeof(ElfW(Addr));
ElfW(Addr)* addrs = (void*)(init_array->d_un.d_ptr + l->l_addr);
for (unsigned int j = 0; j < jm; ++j)
// 在下面这行执行了相应的全局对象构造
((dl_init_t)addrs[j])(argc, argv, env);
}
}
从代码中可以发现,call_init本质上是读取了一堆函数指针,然后将argc、argv和env作为参数,调用了函数指针指向的函数,那么这些函数指针是由谁在什么时候准备好的呢?
另外,从
call_init可以看出来,初始化的时候是依次调用每个动态链接库的.init段和.init_array段。准确说是根据依赖关系进行遍历,然后依次进行 动态链接库1的.init→ 动态链接库1的.init_array→ 动态链接库2的.init→ 动态链接库2的.init_array… → 主程序的.init→ 主程序的.init_array→main()
大致原理如下:
- 编译器会为将每个全局对象的构造函数的地址会被放入每个object文件中的
.init_array段。 - 链接器会收集所有object文件中的
.init_array段,并合并到最终ELF文件中的.init_array段,并且生成DT_INIT_ARRAY(函数指针数组的起始地址)和DT_INIT_ARRAYSZ(函数指针数组的字节数),二者可以确定需要执行多少个初始化函数。 ld.so会在加载阶段,将.init_array中的函数指针进行重定位,并填入到link_map的l_info[DT_INIT_ARRAY]和l_info[DT_INIT_ARRAYSZ]中。- 在
main函数之前,也就上面的call_init中,会执行这些初始化函数。
链接器合并.init_array的部分就像Cppcon的演讲中那样,在binutils的ld/scripttempl/elf.sc中有这样一段代码,它定义了链接器如何处理各个文件的.init_array:
INIT_ARRAY=".init_array :
{
${CREATE_SHLIB-PROVIDE_HIDDEN (${USER_LABEL_PREFIX}__init_array_start = .);}
${SORT_INIT_ARRAY}
KEEP (*(.init_array ${CTORS_IN_INIT_ARRAY}))
${CREATE_SHLIB-PROVIDE_HIDDEN (${USER_LABEL_PREFIX}__init_array_end = .);}
}"
但这里遗留了一个问题:ld.so是如何在加载阶段将相关信息填入到link_map的l_info中的?要回答这个问题,我们需要理解ld.so是如何加载一个动态链接库的。
加载动态链接库
dl_main
我们上一篇梳理了dl_main在启动可执行文件整体流程中的位置如下:
_start
-> _dl_start
-> _dl_start_final (返回用户可执行文件的入口)
-> _dl_sysdep_start (执行下面的一系列操作 最终返回用户可执行文件的入口给ld)
-> _dl_sysdep_parse_arguments (解析参数)
-> dl_main
-> process_envvars (处理环境变量)
-> _dl_new_object (初始化一个空的link_map 作为用户可执行文件的主link_map)
-> _dl_add_to_namespace_list (将用户可执行文件的main link_map加入到命名空间链表中)
-> rtld_setup_main_map (根据ProgramHeaderTable 填充用户可执行文件的主link_map)
-> _dl_map_object_deps (递归加载动态链接库)
-> init_tls (初始化tls)
-> _dl_relocate_object (重定位动态链接库)
-> _dl_init
-> 跳转到用户可执行文件入口
具体来说dl_main的主要职责如下:
- 环境变量处理:处理影响动态链接器行为的环境变量(如
LD_LIBRARY_PATH、LD_PRELOAD等) - 处理用户可执行文件:创建主程序的
link_map结构,解析主程序的Program Headers,设置主程序的内存映射信息 - 递归加载依赖项:通过
