When does RocksDB delete a wal?
最近调查我们测试环境的RocksDB WAL出现了大量积压,研究了下RocksDB文件清理的相关逻辑。我们使用的版本为7.8.3。
背景知识
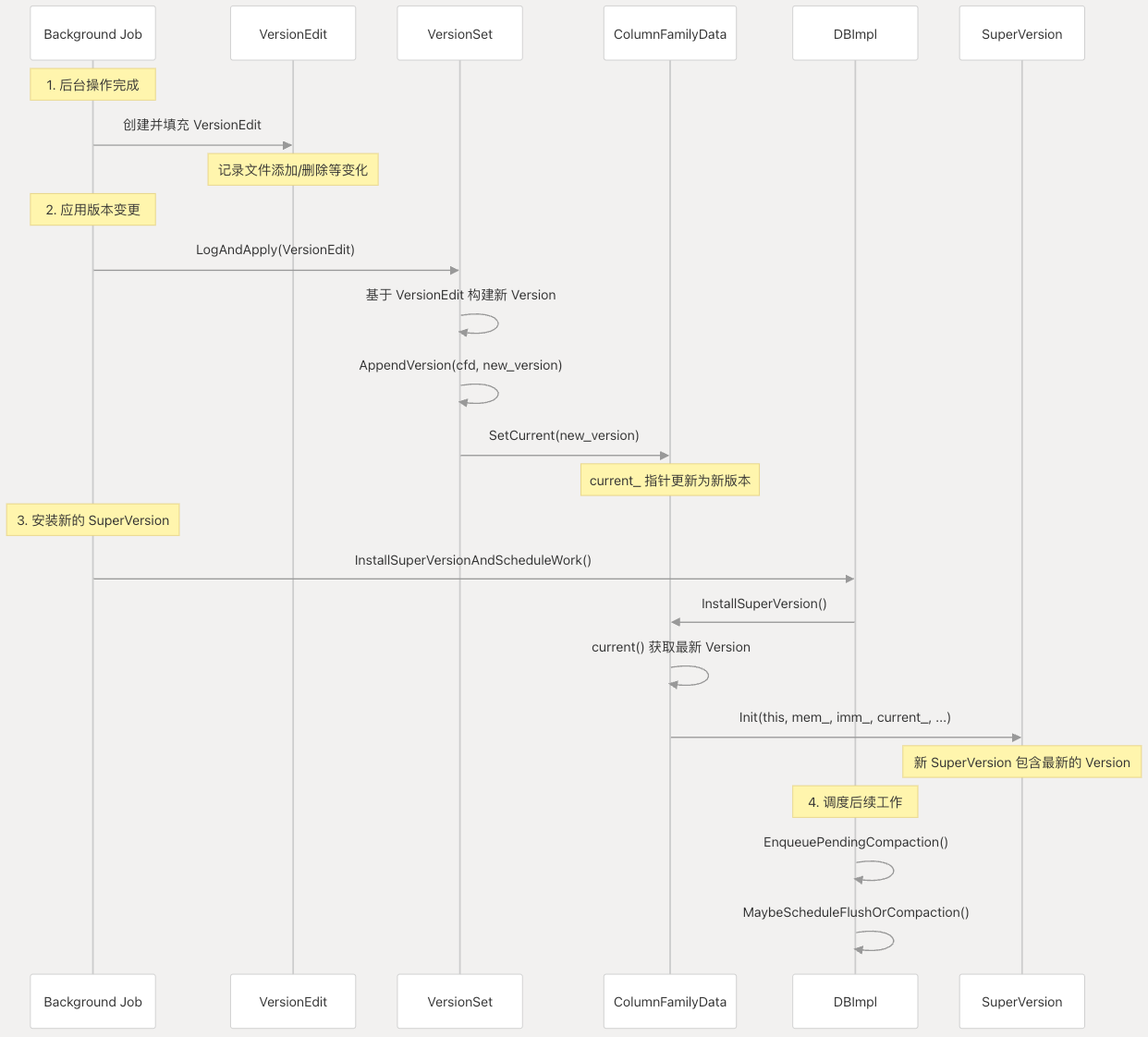
为了更好理解,先补充一下RocksDB中几个概念:Version、VersionEdit、VersionSet以及SuperVersion。
Version是某个特定时间点的SST文件状态(不包含Memtable)。多个Version行程一个链表,由VersionSet管理当钱版本和历史版本。如果要修改Version,则是通过一个Version加上对应的修改VersionEdit,生成一个新的Version,进而保存到VersionSet中。
SuperVersion包含RocksDB某个时间点的完整视图,包括当前最新的Version以及所有active和inactive memtable。所有调用InstallSuperVersionAndScheduleWork都代表SuperVersion发生了变化,以下情况都会触发SuperVersion发生变化:
- Open
- Flush
- Compaction
- SetOptions
- Create column family
- Ingest
我们以Flush和Compaction为例,能够更好的理解以上几个概念是怎么一起协作的。Flush/Compaction会创建新的SST文件或者删除老的SST,这些SST文件的变化会记录在VersionEdit中 ,然后将VersionEdit应用到VersionSet中当前最新的Version之后,就会产生一个新的Version,并更新ColumnFamilyData中的指针。之后就会调用InstallSuperVersionAndScheduleWork,更新SuperVersion。
确定过期文件
有了相关背景之后,再来看文件清理是什么时候触发的:
- 关闭RocksDB
- Flush完成之后
- Compaction完成之后
在以上这些地方,都会调用FindObsoleteFiles先确定哪些文件已经过期。FindObsoleteFiles会根据相关参数,决定是否要进行full scan,即是否要主动扫描相关路径。满足下面任意条件会进行full scan:
- 如果
force = true(关闭RocksDB,Flush/Compaction失败情况下会指定) - 如果
delete_obsolete_files_period_micros为0,或者距上次full scan的时间已经超过delete_obsolete_files_period_micros
void DBImpl::FindObsoleteFiles(JobContext* job_context, bool force,
bool no_full_scan) {
// ...
bool doing_the_full_scan = false;
// logic for figuring out if we're doing the full scan
if (no_full_scan) {
doing_the_full_scan = false;
} else if (force ||
mutable_db_options_.delete_obsolete_files_period_micros == 0) {
doing_the_full_scan = true;
} else {
const uint64_t now_micros = immutable_db_options_.clock->NowMicros();
if ((delete_obsolete_files_last_run_ +
mutable_db_options_.delete_obsolete_files_period_micros) <
now_micros) {
doing_the_full_scan = true;
delete_obsolete_files_last_run_ = now_micros;
}
}
// ...
}
然后FindObsoleteFiles会通过VersionSet::GetObsoleteFiles确定哪些文件已经过期:
