Snapshot Isolation in TLA+
坦率来说,这次入坑TLA+的主要目的就是为了能够试着验证快照隔离。啃了大半本Practical TLA+,看了不少其他人的例子,自己也尝试写了些spec,仍然只能说勉强入门了。在网上能找到的大多数事务相关的spec都是TLA+直接实现的,目前对于我来说未免还是太困难了点。因此这篇文章,会通过TLA+的伪代码语言PCal来实现一个快照隔离spec。
快照隔离
不多介绍,快照隔离的核心处理逻辑在于:
- 任何读操作看到的是一个数据库完整的快照版本,读不会读到并发的写事务写入的数据(如下图中
txn-n不能读到txn-c的写入),即读不会阻塞写 - 并发写事务采取first-commiter-wins策略(如下图txn-n和txn-c同时满足时间和空间上有overlap,至少有一个事务需要abort)

TLA+实现
为了简化模型,我们这里做一些假设:
- 系统使用全局唯一授时,且授时的服务不会crash
- 网络是异步但是可靠的,即任何写入或读取可以delay任意时间,但不会丢包
- 数据库是单机的,客户端有多个,客户端不会crash
数据模型
我们假设有txnIds个事务同时执行,keys和values是简单的两个枚举类型,用来表示数据库中的数据,每个key的初始值为Empty。
CONSTANT txnIds, keys, values, Empty
然后是模型中定义的变量:
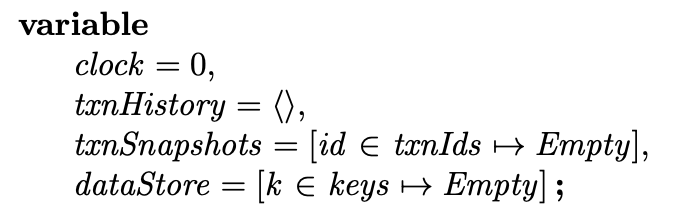
clock是全局时间。dataStore是一个key-value的映射,初始值均为Empty。txnSnapshots用来保存某个txnId到dataStore某个时间点快照的映射。
txnHistory是事务提交记录,我们使用和前文类似的记录形式,分别有几个字段:
type:事务执行操作类型,可选值为begin/commit,read/writetxnId:事务的idtime:操作的时间,只在begin和commit时需要key:读写的key,只在read和write时需要val:读写的value,只在read和write时需要updatedKeys:事务的写集合,只在commit操作中记录,用来后续判断写写冲突
举个例子如下是一个写偏序的事务提交记录,T1和T2分别读了X和Y,最后T1更新X,T2更新Y,在快照隔离下,是一个合法的事务提交记录。
<<
[type |-> "begin", txnId |-> 1, time |-> 1],
[type |-> "begin", txnId |-> 2, time |-> 2],
[type |-> "read", txnId |-> 1, key |-> "X", val |-> "Empty"],
[type |-> "read", txnId |-> 1, key |-> "Y", val |-> "Empty"],
[type |-> "read", txnId |-> 2, key |-> "X", val |-> "Empty"],