_dl_map_object_deps加载用户可执行文件依赖的所有动态链接库,以及处理预加载库(LD_PRELOAD) - 构建全局作用域:为所有加载的动态链接库构建搜索列表,并设置符号查找的作用域
- 重定位处理:首先重定位
libc.so(如果已加载),然后重定位所有其他动态链接库
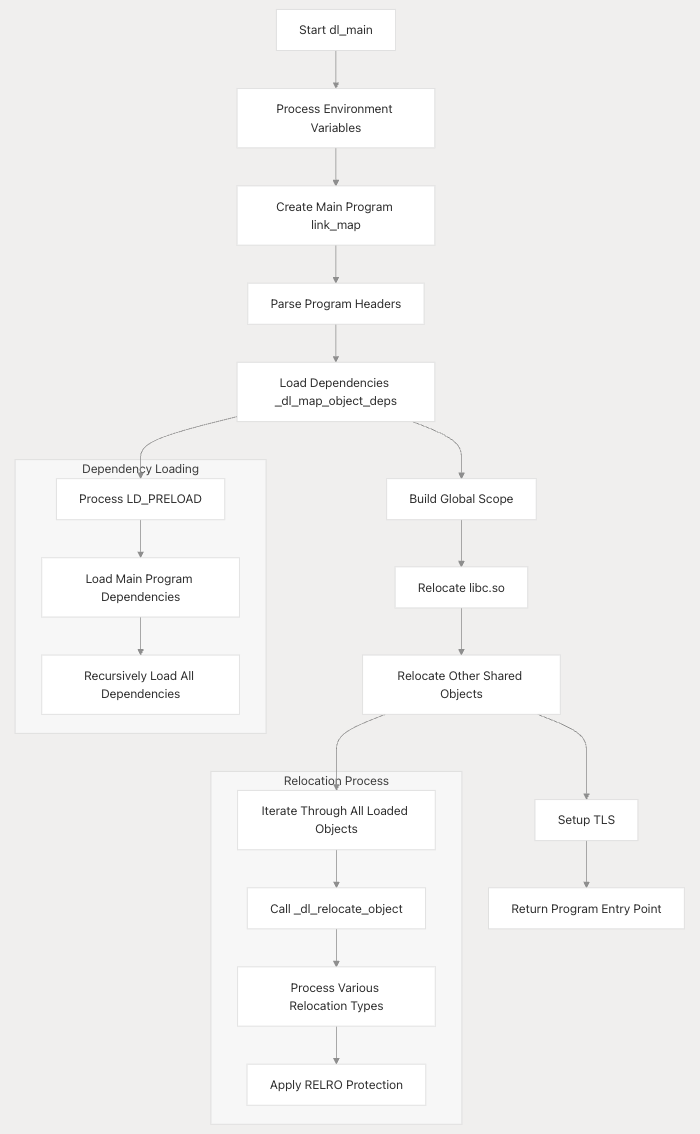
dl_main中的前几部分在上一篇以及有所覆盖,这一篇中我们会主要探索动态链接库的加载流程。
_dl_map_object
首先,_dl_map_object_deps最终会调用到_dl_map_object函数(elf/dl-load.c中),此处会查找动态链接库,检查是否已加载,然后打开对应的动态链接库,拿到对应的fd。
(gdb) bt
#0 elf_get_dynamic_info (static_pie_bootstrap=false, bootstrap=false, l=0x7ffff7fbd170) at ./elf/get-dynamic-info.h:39
#1 _dl_map_object_from_fd (name=name@entry=0x400530 "libstdc++.so.6", origname=origname@entry=0x0, fd=<optimized out>, fbp=fbp@entry=0x7fffffffd3d0,
realname=<optimized out>, loader=loader@entry=0x7ffff7ffe2e0, l_type=<optimized out>, mode=<optimized out>, stack_endp=<optimized out>,
nsid=<optimized out>) at ./elf/dl-load.c:1271
#2 0x00007ffff7fce529 in _dl_map_object (loader=<optimized out>, name=0x400530 "libstdc++.so.6", type=1, trace_mode=<optimized out>, mode=0,
nsid=<optimized out>) at ./elf/dl-load.c:2268
#3 0x00007ffff7fc7a2d in openaux (a=a@entry=0x7fffffffd980) at ./elf/dl-deps.c:64
#4 0x00007ffff7fc651c in __GI__dl_catch_exception (exception=exception@entry=0x7fffffffd960, operate=operate@entry=0x7ffff7fc79f0 <openaux>,
args=args@entry=0x7fffffffd980) at ./elf/dl-catch.c:237
#5 0x00007ffff7fc7e67 in _dl_map_object_deps (map=map@entry=0x7ffff7ffe2e0, preloads=preloads@entry=0x0, npreloads=<optimized out>,
trace_mode=<optimized out>, open_mode=open_mode@entry=0) at ./elf/dl-deps.c:232
#6 0x00007ffff7fe741c in dl_main (phdr=<optimized out>, phnum=<optimized out>, user_entry=<optimized out>, auxv=<optimized out>) at ./elf/rtld.c:1965
#7 0x00007ffff7fe3f46 in _dl_sysdep_start (start_argptr=start_argptr@entry=0x7fffffffe1c0, dl_main=dl_main@entry=0x7ffff7fe5af0 <dl_main>)
at ../sysdeps/unix/sysv/linux/dl-sysdep.c:140
#8 0x00007ffff7fe575e in _dl_start_final (arg=0x7fffffffe1c0) at ./elf/rtld.c:494
#9 _dl_start (arg=0x7fffffffe1c0) at ./elf/rtld.c:581