void VersionSet::GetObsoleteFiles(std::vector<ObsoleteFileInfo>* files,
std::vector<ObsoleteBlobFileInfo>* blob_files,
std::vector<std::string>* manifest_filenames,
uint64_t min_pending_output) {
assert(files);
assert(blob_files);
assert(manifest_filenames);
assert(files->empty());
assert(blob_files->empty());
assert(manifest_filenames->empty());
std::vector<ObsoleteFileInfo> pending_files;
for (auto& f : obsolete_files_) {
if (f.metadata->fd.GetNumber() < min_pending_output) {
files->emplace_back(std::move(f));
} else {
pending_files.emplace_back(std::move(f));
}
}
obsolete_files_.swap(pending_files);
std::vector<ObsoleteBlobFileInfo> pending_blob_files;
for (auto& blob_file : obsolete_blob_files_) {
if (blob_file.GetBlobFileNumber() < min_pending_output) {
blob_files->emplace_back(std::move(blob_file));
} else {
pending_blob_files.emplace_back(std::move(blob_file));
}
}
obsolete_blob_files_.swap(pending_blob_files);
obsolete_manifests_.swap(*manifest_filenames);
}
可以看到所有过期数据都是从obsolete_files_中获取到的,而obsolete_files_则是在Version的析构处进行更新,也就是某个Version已经过期,且确定没有被使用之后,即可将这些文件标记为过期:
Version::~Version() {
assert(refs_ == 0);
// Remove from linked list
prev_->next_ = next_;
next_->prev_ = prev_;
// Drop references to files
for (int level = 0; level < storage_info_.num_levels_; level++) {
for (size_t i = 0; i < storage_info_.files_[level].size(); i++) {
FileMetaData* f = storage_info_.files_[level][i];
assert(f->refs > 0);
f->refs--;
if (f->refs <= 0) {
assert(cfd_ != nullptr);
uint32_t path_id = f->fd.GetPathId();
assert(path_id < cfd_->ioptions()->cf_paths.size());
vset_->obsolete_files_.push_back(
ObsoleteFileInfo(f, cfd_->ioptions()->cf_paths[path_id].path,
cfd_->GetFileMetadataCacheReservationManager()));
}
}
}
}
GetObsoleteFiles之后,会将每个已经过期的文件打上一个标记。
void DBImpl::FindObsoleteFiles(JobContext* job_context, bool force,
bool no_full_scan) {
// ...