[type |-> "read", txnId |-> 2, key |-> "Y", val |-> "Empty"],
[type |-> "write", txnId |-> 1, key |-> "X", val |-> 30],
[type |-> "write", txnId |-> 2, key |-> "Y", val |-> 20],
[type |-> "commit", txnId |-> 1, time |-> 3, updatedKeys |-> {"X"}],
[type |-> "commit", txnId |-> 2, time |-> 4, updatedKeys |-> {"Y"}]
>>
Operator
接下来是在下面算法描述中可能会使用的一些operator,可以结合注释以及下文算法描述一起看:

虽然定义的operator非常多,但几乎所有的operator都有一个参数h,对应txnHistory。其作用都是在txnHistory中查找特定的事务操作,比如:
ReadsByTxn和WritesByTxn用来查找特定事务的读写操作KeysReadByTxn和KeysWrittenByTxn用来查找特定事务的读写集合BeginOp和CommitOp用来查找特定事务的begin和commit操作BeginTs和CommitTs用来查找特定事务的begin和commit时间戳CommittedTxns和AbortedTxns用来查找已经commit或者abort的事务DataStoreType用来验证dataStore中的值都是合法值BeginOpType、CommitOpType、WriteOpType、ReadOpType、AnyOpType是用来验证txnHistory中的操作记录都是合法值
而最后一个opeartor就是用来检查快照隔离下写写冲突的,当我们尝试commit一个事务T1的时候,在txnHistory中检查是否存在与T1冲突的T2,当T1和T2同时满足如下条件时,T1和T2冲突:
- T1和T2是两个事务
- T1和T2满足temporal overlap,即
BeginTs(T1) < CommitTs(T2)且BeginTs(T2) < CommitTs(T1),此时T1和T2是并发的。(当然T1此时还没有commit,所谓的CommitTs(T1)代表T1想要commit此时的时间戳,也就是全局时钟clock) - T1和T2满足spartial overlap,即T1和T2同时更新一个key
算法描述
我们简单描述下运行的模型,dataStore是个key-value映射,没有多版本。总共有txnIds个客户端,每个客户端负责推动其中一个事务。每个客户端可能会执行如下操作,任何操作都会往txnHistory中添加当前操作的记录。
- start事务
- 读写数据
- commit事务
- abort事务