#10 0x00007ffff7fe4548 in _start () from /lib64/ld-linux-x86-64.so.2
#11 0x0000000000000001 in ?? ()
#12 0x00007fffffffe47b in ?? ()
#13 0x0000000000000000 in ?? ()
最后,_dl_map_object会调用_dl_map_object_from_fd。
_dl_map_object_from_fd
在_dl_map_object_from_fd中,会执行以下一系列操作:
- 通过
_dl_get_file_id获取动态链接库唯一标识,在全局链表GL(dl_ns)[nsid]._ns_loaded中检查是否已存在相同文件 - 如果打开的是
ld.so,首先需要确保ld.so没有被重复打开。如果的确是第一次,则调用_dl_new_object,并加入到全局命名空间列表中。 - 调用
_dl_new_object初始化link_map,读取ProgramHeaderTable地址,之后开始遍历ProgramHeaderTable读取ProgramHeader(这部分和上一篇文章中_dl_start比较相似),不过这里主要是在处理以下几个segment:PT_DYNAMIC:.dynamic的地址,它其中包括了ld.so在加载和链接这个动态链接库时所需的信息PT_PHDR:ProgramHeader的地址PT_LOAD:可以被加载的segment,即上一篇中通过readelf -l看到的ProgramHeaderType为LOAD的segment,比如code和dataPT_TLS:Thread-Local Storage
- 调用
_dl_map_segments将动态链接库中的segment映射到内存中,并把相关结果保存到link_map中,这个过程会根据动态链接库是否是PIC有不同处理(ET_DYN和ET_EXEC)- 调用
mmap进行内存映射 -
调用
__mprotect对内存中的映射段设置权限(可读可写可执行等),权限是根据ProgramHeader中的pflags设置的,代码在dl-load.c中:/* Optimize a common case. */ #if (PF_R | PF_W | PF_X) == 7 && (PROT_READ | PROT_WRITE | PROT_EXEC) == 7 c->prot = (PF_TO_PROT >> ((ph->p_flags & (PF_R | PF_W | PF_X)) * 4)) & 0xf; #else c->prot = 0; if (ph->p_flags & PF_R) c->prot |= PROT_READ; if (ph->p_flags & PF_W) c->prot |= PROT_WRITE; if (ph->p_flags & PF_X) c->prot |= PROT_EXEC; #endif - 为未初始化数据(BSS)分配空间并清零
- 调用
- 调用
elf_get_dynamic_info解析.dynamic:-
遍历
.dynamic中的每个条目,然后根据其标签类型存储在link_map中l_info合适的部分(包括我们正在研究的全局对象的构造函数)for (ElfW(Dyn)* dyn = l->l_ld; dyn->d_tag != DT_NULL; dyn++) { d_tag_utype i; if ((d_tag_utype)dyn->d_tag < DT_NUM) i = dyn->d_tag; else if (dyn->d_tag >= DT_LOPROC && dyn->d_tag < DT_LOPROC + DT_THISPROCNUM) i = dyn->d_tag - DT_LOPROC + DT_NUM; else if ((d_tag_utype)DT_VERSIONTAGIDX(dyn->d_tag) < DT_VERSIONTAGNUM) i = VERSYMIDX(dyn->d_tag); else if ((d_tag_utype)DT_EXTRATAGIDX(dyn->d_tag) < DT_EXTRANUM) i = DT_EXTRATAGIDX(dyn->d_tag) + DT_NUM + DT_THISPROCNUM + DT_VERSIONTAGNUM; else if ((d_tag_utype)DT_VALTAGIDX(dyn->d_tag) < DT_VALNUM) i = DT_VALTAGIDX(dyn->d_tag) + DT_NUM + DT_THISPROCNUM + DT_VERSIONTAGNUM + DT_EXTRANUM; else if ((d_tag_utype)DT_ADDRTAGIDX(dyn->d_tag) < DT_ADDRNUM) i = DT_ADDRTAGIDX(dyn->d_tag) + DT_NUM + DT_THISPROCNUM + DT_VERSIONTAGNUM + DT_EXTRANUM + DT_VALNUM; else continue; info[i] = dyn; } -
如果动态链接库被加载到与其链接地址不同的位置,则会调整动态段中的地址
/* Don't adjust .dynamic unnecessarily. */ if (l->l_addr != 0 && dl_relocate_ld(l)) { ElfW(Addr) l_addr = l->l_addr; #define ADJUST_DYN_INFO(tag) \ do { \ if (info[tag] != NULL) info[tag]->d_un.d_ptr += l_addr; \ } while (0) ADJUST_DYN_INFO(DT_HASH); ADJUST_DYN_INFO(DT_PLTGOT); ADJUST_DYN_INFO(DT_STRTAB); ADJUST_DYN_INFO(DT_SYMTAB); ADJUST_DYN_INFO(DT_RELR); ADJUST_DYN_INFO(DT_JMPREL); ADJUST_DYN_INFO(VERSYMIDX(DT_VERSYM)); ADJUST_DYN_INFO(ADDRIDX(DT_GNU_HASH)); #undef ADJUST_DYN_INFO /* DT_RELA/DT_REL are mandatory. But they may have zero value if there is DT_RELR. Don't relocate them if they are zero. */ #define ADJUST_DYN_INFO(tag) \ do \ if (info[tag] != NULL && info[tag]->d_un.d_ptr != 0) info[tag]->d_un.d_ptr += l_addr; \ while (0) #if !ELF_MACHINE_NO_RELA ADJUST_DYN_INFO(DT_RELA); #endif #if !ELF_MACHINE_NO_REL ADJUST_DYN_INFO(DT_REL); #endif #undef ADJUST_DYN_INFO }
-
- 调用
_dl_setup_hash将动态链接库的link_map保存到一个哈希表中,方便后续符号查找 - 调用
_dl_assign_tls_modid分配TLS模块ID - 调用
_dl_add_to_namespace_list将这个动态链接库加入全名命名空间链表中
到这我们就可以回答前面的问题了:ld.so在加载阶段,准确说是在elf_get_dynamic_info中把相关函数指针保存到了link_map的l_info中。
_dl_relocate_object
上一步_dl_map_object_from_fd已经将动态链接库进行了加载,而此时还不能直接使用这个动态链接库。ld.so会调用_dl_relocate_object处理已加载到内存中的动态链接库的重定位信息,确保其中的符号引用能够正确解析到实际的内存地址。
首先我们理解下为什么需要重定位:
- 动态链接库通常被编译为位置无关代码(Position Independent Code),这意味着它们可以被加载到内存中的任何位置。但是,代码中的符号(如函数和全局变量)在编译时只是占位符,它们的实际地址在程序加载时才能确定。重定位过程会解析这些符号引用,将它们指向正确的内存位置。
- 为了提高程序启动性能,动态链接器会使用延迟绑定(Lazy Binding)技术,即函数的实际地址解析推迟到第一次调用时进行。这需要重定位机制的支持。
_dl_relocate_object会被几个地方调用:
dl_main中会对所有加载的动态链接库进行重定位dlopen对新加载的动态链接库进行重定位
