DuckDB Runtime
大致总结了下DuckDB的执行流程。注意全文中算子和Operator是同义词。
Pipeline
DuckDB会将一个执行计划切分成若干个Pipeline,每个Pipeline中又包含若干算子。
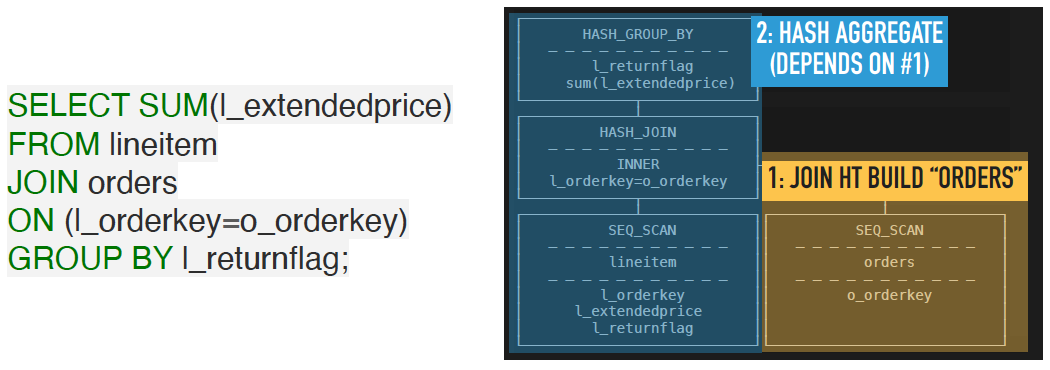
Pipeline存在有依赖关系,在上面图里的Pipeline-2,就会在Pipeline-1跑完之后才能开始跑。其中Pipeline-1最末尾的HashJoinBuild算子就是一个Pipeline breaker。
Pipeline breaker意味着这个Pipeline必须完成对所有源数据的消费之后才能返回结果。以上图中的Query为例,Hash Join中没有跑完右侧的Build之前,跑左侧的Probe是没有意义的。Pipeline breaker就是Pipeline在物理计划中划分的依据。
如果Query中间没有 Pipeline Breaker,比如SELECT * FROM orders WHERE id > 10,就可以一条流水线走到底,不需要做Pipeline之间的依赖调度。
所以 Push 模型下,调度器需要做的第一件事情,就是排列好Pipeline之间的依赖关系,使前置的Pipeline先执行完毕,再执行依赖它的 Pipeline。
然后看下Pipeline的内部结构,每个Pipeline由多个Operator组成:
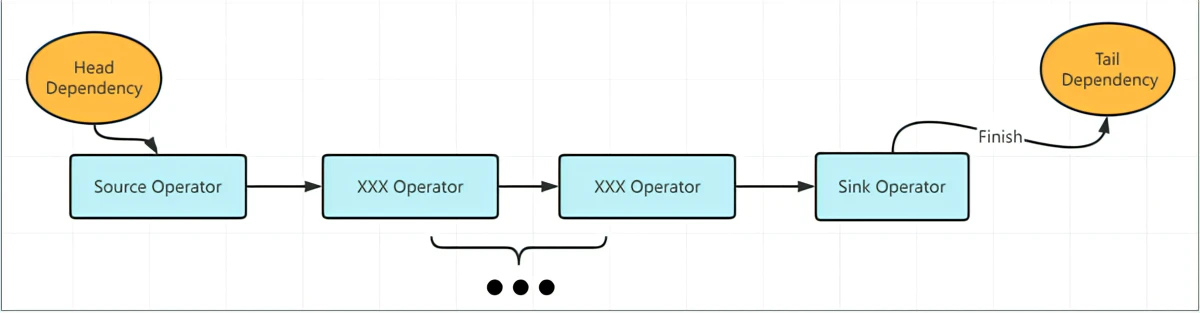
其中一定有一个Source Operator和Sink Operator,再加上中间若干无状态算子组成,在DuckDB中:
- 多线程的竞争只会发生在Sink Operator上,即parallelism-aware的算法需要实现在Sink Operator
- 其他算子(包括Source Operator), 则不需要感知多线程同步的问题
Operator
然后看下DuckDB中物理算子的核心接口,可以看到所有成员函数分成了三大块:
- Operator interface: 所有Operator公用的方法
- Source interface: Source Operator使用的方法
- Sink interface: Sink Operator使用的方法
不管是哪一类方法,都提供了全局状态和局部状态。全局状态由整个pipeline的不同执行线程共享,局部状态则由某个pipeline的执行线程独占。
- Operator interface: GlobalOperatorState, OperatorState
- Source interface: GlobalSourceState, LocalSourceState
- Sink interface: GlobalSinkState, LocalSinkState
//! PhysicalOperator is the base class of the physical operators present in the
//! execution plan
class PhysicalOperator {
public:
// ...