客户端在开启事务之后,根据快照隔离的语义,会将当前dataStore直接复制一份作为快照(即下面描述中的txnSnapshots[self]),此后任何客户端的读写操作都是基于这个快照来执行。如果写集合不为空,在最后commit的时候会将dataStore中的对应key-value更新为快照中的值。
当然在实际数据库实现中,把整个dataStore复制一份作为快照是不显示的,一般都是基于MVCC来确定数据库的快照版本。但为了简化TLA+的实现,我们采取如上的机制。
另外一点需要强调的是,同样是为了降低之后TLC验证的复杂度,我们在同一个事务之内,限定了每个key最多只能被读一次,也最多只能被读一次(但可以先读后写或者先写后读同一个key)。这样的好处就是当给定事务可读写的范围keys之后,每一个事务的操作记录个数是有限的。

我们详细描述一下算法模型:
- 客户端处于第5行的一个while循环之内,只有当客户端负责推进的事务已经commit或者abort之后,当前客户端才会退出。
- 第6行判断当前事务是否已经开始(通过判断
txnHistory中是否有对应txnId的记录)。如果还没开始,则进入第7行StartTxn分支,执行如下操作:- 时钟加一
- 往
txnHistory添加一个开启事务的记录 - 获取当前dataStore的快照。为了简化实现,
dataStore只有单版本,但是可以把整个dataStore在当前时间点的状态全部复制到txnSnapshots[self]中当做快照。
- 如果事务已经开始,则进入第14-51行的这个block中,选择下列操作之一开始执行:
- 33-39行负责读数据,在
keys中挑选一个当前事务还没有读过的k进行读,读到的值就是txnSnapshots[self][k],最后往txnHistory添加一个读数据的记录 - 41-50行负责写数据,在
keys中挑选一个当前事务还没有写过k进行写,任意挑选一个v作为更新之后的值,更新到自己的快照txnSnapshots[self]中,最后往txnHistory添加一个写数据的记录 - 15-31行负责决定commit还是abort事务,我们不允许一个空的事务,所以在15行一直等到读集合或者写集合不为空
- 如果
TxnCanCommit为真,代表没有写写冲突,则commit这个事务,所做的事情就是将自己的写集合更新到dataStore中,并往txnHistory添加一个commit事务的记录 - 如果
TxnCanCommit为假,代表发生了写写冲突,我们采用fisrt-commit-wins的策略,将当前事务abort,所做任何修改不会更新到dataStore中,并往txnHistory添加一个abort事务的记录
- 如果
- 33-39行负责读数据,在
到这算法描述就结束了,只有短短的几十行伪代码,但已经完整的描述了快照隔离下的并发控制。
TLC验证条件
我们该如何验证上面模型的正确性呢?我们定义如下的Invariant和Temporal Property

TypeInvariant用来验证txnHistory、dataStore和txnSnapshots在任何时候值都合法AllTxnFinished用来验证是否所有事务最后commit或者abort了。由于我们不允许任何一个client出现crash,所以任何一个事务在txnHistory中一定存在一个commit或者abort记录。- 后两个