// Get obsolete files. This function will also update the list of
// pending files in VersionSet().
versions_->GetObsoleteFiles(
&job_context->sst_delete_files, &job_context->blob_delete_files,
&job_context->manifest_delete_files, job_context->min_pending_output);
// Mark the elements in job_context->sst_delete_files and
// job_context->blob_delete_files as "grabbed for purge" so that other threads
// calling FindObsoleteFiles with full_scan=true will not add these files to
// candidate list for purge.
for (const auto& sst_to_del : job_context->sst_delete_files) {
MarkAsGrabbedForPurge(sst_to_del.metadata->fd.GetNumber());
}
for (const auto& blob_file : job_context->blob_delete_files) {
MarkAsGrabbedForPurge(blob_file.GetBlobFileNumber());
}
// ...
}
full scan
对于full scan,会根据db_paths扫描每个路径下所有文件(包括SST、WAL、OPTION、MANIFEST等),解析文件名。并通过ShouldPurge确定是否过期,并保存到full_scan_candidate_files中。相关逻辑如下:
void DBImpl::FindObsoleteFiles(JobContext* job_context, bool force,
bool no_full_scan) {
// ...
if (doing_the_full_scan) {
// 根据db_paths扫描每个路径下所有文件...
for (auto& path : paths) {
// set of all files in the directory. We'll exclude files that are still
// alive in the subsequent processings.
std::vector<std::string> files;
Status s = immutable_db_options_.fs->GetChildren(
path, io_opts, &files, /*IODebugContext*=*/nullptr);
s.PermitUncheckedError(); // TODO: What should we do on error?
for (const std::string& file : files) {
uint64_t number;
FileType type;
// 1. If we cannot parse the file name, we skip;
// 2. If the file with file_number equals number has already been
// grabbed for purge by another compaction job, or it has already been
// schedule for purge, we also skip it if we
// are doing full scan in order to avoid double deletion of the same
// file under race conditions. See
// https://github.com/facebook/rocksdb/issues/3573
if (!ParseFileName(file, &number, info_log_prefix.prefix, &type) ||
!ShouldPurge(number)) {
continue;
}
// TODO(icanadi) clean up this mess to avoid having one-off "/"
// prefixes
job_context->full_scan_candidate_files.emplace_back("/" + file, path);
}
}
// ...
} else {
versions_->RemoveLiveFiles(job_context->sst_delete_files,
job_context->blob_delete_files);
}
// ...
}
not full scan
如果不是full scan,则调用VersionSet::RemoveLiveFiles,其中又会调用Version::RemoveLiveFiles:
void VersionSet::RemoveLiveFiles(
std::vector<ObsoleteFileInfo>& sst_delete_candidates,
std::vector<ObsoleteBlobFileInfo>& blob_delete_candidates) const {
assert(column_family_set_);
for (auto cfd : *column_family_set_) {
assert(cfd);
if (!cfd->initialized()) {
continue;
}
auto* current = cfd->current();
bool found_current = false;
Version* const dummy_versions = cfd->dummy_versions();
assert(dummy_versions);
for (Version* v = dummy_versions->next_; v != dummy_versions;
v = v->next_) {
v->RemoveLiveFiles(sst_delete_candidates, blob_delete_candidates);
if (v == current) {
found_current = true;
}
}
if (!found_current && current != nullptr) {
// Should never happen unless it is a bug.