_dl_relocate_object的主要流程(代码在sysdeps/x86_64/dl-machine.h):
- 检查是否已经重定位过。
- 一些初始化处理。
- 在用
ELF_DYNAMIC_RELOCATE宏中:- 调用
elf_machine_runtime_setup更新GOT - 完成各种类型的重定位。会根据不同架构(如 x86_64、ARM等)处理不同类型的重定位,如
RELATIVE、GLOB_DAT、JUMP_SLOT、IRELATIVE等。另外ELF_DYNAMIC_RELOCATE在这个过程中会判断是否允许延迟绑定。
- 调用
- 标记重定位完成。
- 调用
_dl_protect_relro来应用RELRO(RELocation Read-Only)保护,将已重定位的只读数据段标记为只读,增强安全性。
延迟绑定
既然都提到了延迟绑定,下面就顺便介绍一下这块原理,也能更好的理解重定位是如何完成的。延迟绑定主要设计到几块:
- 数据结构:
- PLT(Procedure Linkage Table,对应
.plt) - GOT(Global Offset Table,对应
.plt.got)
- PLT(Procedure Linkage Table,对应
- 加载阶段,
ld.so通过_dl_relocate_object完成重定位 - 运行阶段,通过PLT和GOT完成延迟绑定
PLT & GOT
我们先建立下基础概念:PLT可以理解为一个跳板,每次进行符号解析时,会先通过PLT这个跳板,最终在GOT中查找对应的符号。GOT负责实际保存解析好的符号,如果符号没有解析过,则会进行符号解析(这个过程会存在若干次PLT和GOT之间的跳转)。
每个PLT的条目都和GOT中的条目一一对应,对应关系是在编译链接时就确定的。当编译器和链接器创建可执行文件或动态链接库时,它们会:
- 创建PLT表,其中包含一系列跳转指令,使其引用GOT表中的特定偏移量
- 创建GOT表,但此时GOT表中的
GOT[1]和GOT[2]这两个条目是空的(参照下面说明)
我们先看下PLT,每个PLT的条目都和GOT中的条目一一对应,我们不妨假设PLTn对应GOT的第X条目。PLT条目结构如下:
.PLTn:
jmp *GOT_X(%rip) # 跳转到GOT中第X个条目存储的地址
pushq $n # 压栈重定位表中的偏移量或者序号
jmp .PLT0 # 跳转到PLT0处理
PLT0代码如下:
.PLT0:
pushq GOT+8(%rip) # 压栈GOT[1]
jmp *GOT+16(%rip) # 跳转到GOT[2] 即符号解析函数
每个PLT Entry包含三条指令:
jmp *GOT_X(%rip)会跳转到对应GOT条目所指向的地址。GOT除了前三个Entry之外,每一个Entry一开始都会指向对应PLT Entry的第二条指令。以PLTn为例,对应的GOT条目中的地址指向PLTn的第二条指令pushq $n,实际也就是当前指令jmp *GOT_X(%rip)的下一条指令。pushq $n:将PLT中的偏移量或者序号压栈jmp PLT0会跳转到一条特殊的条目PLT0。它会将GOT[1]压栈,然后跳转到GOT[2]的地址,即_dl_runtime_resolve,进行实际的符号解析。
需要注意的是,在编译链接的阶段生成PLT和GOT后,.PLT0汇编代码中虽然使用了GOT[1]和GOT[2],但此时GOT[1]和GOT[2]的实际内容仍为空,它们会在加载阶段由ld.so在elf_machine_runtime_setup中更新(参见下面流程)。
GOT表有类似下面的结构,其中前三个条目一定是固定的,指向特殊的地址,分别是:
GOT[0]保存.dynamic段的地址GOT[1]保存当前动态链接库的link_map地址,用于告知ld.so是哪个动态链接库请求解析符号GOT[2]保存_dl_runtime_resolve的地址- 从
GOT[3]开始(如果存在的话),它保存的是指向某个PLT条目的第二条指令,即pushq $n,用于解析一个特定符号。
GOT[0] 动态段dynamic section的地址
GOT[1] 当前动态链接库的link_map指针 (此时为空)
GOT[2] _dl_runtime_resolve函数的地址,用于在运行时进行解析 (此时为空)
GOT[3] 指向对应PLT的第二条指令
GOT[4] 指向对应PLT的第二条指令
GOT[5] 指向对应PLT的第二条指令
...