Searializable和NoReadOnlyAmonaly会稍微展开说明
Searializable
Searializable用来验证快照隔离下的事务提交记录是否满足可串行化
答案当然是不行,但我们可以通过TLC找到什么事务提交历史不满足可串行化
这一部分在前文以及比较详细的说过了,具体参照前文,这里只简单说明下我们判断txnHistory这个事务提交历史是否满足可串行化的流程:
-
通过其事务先后依赖关系生成有向图MVSG,事务先后依赖关系指写写依赖、写读依赖和读写依赖。下面的
SerializationGraph(h)就是根据传入的事务提交历史,根据三种依赖生成对应的MVSG中的所有边。
-
判断MVSG中是否有环,如果有环则不满足可串行化。其实现就是根据上一步生成的所有边,判断这个有向图中是否有环。如果
IsCyle为TRUE,则IsConflictSerializable为FALSE,对应的检查条件Serializble也为FALSE。
NoReadOnlyAmonaly
NoReadOnlyAnomaly是用来验证在快照隔离级别下,某一个只读事务的读取结果违反可串行化。它用来检查如下情况是否会出现:如果一个事务执行历史不满足Conflict Serializable,但是去掉了一个只读事务后反而满足Conflict Serializable。我们来看下论文中的例子:
某个银行系统的每个账户有两个变量savings(存款)和checking(账单),事务做的事情分别如下:
- T1:往存款增加20块
- T2:往账单加10块(由于是扣款,用负数表示),如果
存款 + 账单的总额小于0,则额外扣一块钱透支费
假设存款和账单的初始值都是0,那么在可串行化的执行下,最后结果可能是如下两种
- T1 → T2: T1先执行,存款为20;T2后执行,由于
存款 + 账单 >= 0,账单为-10 - T2 → T1: T2先执行,由于
存款 + 账单 < 0,所以需要额外扣1块透支费,此时账单为-11;T1后执行T1,存款为20
所以两种执行顺序最后的结果的存款都是20,账单可能是-10或者-11。现在我们新增一个只读事务T3:
- T3:读存款和账单
有趣的事情发生了,T3的读取结果有可能不是前面的任何一种,对应的事务提交历史如下:
| Txn 1 | Txn 2 | Txn 3 |
|---|---|---|
| R(checking) → 0 | ||
| R(savings) → 0 | ||
| R(savings) → 0 | ||
| W(savings) ← 20 | ||
| Commit | ||
| R(checking) → 0 | ||
| R(savings) → 20 | ||
| Commit | ||
| W(checking) ← -11 | ||
| Commit |