assert(false);
current->RemoveLiveFiles(sst_delete_candidates, blob_delete_candidates);
}
}
}
void Version::RemoveLiveFiles(
std::vector<ObsoleteFileInfo>& sst_delete_candidates,
std::vector<ObsoleteBlobFileInfo>& blob_delete_candidates) const {
for (ObsoleteFileInfo& fi : sst_delete_candidates) {
if (!fi.only_delete_metadata &&
storage_info()->GetFileLocation(fi.metadata->fd.GetNumber()) !=
VersionStorageInfo::FileLocation::Invalid()) {
fi.only_delete_metadata = true;
}
}
blob_delete_candidates.erase(
std::remove_if(
blob_delete_candidates.begin(), blob_delete_candidates.end(),
[this](ObsoleteBlobFileInfo& x) {
return storage_info()->GetBlobFileMetaData(x.GetBlobFileNumber());
}),
blob_delete_candidates.end());
}
非full scan模式下,也会查找哪些WAL过期。分为两部分:
alive_log_files_维护所有仍然活跃的WAL,包含可能没有Flush的Memtable对应的WAL,以及正在写入的WAL。过期的WAL会保存到JobContext的log_delete_files中。logs_维护当前正在写入的WAL,以及没有Sync的WAL。过期的WAL会保存到JobContext的logs_to_free中。
默认RocksDB是不会回收WAL的,我们暂不讨论回收WAL,即代码中
recycle_log_file_num非0相关逻辑
void DBImpl::FindObsoleteFiles(JobContext* job_context, bool force,
bool no_full_scan) {
// ...
if (!alive_log_files_.empty() && !logs_.empty()) {
uint64_t min_log_number = job_context->log_number;
size_t num_alive_log_files = alive_log_files_.size();
// find newly obsoleted log files
while (alive_log_files_.begin()->number < min_log_number) {
auto& earliest = *alive_log_files_.begin();
if (immutable_db_options_.recycle_log_file_num >
log_recycle_files_.size()) {
ROCKS_LOG_INFO(immutable_db_options_.info_log,
"adding log %" PRIu64 " to recycle list\n",
earliest.number);
log_recycle_files_.push_back(earliest.number);
} else {
job_context->log_delete_files.push_back(earliest.number);
}
if (job_context->size_log_to_delete == 0) {
job_context->prev_total_log_size = total_log_size_;
job_context->num_alive_log_files = num_alive_log_files;
}
job_context->size_log_to_delete += earliest.size;
total_log_size_ -= earliest.size;
alive_log_files_.pop_front();
// Current log should always stay alive since it can't have
// number < MinLogNumber().
assert(alive_log_files_.size());
}
log_write_mutex_.Unlock();
mutex_.Unlock();
log_write_mutex_.Lock();
while (!logs_.empty() && logs_.front().number < min_log_number) {
auto& log = logs_.front();
if (log.IsSyncing()) {
log_sync_cv_.Wait();
// logs_ could have changed while we were waiting.
continue;
}
logs_to_free_.push_back(log.ReleaseWriter());
logs_.pop_front();
}
// Current log cannot be obsolete.
assert(!logs_.empty());
}
// ...
}
删除过期文件
通过FindObsoleteFiles确定了哪些文件是过期之后,之后会在PurgeObsoleteFiles中进行实际删除。
首先会对检查JobContext中的sst_delete_files、blob_delete_files、log_delete_files和manifest_delete_files,加到最终的删除列表candidate_files中。对于SST会额外检查是否还有Version在使用这个SST。之后对candidate_files进行排序和去重:
// dedup state.candidate_files so we don't try to delete the same
// file twice
std::sort(candidate_files.begin(), candidate_files.end(),
[](const JobContext::CandidateFileInfo& lhs,
const JobContext::CandidateFileInfo& rhs) {
if (lhs.file_name > rhs.file_name) {
return true;
} else if (lhs.file_name < rhs.file_name) {
return false;
} else {
return (lhs.file_path > rhs.file_path);
}
});
candidate_files.erase(
std::unique(candidate_files.begin(), candidate_files.end()),
candidate_files.end());
最后会根据schedule_only,确定是在后台线程进行删除,还是立即删除。
void DBImpl::PurgeObsoleteFiles(JobContext& state, bool schedule_only) {
// ...