//! The physical operator type
PhysicalOperatorType type;
//! The set of children of the operator
vector<unique_ptr<PhysicalOperator>> children;
//! The types returned by this physical operator
vector<LogicalType> types;
//! The global sink state of this operator
unique_ptr<GlobalSinkState> sink_state;
//! The global state of this operator
unique_ptr<GlobalOperatorState> op_state;
//! Lock for (re)setting any of the operator states
mutex lock;
// ...
public:
// Operator interface
virtual unique_ptr<OperatorState> GetOperatorState(ExecutionContext &context) const;
virtual unique_ptr<GlobalOperatorState> GetGlobalOperatorState(ClientContext &context) const;
virtual OperatorResultType Execute(ExecutionContext &context, DataChunk &input, DataChunk &chunk,
GlobalOperatorState &gstate, OperatorState &state) const;
virtual OperatorFinalizeResultType FinalExecute(ExecutionContext &context, DataChunk &chunk,
GlobalOperatorState &gstate, OperatorState &state) const;
// ...
public:
// Source interface
virtual unique_ptr<LocalSourceState> GetLocalSourceState(ExecutionContext &context,
GlobalSourceState &gstate) const;
virtual unique_ptr<GlobalSourceState> GetGlobalSourceState(ClientContext &context) const;
virtual SourceResultType GetData(ExecutionContext &context, DataChunk &chunk, OperatorSourceInput &input) const;
virtual idx_t GetBatchIndex(ExecutionContext &context, DataChunk &chunk, GlobalSourceState &gstate,
LocalSourceState &lstate) const;
virtual bool IsSource() const {
return false;
}
// ...
public:
// Sink interface
//! The sink method is called constantly with new input, as long as new input is available. Note that this method
//! CAN be called in parallel, proper locking is needed when accessing data inside the GlobalSinkState.
virtual SinkResultType Sink(ExecutionContext &context, DataChunk &chunk, OperatorSinkInput &input) const;
// The combine is called when a single thread has completed execution of its part of the pipeline, it is the final
// time that a specific LocalSinkState is accessible. This method can be called in parallel while other Sink() or
// Combine() calls are active on the same GlobalSinkState.
virtual void Combine(ExecutionContext &context, GlobalSinkState &gstate, LocalSinkState &lstate) const;
//! The finalize is called when ALL threads are finished execution. It is called only once per pipeline, and is
//! entirely single threaded.
//! If Finalize returns SinkResultType::FINISHED, the sink is marked as finished
virtual SinkFinalizeType Finalize(Pipeline &pipeline, Event &event, ClientContext &context,
GlobalSinkState &gstate) const;
//! For sinks with RequiresBatchIndex set to true, when a new batch starts being processed this method is called
//! This allows flushing of the current batch (e.g. to disk)
virtual void NextBatch(ExecutionContext &context, GlobalSinkState &state, LocalSinkState &lstate_p) const;
virtual unique_ptr<LocalSinkState> GetLocalSinkState(ExecutionContext &context) const;
virtual unique_ptr<GlobalSinkState> GetGlobalSinkState(ClientContext &context) const;
//! The maximum amount of memory the operator should use per thread.
static idx_t GetMaxThreadMemory(ClientContext &context);
virtual bool IsSink() const {
return false;
}
// ...