T2先开始,读了账单和存款初始值为0。随后T1执行并提交。随后T3开始,由于是快照隔离,T3能够读到T1的结果,所以账单为0,存款为20。此时T2重新开始执行,由于在T2的视角,并不能读到起始时间戳更大的T1的写入结果,所以此时
存款 + 账单 < 0,需要额外扣除透支费,写入账单为-11。
我们可以看到只读事务T3读到了存款为20,但账单为0的结果,这只可能出现在T1 → T3 → T2这样的执行顺序(因为T3读到了T1的写入,确没有读到T2的写入,所以执行顺序一定是T1 → T3 → T2)。但是,如果真的串行化执行T1 → T3 → T2,最后T2写入的账单值应该为-10而不是上面的执行历史的-11,这显然是不满足可串行化的。
所以一个只读事务的出现,其结果可能是不能满足可串行化的。NoReadOnlyAnomaly就是用来检查这样的事务提交历史,其实现如下:

也就是某个事务提交历史不满足可串行化,但是当我们把某个只读事务从提交历史去掉后,反而满足可串行化了。
验证时间
首先我们来验证快照隔离下能否满足可串行化,我们的参数设置如下:
- 有两个事务:
t1和t2 - 有两个key:
k1和k2 - 可选的value也是两个:
v1和v2

然后Invariant设置上Serailizable,在我的mac上大概运行了1分钟左右,提示Invariant Searializable is violated。我们看下Error-Trace,前面的状态都省略了,直接看txnHistory就能知道两个事务是如何执行的:
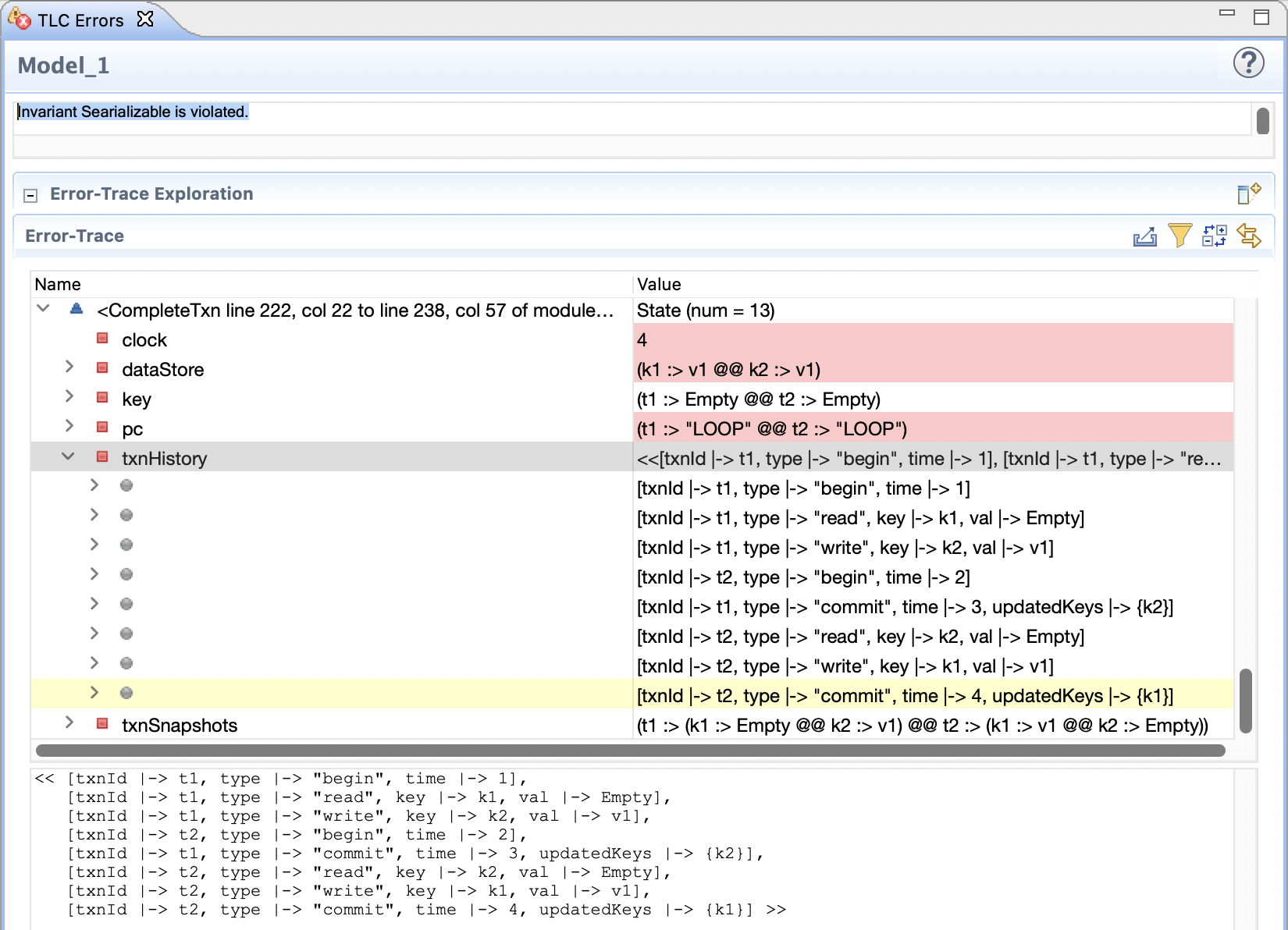
可以看到在这个历史中,T1和T2是并发的,且T1读写依赖于T2,T2读写依赖于T1,所以在事务依赖图中出现了环,于是报了错。
然后我们验证另一个NoReadOnlyAnomaly,参数设置如下:
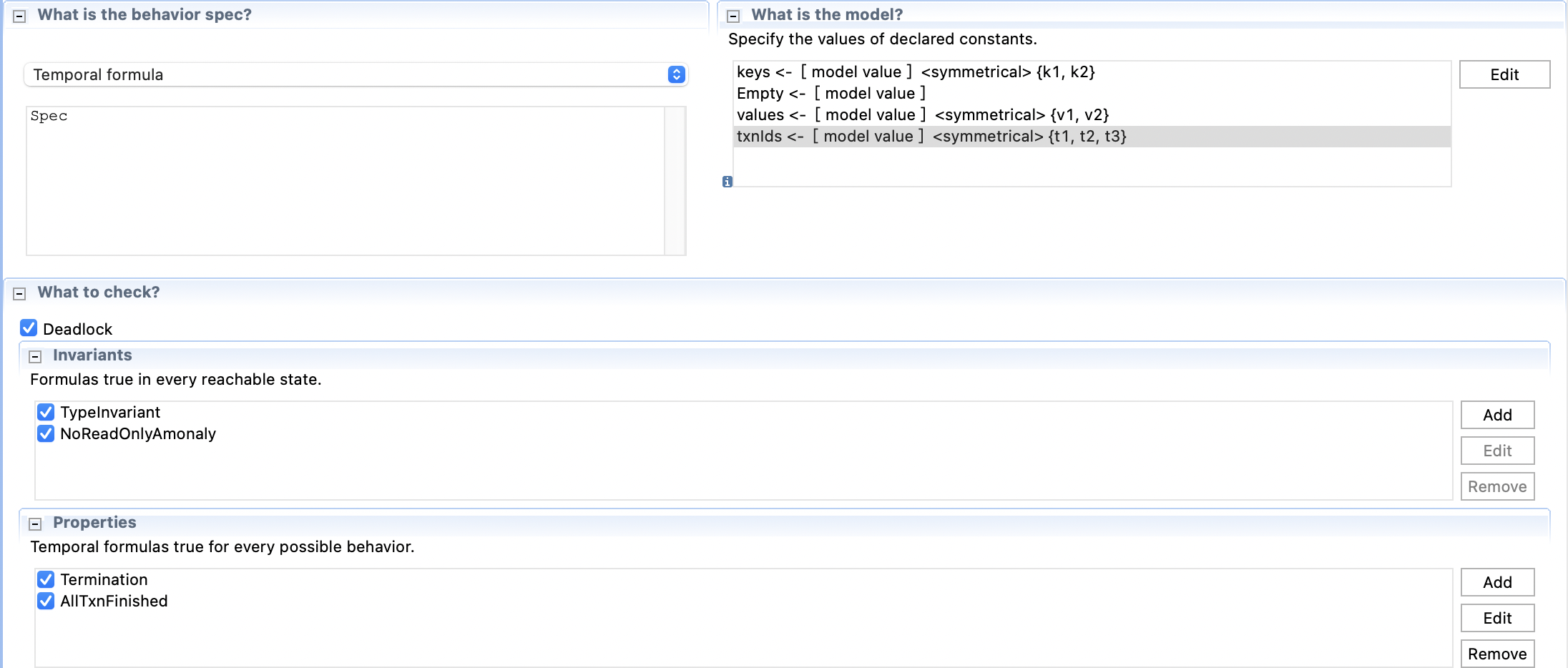
与前面那个相比就是修改了Invariant,并且增加了一个事务。想要跑出不满足的Error Trace,至少需要三个事务。
这里不得不说的是,目前这个实现在我的mac上验证的实在太慢了。主要原因有几点:目前实现是由PCal翻译成的TLA+,在验证速度上肯定不如直接写的TLA+。另外不管是数据模型还是算法描述上,还有很多优化之处(比如用了很多with,很多条件需要遍历txnHistory)。
其实文中的实现也是经过我多次优化,之前的实现甚至在开发机上都没法跑出结果。所以现在用TLA+的难点在于,既需要对算法进行精确描述,同时还需要巧妙地实现技巧,否则很有可能无法跑出结果。
这部分我挪到了一个开发机上去验证,运行java tlc2.TLC -cleanup -gzip -workers 30 -config MC.cfg MC.tla,经过将近8个小时,终于完成了验证,提示NoReadOnlyAmonaly被违背了:
Error: Invariant NoReadOnlyAmonaly is violated.
Error: The behavior up to this point is:
...