for (const auto& candidate_file : candidate_files) {
if (schedule_only) {
InstrumentedMutexLock guard_lock(&mutex_);
SchedulePendingPurge(fname, dir_to_sync, type, number, state.job_id);
} else {
DeleteObsoleteFileImpl(state.job_id, fname, dir_to_sync, type, number);
}
}
}
schedule_only默认以及绝大多数场景下都是false,即通过DeleteObsoleteFileImpl立即删除。
// Delete obsolete files and log status and information of file deletion
void DBImpl::DeleteObsoleteFileImpl(int job_id, const std::string& fname,
const std::string& path_to_sync,
FileType type, uint64_t number) {
TEST_SYNC_POINT_CALLBACK("DBImpl::DeleteObsoleteFileImpl::BeforeDeletion",
const_cast<std::string*>(&fname));
Status file_deletion_status;
if (type == kTableFile || type == kBlobFile || type == kWalFile) {
// Rate limit WAL deletion only if its in the DB dir
file_deletion_status = DeleteDBFile(
&immutable_db_options_, fname, path_to_sync,
/*force_bg=*/false,
/*force_fg=*/(type == kWalFile) ? !wal_in_db_path_ : false);
} else {
file_deletion_status = env_->DeleteFile(fname);
}
// ...
}
什么时候会进行文件清理
前面提到,RocksDB会在Flush或者Compact完成后,调用FindObsoleteFiles确定哪些文件已经过期,进而在PurgeObsoleteFiles中进行实际删除。这一部分,我们仔细看下相关函数是具体在什么时候被调用的。
首先在RocksDB中有两个队列flush_queue_和compaction_queue_,它们分别保存需要Flush和Compaction的Column family。当Column family满足条件cfd->imm()->IsFlushPending()时,它会被插入到flush_queue_队列中。当Column family满足条件cfd->NeedsCompaction()时,它会被插入到compaction_queue_队列中。
std::deque<FlushRequest> flush_queue_;
std::deque<ColumnFamilyData*> compaction_queue_;
每当Column Family被加入到队列中后,就会增加unscheduled_flushes_和unscheduled_compactions_。当这两个变量大于0时,就会增加和调度背景线程用于执行Flush或者Compaction。当Flush和Compaction完成之后,就会减小unscheduled_flushes_和unscheduled_compactions_。
Flush和Compaction的相关调度逻辑都在MaybeScheduleFlushOrCompaction这个函数中。通过检查是否有仍未调度的Flush或者Compaction,以及是否还有足够线程,进而调度BGWorkFlush和BGWorkCompaction。
void DBImpl::MaybeScheduleFlushOrCompaction() {
mutex_.AssertHeld();
// ...
auto bg_job_limits = GetBGJobLimits();
bool is_flush_pool_empty =
env_->GetBackgroundThreads(Env::Priority::HIGH) == 0;
while (!is_flush_pool_empty && unscheduled_flushes_ > 0 &&
bg_flush_scheduled_ < bg_job_limits.max_flushes) {
bg_flush_scheduled_++;
FlushThreadArg* fta = new FlushThreadArg;
fta->db_ = this;
fta->thread_pri_ = Env::Priority::HIGH;
env_->Schedule(&DBImpl::BGWorkFlush, fta, Env::Priority::HIGH, this,
&DBImpl::UnscheduleFlushCallback);
--unscheduled_flushes_;
TEST_SYNC_POINT_CALLBACK(
"DBImpl::MaybeScheduleFlushOrCompaction:AfterSchedule:0",
&unscheduled_flushes_);
}
// special case -- if high-pri (flush) thread pool is empty, then schedule
// flushes in low-pri (compaction) thread pool.
if (is_flush_pool_empty) {
while (unscheduled_flushes_ > 0 &&
bg_flush_scheduled_ + bg_compaction_scheduled_ <
bg_job_limits.max_flushes) {
bg_flush_scheduled_++;
FlushThreadArg* fta = new FlushThreadArg;
fta->db_ = this;
fta->thread_pri_ = Env::Priority::LOW;
env_->Schedule(&DBImpl::BGWorkFlush, fta, Env::Priority::LOW, this,
&DBImpl::UnscheduleFlushCallback);
--unscheduled_flushes_;
}
}
// ...