理解PLT和GOT的关键在于:PLT对GOT的引用是通过偏移量或相对地址实现的。编译链接阶段已经知道PLT和GOT之间的偏移量了。我们可以这么理解PLT中的jmp *GOT_X(%rip),我们在执行这条命令之前已经知道:
- PLT和GOT的偏移量
GOT_X是第X个条目相对于GOT的偏移量%rip则是当前指令地址,也就是当前PLT某个条目的地址。
所以结合几个偏移量,就可以通过相对寻址的方式,从PLT跳转到jmp *GOT_X(%rip),即从PLTn跳转到GOT中对应的第X个条目。
接下来我们通过画图的方式来说明这过程。在编译链接阶段之后,PLT和GOT之间的跳转关系如下图所示:
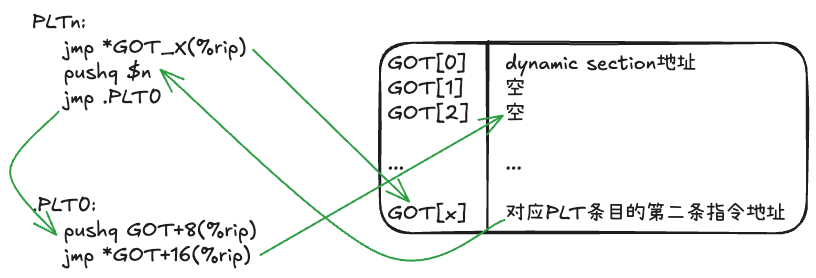
更新GOT[1]和GOT[2]
ld.so在加载阶段做了一些预处理:在上面提到的elf_machine_runtime_setup中,更新GOT[1]和GOT[2],之后PLT就能正常工作了,代码如下:
static inline int
__attribute__((unused, always_inline)) elf_machine_runtime_setup(
struct link_map* l, struct r_scope_elem* scope[], int lazy, int profile) {
Elf64_Addr* got;
// ...
if (l->l_info[DT_JMPREL] && lazy) {
/* The GOT entries for functions in the PLT have not yet been filled
in. Their initial contents will arrange when called to push an
offset into the .rel.plt section, push _GLOBAL_OFFSET_TABLE_[1],
and then jump to _GLOBAL_OFFSET_TABLE_[2]. */
got = (Elf64_Addr*)D_PTR(l, l_info[DT_PLTGOT]);
/* If a library is prelinked but we have to relocate anyway,
we have to be able to undo the prelinking of .got.plt.
The prelinker saved us here address of .plt + 0x16. */
if (got[1]) {
l->l_mach.plt = got[1] + l->l_addr;
l->l_mach.gotplt = (ElfW(Addr))&got[3];
}
/* Identify this shared object. */
*(ElfW(Addr)*)(got + 1) = (ElfW(Addr))l;
const struct cpu_features* cpu_features = __get_cpu_features();
// ...