};
我们分别介绍下这三类接口中的核心方法。
Operator Interface
DuckDB使用的是push-based execution,所以每个算子的主要工作就是给定一些数据,根据算子的功能的不同,输出一些数据。我们可以看到Execute这个核心方法,输入和输出都是一个DataChunk。
virtual OperatorResultType Execute(ExecutionContext &context,
DataChunk &input,
DataChunk &chunk,
GlobalOperatorState &gstate,
OperatorState &state) const;
所以不论是Project还是HashProbe的算子的Execute核心代码是完全相同的:
void Projection::Execute(DataChunk &input, DataChunk &result) {
executor.Execute(input, result);
}
void HashJoin::Execute(DataChunk &input, DataChunk &result) {
Probe(input, result);
}
而有的算子需要处理完所有数据才能输出结果,又或者有的算子需要用相同输入处理多次之后才能输出结果,所以Execute的返回值OperatorResultType就是用来表示这个算子当前输出的状态。
//! The OperatorResultType is used to indicate how data should flow around a regular (i.e. non-sink and non-source)
//! physical operator
//! There are four possible results:
//! NEED_MORE_INPUT means the operator is done with the current input and can consume more input if available
//! If there is more input the operator will be called with more input, otherwise the operator will not be called again.
//! HAVE_MORE_OUTPUT means the operator is not finished yet with the current input.
//! The operator will be called again with the same input.
//! FINISHED means the operator has finished the entire pipeline and no more processing is necessary.
//! The operator will not be called again, and neither will any other operators in this pipeline.
//! BLOCKED means the operator does not want to be called right now. e.g. because its currently doing async I/O. The
//! operator has set the interrupt state and the caller is expected to handle it. Note that intermediate operators
//! should currently not emit this state.
enum class OperatorResultType : uint8_t {
NEED_MORE_INPUT,
HAVE_MORE_OUTPUT,
FINISHED,
BLOCKED
};
Source Interface
核心方法是GetData
virtual SourceResultType GetData(ExecutionContext &context,
DataChunk &chunk,
OperatorSourceInput &input) const;
GetData会不断被调用,直到所有数据都输出完,或者这个pipeline被提前cancel。
Sink Interface
由于Sink Operator可能需要支持并行操作,所以它的接口最为复杂
- Sink Operator需要感知
GlobalSinkState和LocalSinkState,GlobalSinkState是整个pipeline共享,LocalSinkState则是当前线程独占 - Sink Operator需要通过
Sink,Combine,Finalize三个方法完成并发操作:- Sink会不断被调用,直到当前线程的数据都被处理完。
- 当前线程数据都被处理完,会调用
Combine。所以每个线程只会调用一次Combine,从而生成当前线程的LocalSinkState。 - 当所有线程都调用过
Combine之后,会调用Finalize,每个pipeline只会调用一次Finalize,把各个线程的LocalSinkState合并到GlobalSinkState。
//! The sink method is called constantly with new input, as long as new input is available. Note that this method
//! CAN be called in parallel, proper locking is needed when accessing data inside the GlobalSinkState.
virtual SinkResultType Sink(ExecutionContext &context, DataChunk &chunk, OperatorSinkInput &input) const;
// The combine is called when a single thread has completed execution of its part of the pipeline, it is the final
// time that a specific LocalSinkState is accessible. This method can be called in parallel while other Sink() or
// Combine() calls are active on the same GlobalSinkState.
virtual void Combine(ExecutionContext &context, GlobalSinkState &gstate, LocalSinkState &lstate) const;
//! The finalize is called when ALL threads are finished execution. It is called only once per pipeline, and is
//! entirely single threaded.