State 18: <CompleteTxn line 232, col 22 to line 248, col 57 of module SnapshotIsolationPlus>
/\ txnSnapshots = ( t1 :> (k1 :> v1 @@ k2 :> Empty) @@
t2 :> (k1 :> Empty @@ k2 :> v1) @@
t3 :> (k1 :> v1 @@ k2 :> Empty) )
/\ dataStore = (k1 :> v1 @@ k2 :> v1)
/\ txnHistory = << [txnId |-> t1, type |-> "begin", time |-> 1],
[txnId |-> t1, type |-> "write", key |-> k1, val |-> v1],
[txnId |-> t2, type |-> "begin", time |-> 2],
[txnId |-> t1, type |-> "commit", time |-> 3, updatedKeys |-> {k1}],
[txnId |-> t2, type |-> "read", key |-> k1, val |-> Empty],
[txnId |-> t2, type |-> "write", key |-> k2, val |-> v1],
[txnId |-> t3, type |-> "begin", time |-> 4],
[txnId |-> t2, type |-> "commit", time |-> 5, updatedKeys |-> {k2}],
[txnId |-> t3, type |-> "read", key |-> k1, val |-> v1],
[txnId |-> t3, type |-> "read", key |-> k2, val |-> Empty],
[txnId |-> t3, type |-> "commit", time |-> 6, updatedKeys |-> {}] >>
/\ clock = 6
/\ pc = (t1 :> "LOOP" @@ t2 :> "LOOP" @@ t3 :> "LOOP")
/\ key = (t1 :> Empty @@ t2 :> Empty @@ t3 :> Empty)
4401987656 states generated, 3415241105 distinct states found, 2836798538 states left on queue.
The depth of the complete state graph search is 19.
The average outdegree of the complete state graph is 6 (minimum is 0, the maximum 17 and the 95th percentile is 9).
Finished in 07h 56min at (2022-10-17 02:44:41)
将事务提交历史画成表格,应该如下所示:
| T1 | T2 | T3 |
|---|---|---|
| Begin | ||
| W(k1) | ||
| Begin | ||
| Commit | ||
| R(k1) | ||
| W(k2) | ||
| Begin | ||
| Commit | ||
| R(k1) | ||
| R(k2) | ||
| Commit |
整体上和前面论文中举的例子非常相似。TLA+在这种形式化验证是真的有点牛逼。
最后根据这里的经验,如果我们加一个额外参数-simulate,也就是执行java tlc2.TLC -simulate -cleanup -gzip -workers 30 -config MC.cfg MC.tla居然在14秒就产生了个结果。
State 20: <CompleteTxn line 232, col 22 to line 248, col 57 of module SnapshotIsolationPlus>
/\ txnSnapshots = ( t1 :> (k1 :> Empty @@ k2 :> v1) @@
t2 :> (k1 :> Empty @@ k2 :> v1) @@
t3 :> (k1 :> v2 @@ k2 :> Empty) )
/\ dataStore = (k1 :> v2 @@ k2 :> v1)
/\ txnHistory = << [txnId |-> t3, type |-> "begin", time |-> 1],
[txnId |-> t1, type |-> "begin", time |-> 2],
[txnId |-> t1, type |-> "write", key |-> k2, val |-> v1],
[txnId |-> t3, type |-> "write", key |-> k1, val |-> v2],
[txnId |-> t3, type |-> "read", key |-> k2, val |-> Empty],
[txnId |-> t1, type |-> "commit", time |-> 3, updatedKeys |-> {k2}],
[txnId |-> t2, type |-> "begin", time |-> 4],
[txnId |-> t2, type |-> "read", key |-> k1, val |-> Empty],
[txnId |-> t3, type |-> "commit", time |-> 5, updatedKeys |-> {k1}],
[txnId |-> t2, type |-> "read", key |-> k2, val |-> v1],
[txnId |-> t2, type |-> "commit", time |-> 6, updatedKeys |-> {}] >>
/\ clock = 6
/\ pc = (t1 :> "Done" @@ t2 :> "LOOP" @@ t3 :> "Done")
/\ key = (t1 :> Empty @@ t2 :> Empty @@ t3 :> Empty)
The number of states generated: 2167752
Simulation using seed -4333842542988978264 and aril 0
Progress: 2169418 states checked.
Finished in 14s at (2022-10-17 12:16:51)
写在最后
TLA+算是入坑成功,这东西的实现技巧可能还需要再仔细钻研。
Reference
https://ses.library.usyd.edu.au/bitstream/2123/5353/1/michael-cahill-2009-thesis.pdf