{
/* This function will get called to fix up the GOT entry
indicated by the offset on the stack, and then jump to
the resolved address. */
if (MINIMUM_X86_ISA_LEVEL >= AVX_X86_ISA_LEVEL ||
GLRO(dl_x86_cpu_features).xsave_state_size != 0)
*(ElfW(Addr)*)(got + 2) = (CPU_FEATURE_USABLE_P(cpu_features, XSAVEC)
? (ElfW(Addr))&_dl_runtime_resolve_xsavec
: (ElfW(Addr))&_dl_runtime_resolve_xsave);
else
*(ElfW(Addr)*)(got + 2) = (ElfW(Addr))&_dl_runtime_resolve_fxsave;
}
}
return lazy;
}
几个关键点如下:
got = (Elf64_Addr*)D_PTR(l, l_info[DT_PLTGOT]);先从link_map中获取GOT地址*(ElfW(Addr)*)(got + 1) = (ElfW(Addr))l;更新GOT[1]为当前link_map地址*(ElfW(Addr)*)(got + 2) = (ElfW(Addr))&_dl_runtime_resolve_fxsave;更新GOT[2]为对应符号解析函数地址
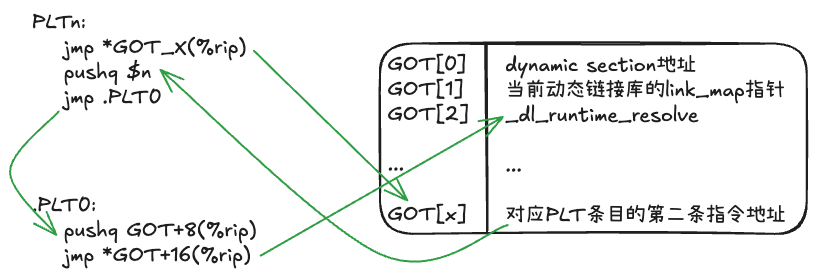
符号解析
在运行时,当第一次调用某个使用延迟绑定的函数时,控制流会转到PLT中的代码,不妨假设是上面的PLTn:
- 跳转
*GOT_X(%rip),实际也就是jmp *GOT_X(%rip)的下一条指令push $n pushq $n会将重定位表中的偏移量或者序号压栈,通过这个偏移量,ld.so在调用时_dl_runtime_resolve就能找到重定位表中对应的Entry。- 之后开始执行