//! If Finalize returns SinkResultType::FINISHED, the sink is marked as finished
virtual SinkFinalizeType Finalize(Pipeline &pipeline, Event &event, ClientContext &context,
GlobalSinkState &gstate) const;
DuckDB Runtime
Pipeline并发
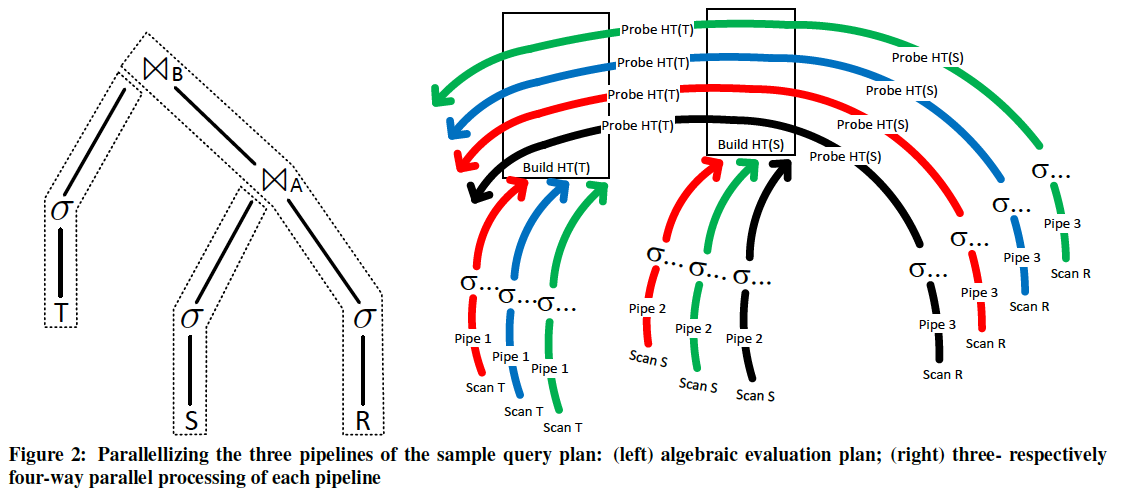
到这我们就能解释DuckDB的并发机制了,DuckDB和Velox一样,支持Pipeline的并发执行。支持的方式的大体思想类似,都是通过多个线程并发执行pipeline的上的算子,二者不同之处在于:
- Velox是显式的根据pipeline生成了多个Driver,每一个Driver是一个最小调度单位,在一个线程中进行push-based execution。因此每个算子归属于Driver,因此Velox中的算子实现都是有状态的。
- DuckDB的算子则归属于Pipeline,算子本身是无状态的(状态信息都保存在了全局状态和局部状态中)。因此可以看到DuckDB的注释中,所有并发描述的单位都是thread。
Pipeline调度
pipeline之间可能有依赖关系,比如HashBuild和HashProbe就有先后依赖关系。DuckDB的调度逻辑和拓扑排序非常相似,某个pipeline只有其所有依赖的pipeline都执行完之后,才能开始执行。
具体来说,DuckDB是通过Pipeline Event来进行pipeline的调度的。DuckDB会把Pipeline切分为若干Event,Event分为以下几种。