while (bg_compaction_scheduled_ + bg_bottom_compaction_scheduled_ <
bg_job_limits.max_compactions &&
unscheduled_compactions_ > 0) {
CompactionArg* ca = new CompactionArg;
ca->db = this;
ca->compaction_pri_ = Env::Priority::LOW;
ca->prepicked_compaction = nullptr;
bg_compaction_scheduled_++;
unscheduled_compactions_--;
env_->Schedule(&DBImpl::BGWorkCompaction, ca, Env::Priority::LOW, this,
&DBImpl::UnscheduleCompactionCallback);
}
}
相关线程数的阈值在这里设置的:
DBImpl::BGJobLimits DBImpl::GetBGJobLimits(int max_background_flushes,
int max_background_compactions,
int max_background_jobs,
bool parallelize_compactions) {
BGJobLimits res;
if (max_background_flushes == -1 && max_background_compactions == -1) {
// for our first stab implementing max_background_jobs, simply allocate a
// quarter of the threads to flushes.
res.max_flushes = std::max(1, max_background_jobs / 4);
res.max_compactions = std::max(1, max_background_jobs - res.max_flushes);
} else {
// compatibility code in case users haven't migrated to max_background_jobs,
// which automatically computes flush/compaction limits
res.max_flushes = std::max(1, max_background_flushes);
res.max_compactions = std::max(1, max_background_compactions);
}
if (!parallelize_compactions) {
// throttle background compactions until we deem necessary
res.max_compactions = 1;
}
return res;
}
FindObsoleteFiles这个函数在以下场景会被调用:
MaybeScheduleFlushOrCompaction→BGWorkCompaction→BackgroundCallCompaction→BackgroundCompactionMaybeScheduleFlushOrCompaction→BGWorkFlush→BackgroundCallFlush→BackgroundFlush
手动的DBImpl::Flush不会直接调用FindObsoleteFiles,但它会在flush_queue_队列中增加一个Flush任务等待调度,当DBImpl::BackgroundCallFlush中调度Flush完成之后,就会调用FindObsoleteFiles确定过期文件。手动Compaction同理。
Review
到这文件清理的相关逻辑已经梳理完了,回到文章开头说到的问题。我们测试环境下出现了WAL积压,且积压现象都出现在开始大量导入的时候。但即便导入结束很久,仍然发现目录中有大量的WAL文件,且CPU等资源使用也一直为0。通过gdb可以看到所有背景线程都被阻塞在一个condition variable上:
Thread 59 (Thread 0x7fb170fff700 (LWP 2920611)):
#0 futex_wait_cancelable (private=<optimized out>, expected=0, futex_word=0x7fb185e032d0) at ../sysdeps/nptl/futex-internal.h:183
#1 __pthread_cond_wait_common (abstime=0x0, clockid=0, mutex=0x7fb185e03280, cond=0x7fb185e032a8) at pthread_cond_wait.c:508
#2 __pthread_cond_wait (cond=0x7fb185e032a8, mutex=0x7fb185e03280) at pthread_cond_wait.c:647
#3 0x00007fb1f13d1e30 in std::condition_variable::wait(std::unique_lock<std::mutex>&) () from../3rd/libstdc++.so.6
#4 0x00007fb1ef1792bc in rocksdb::ThreadPoolImpl::Impl::BGThread(unsigned long) () from ../3rd/librocksdb.so.7
#5 0x00007fb1ef179663 in rocksdb::ThreadPoolImpl::Impl::BGThreadWrapper(void*) () from ../3rd/librocksdb.so.7
#6 0x00007fb1f13d7df4 in ?? () from ../3rd/libstdc++.so.6
#7 0x00007fb1f12c2609 in start_thread (arg=<optimized out>) at pthread_create.c:477
#8 0x00007fb1f11e7353 in clone () at ../sysdeps/unix/sysv/linux/x86_64/clone.S:95