PLT0的逻辑,即将GOT[1]即link_map指针压栈,并跳转到GOT[2]指向的_dl_runtime_resolve函数进行符号解析(代码在sysdeps/x86_64/dl-trampoline.h):- 保存当前寄存器状态
- 从栈上获取参数(偏移量
reloc_arg和link_map) - 调用
_dl_fixup(代码在elf/dl-runtime.c),它负责实际的符号解析工作- 从
DT_SYMTAB中查找符号信息 - 调用
_dl_lookup_symbol_x在适当的作用域中搜索符号 - 计算符号的实际地址
- 更新GOT表中对应的条目,即GOT中第X个条目不再指向对应的
PLTn的第二条指令了,而是指向目标符号地址 - 返回解析后的符号地址
- 从
- 恢复寄存器状态
- 此时已经完成了符号解析,跳转到这个符号地址开始执行
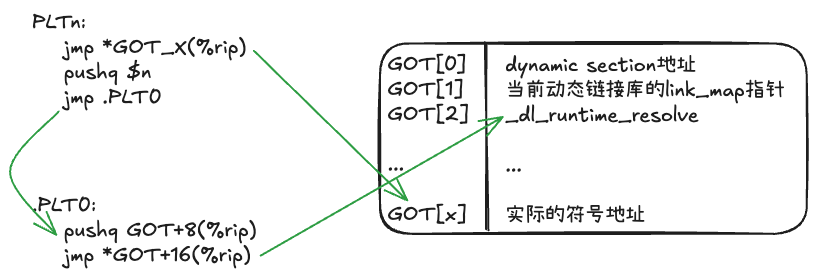
而同一个函数被再次调用时,由于GOT表中的条目已经被更新,PLTn中的jmp *GOT_X(%rip)会直接跳转到对应的符号地址,不再需要经过符号解析的过程。
延迟调用整体的时序图如下:
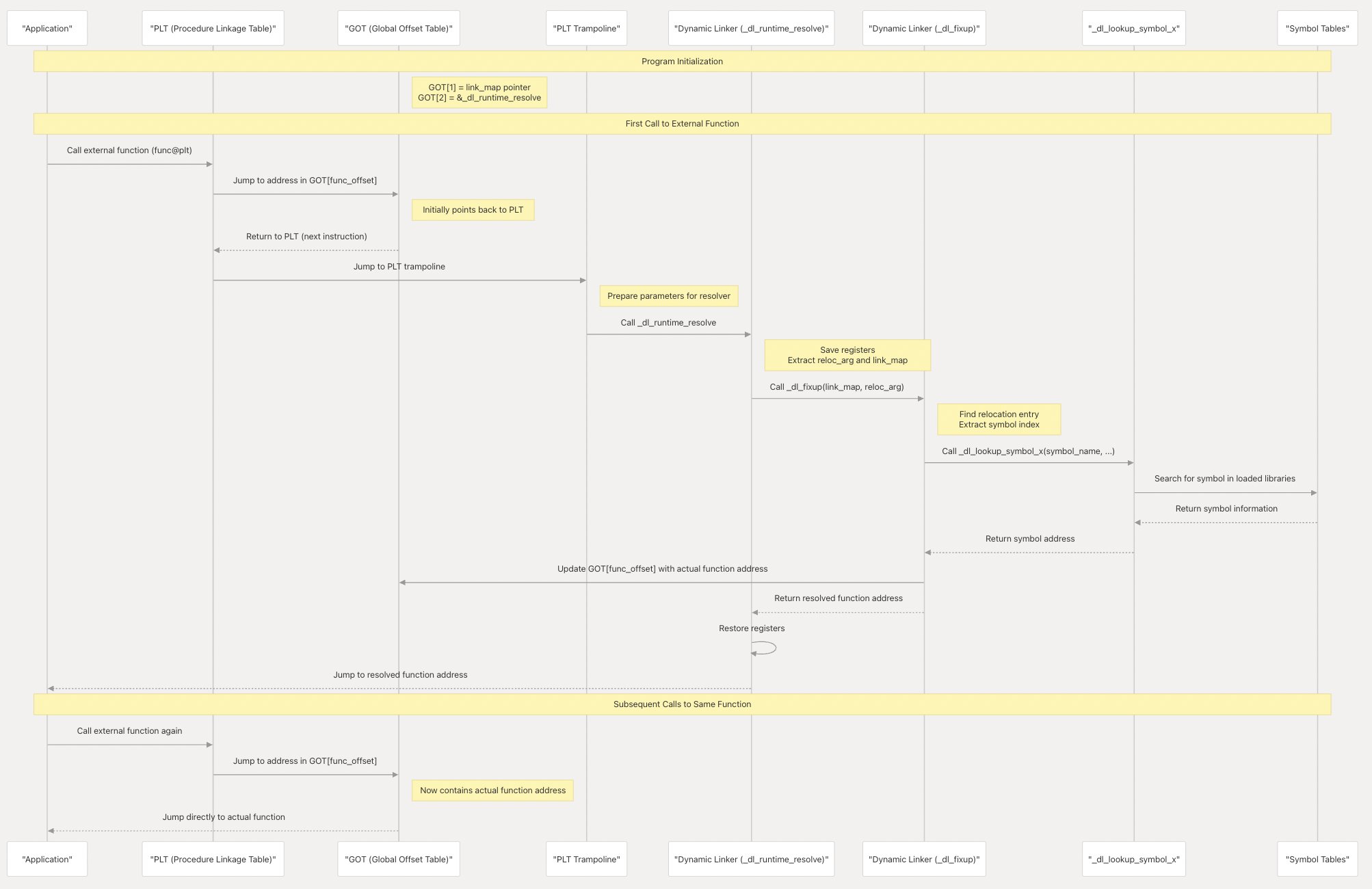
默认配置下ld.so是会使用延迟绑定的,不过有以下手段可以控制是否使用:
- 通过环境变量
LD_BIND_NOW:如果设置了此环境变量,动态链接器会在加载时解析所有符号,禁用延迟绑定。 - 通过共享对象的
DT_BIND_NOW:如果动态连疾苦设置了此标记,动态链接器会在加载该对象时解析其所有符号。 - 通过
dlopen的RTLD_NOW:如果使用此标志调用dlopen,动态链接器会立即解析新加载对象中的所有符号。
main
回到我们最初全局对象的构造这个问题上,在我们了解动态链接库是如何被ld.so加载后,就知道ld.so会将.init_array中的函数指针进行重定位,并填入到link_map的l_info[DT_INIT_ARRAY]和l_info[DT_INIT_ARRAYSZ]中。最终在main函数之前,也就上面的call_init中,会执行这些初始化函数。
之后,在执行上一篇介绍过的_dl_init之后,就会跳转到用户可执行文件的入口main了!完结!