PipelineInitializeEventPipelineEventPipelineFinishEventPipelineCompleteEvent
每一种Event作用不同:
PipelineInitializeEvent负责构造PipelineInitializeTask,然后将Task入队列等待调度PipelineEvent负责构造PipelineTask,然后将Task入队列等待调度PipelineFinishEvent负责调用SinkOperator的FinalizePipelineCompleteEvent负责标记Pipeline已经执行完成
根据Pipeline之间的依赖关系,这些Event之间是可以构造出一个有向无环图DAG的。Event的调度算法基本就是拓扑排序,先调度那些没有任何依赖的Event。当某个Event完成时,会通知依赖这个Event的父亲Event,如果父亲Event检查到它的所有依赖都已经完成,那么父亲Event就可以入队列等待调度了。
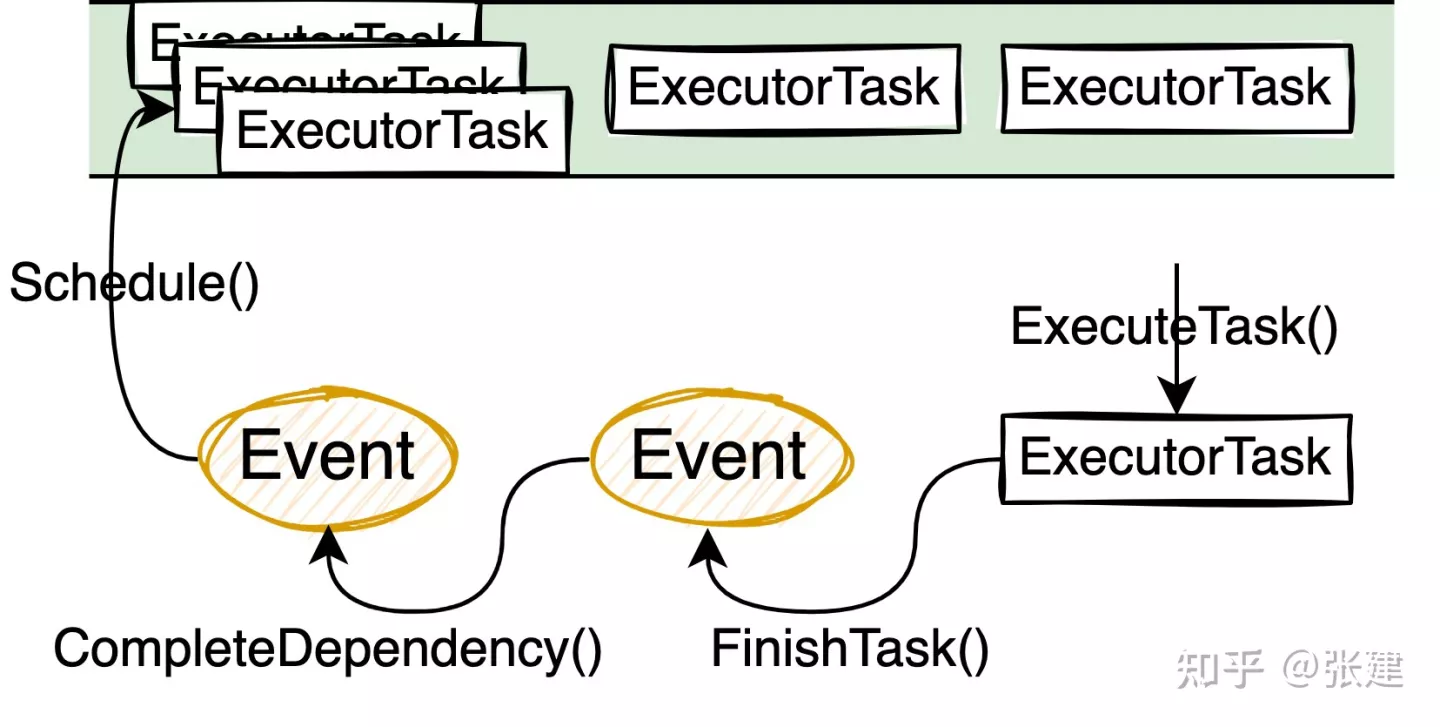
调度的逻辑比较简单就是不断从队列中取Task执行,直到完成,相关代码在Executor**::**ExecuteTask()中。
我们再结合两个例子看一下:
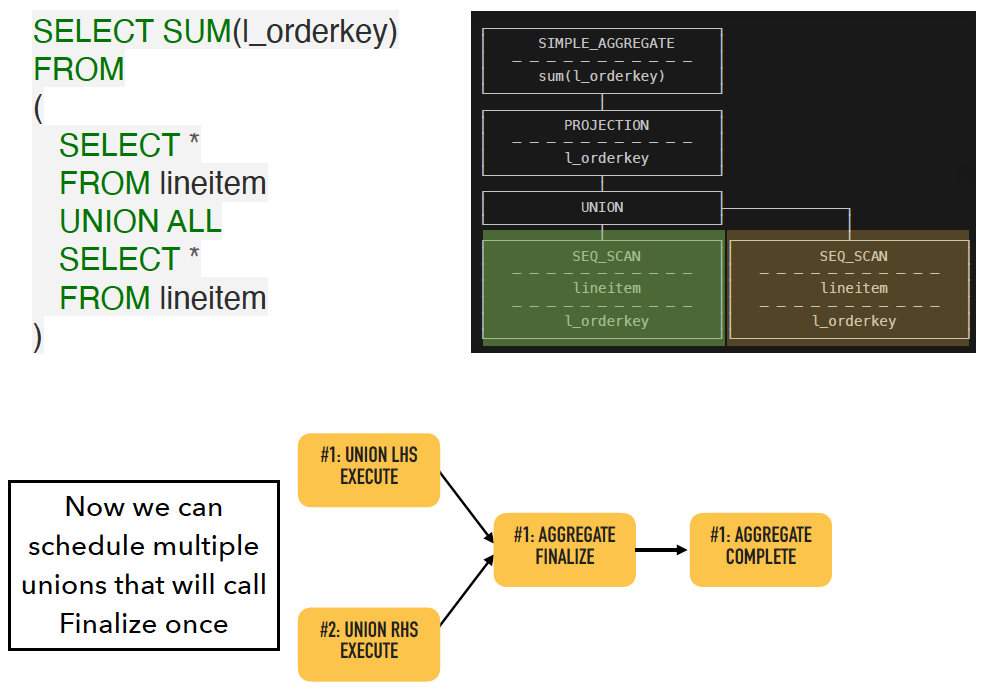
比如上面这个SQL,Aggregate的FinishEvent需要等待两个Union执行完成。当两个Union执行完之后,就可以调用Aggregate所在Pipeline的Finalize了。
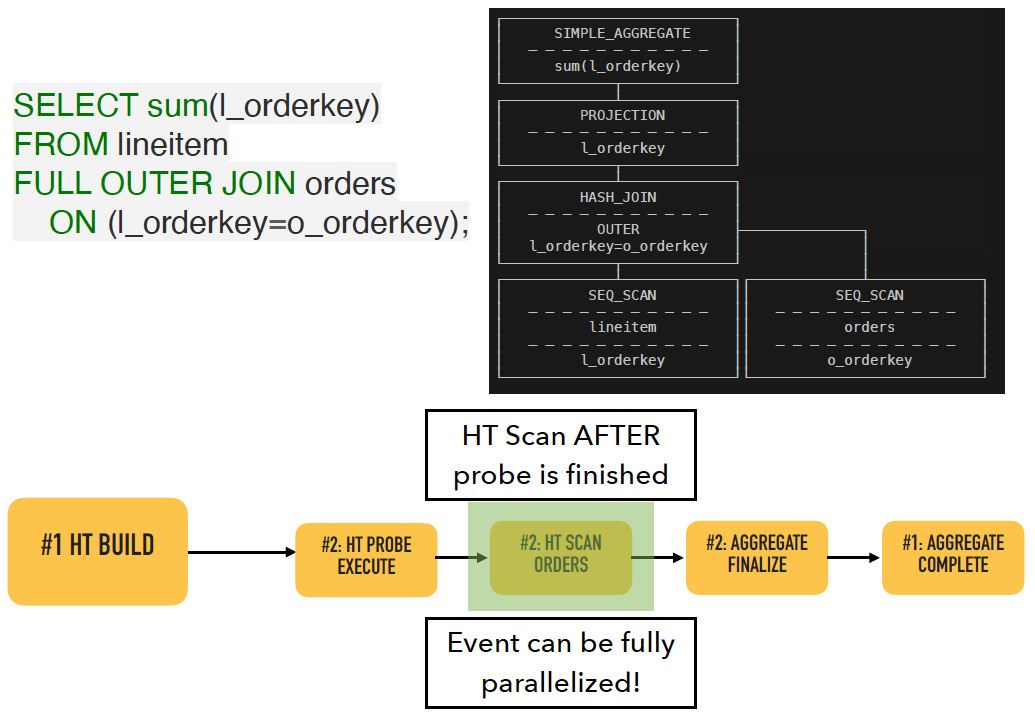
同理,对于HashJoin来说,需要先执行HashBuild,再执行HashProbe。
Pull-based vs Push-based execution
DuckDB最早也是pull,后来才改为了push模型。Velox也是使用了push模型。Query Engines: Push vs. Pull (justinjaffray.com) 这个文比较详细的对比了两种模型。两种模型我也都在NebulaGraph中有所实践过,所以从工程角度我也谈谈我的想法:
-
数据流向不同
这一点从根本上就决定pull模型会容易实现很多。pull模型中,每个算子只需要不断向它的孩子索要数据,然后加以处理即可,算子不需要关心数据从哪来到哪去。一旦要求根节点返回数据,就会不断层层向下询问,直至最终返回结果。这个过程简单直接,算子之间基本只会是树形结构。与之带来的问题就是,想要调度或者打断这个过程会比较困难。
而在push模型中,数据从当前算子输出到下一个算子时,可能遇到各种各样的情形:下一个算子被阻塞了或者还没处理完上一批数据,又或者下一个算子是一个特殊算子(比如DuckDB的SinkOperator)等等情况。所有这些情况需要统一的处理方式,因此push模型中基本都会有一个centralized的地方来处理算子之间的逻辑,比如DuckDB中的Executor,Velox中的Driver等等。通过统一的逻辑,处理算子之间以及pipeline之间的数据流向。而往往push模型能够比较方便的支持DAG形式的执行流程,或者是增加并发能力,导致实现难度大大上升。
-
线程模型不同
pull模型的执行流程非常直观,更适合于单线程执行。想要支持并发,往往都是根据数据分片生成多个子树,另外可能在一部分特殊算子内部做并发。其难点在于算子之间需要能够互相同步进度,而pull模型不容易控制算子执行的进度。另外若干子树会导致执行计划变得非常庞大,可能会伴随大量物化,整体上并发能力有限。
push模型由于有一个centralized的地方控制算子执行,所有需要算子之间的数据流动不再由算子来驱动。在统一的逻辑中,能够方便的同步算子之间的进度,进而支持并发,因此push模型相比之下会更容易做多线程执行。
-
调度方式的不同
前面也提到,pull模型只有在驱动执行计划的根节点之后,才能够由算子不断递归向下获取数据。在这个模型下,能做的调度仅限于什么时候开始执行这个查询。而一旦开始这个流程中,由于缺少调度器,无法直接调度各个算子如何执行。这其中包括,无法控制算子在哪个线程池执行,无法随意打断执行的流程,不容易根据CPU和内存等系统资源调度算子的执行。
而push模型能够比较方便的基于pipeline和算子进行调度,pipeline中的各个算子执行与否,是由centralized逻辑控制。因此相比pull模型,push模型的调度能力是更强的。
Reference
Morsel-Driven Parallelism: A NUMA-Aware Query Evaluation Framework for the Many-Core Age
duckdb-dsdsd-push-based (cwi.nl)
[DuckDB] Push-Based Execution Model - 知乎 (zhihu.com)
Notes on Duckdb: Build Pipelines - 知乎 (zhihu.com)