而更诡异的是,只要手动进行一次FLush,相关的WAL就全部释放了。对于这个现象,我猜想有几种可能:
- 在导入的某个时间点之后,再也没有执行后台的Flush/Compaction,即
unscheduled_flushes_和unscheduled_compactions_一直为0。 - 由于
max_background_jobs设置的很小,远小于RocksDB实例的数量,导致相关任务被阻塞。这个猜测整体上最符合现象,但阻塞不应该永远存在。而在测试环境下,导入结束很长一段时间内,观察到CPU和磁盘IO一直为0。如果存在相关的Flush和Compaction任务,也不应该被阻塞那么久。除非这个线程池因为Bug,导致其中所有线程都被阻塞了。
然而当调大max_background_jobs之后,这个现象依然存在,也就排除了后者,只可能某个时间点之后再也没有执行后台的Flush/Compaction。换而言之,我的环境中出现wal积压是因为某些未知的机制,导致没有Flush造成的。
其实我本应该很早就意识到这个地方,但由于我一直被上面的栈所误导,以为是被
DBImpl中的某个条件变量被阻塞。所以第一时间就追各种代码链路,反而完全忽略掉了背景线程中没有任何后台任务时也会出现阻塞的情况。直到我去github上提了个issue,才有人把我点醒。
到这我们整理一下WAL的生命周期。每次RocksDB的写入会先写入WAL用于持久化,然后再写入Memtable。一个WAL文件会负责持久化所有Column Family。每次当某个Column Family需要Flush的时候,就会创建一个新的WAL。而一个WAL的删除,需要等待所有Column Family把WAL中最大sequence number对应的数据都Flush为SST之后才能删除。即,所有WAL都要等待对应数据被持久化为SST之后才能删除。这里有几个相关配置:
DBOptions::max_total_wal_size可以限制RocksDB的WAL大小,一旦WAL的总大小超过该设定值,RocksDB将强制刷新Column Family以删除部分最早的WAL文件。当各Column Family的写入频率不均衡时,这个配置就会很有用。如果使用默认值或者配置一个很大的值,只要有Column Family长时间不执行flush,RocksDB会一直保留相关的WAL。由于WAL是被多个Column Family共享,也就会导致积压大量的WAL。- 如果想查看当前需要保留的最小WAL的ID,可以通过
rocksdb.min-log-number-to-keep来查看。
WAL的删除时机可以结合wiki中这句话进行理解:A WAL is deleted (or archived if archival is enabled) when all column families have flushed beyond the largest sequence number contained in the WAL, or in other words, all data in the WAL have been persisted to SST files.
如果max_total_wal_size为默认值,则使用max_total_in_memory_state_的4倍作为返回值,而max_total_in_memory_state_是由所有Column Family的Memtable大小乘以个数求和而得。
uint64_t DBImpl::GetMaxTotalWalSize() const {
uint64_t max_total_wal_size =
max_total_wal_size_.load(std::memory_order_acquire);
if (max_total_wal_size > 0) {
return max_total_wal_size;
}
return 4 * max_total_in_memory_state_.load(std::memory_order_acquire);
}
当每次写入时,如果检查到WAL的大小比GetMaxTotalWalSize大,就会调用SwitchWAL创建一个新的WAL。
Status DBImpl::PreprocessWrite(const WriteOptions& write_options,
LogContext* log_context,
WriteContext* write_context) {
// ...
if (UNLIKELY(status.ok() && total_log_size_ > GetMaxTotalWalSize())) {
assert(versions_);
InstrumentedMutexLock l(&mutex_);
const ColumnFamilySet* const column_families =
versions_->GetColumnFamilySet();
assert(column_families);
size_t num_cfs = column_families->NumberOfColumnFamilies();
assert(num_cfs >= 1);
if (num_cfs > 1) {
WaitForPendingWrites();
status = SwitchWAL(write_context);
}
}
// ...
}
SwitchWAL主要分为几步:
- 对每个Column Family调用
SwitchMemtable生成新的Memtable,其中会调用CreateWAL生成新的WAL - 生成新的Flush请求,提交后台进行调度
- 由于每次Flush就会生成新的SST,所以还需要调用
MaybeScheduleFlushOrCompaction,触发可能需要进行的Compaction等
不过在我的环境中,SwitchWAL里的这条日志从来没有打印过。也就是说我并没有因为WAL的总大小超过限制而触发过SwitchWAL以及后续的Flush和WAL删除。
ROCKS_LOG_INFO(
immutable_db_options_.info_log,
"Flushing all column families with data in WAL number %" PRIu64
". Total log size is %" PRIu64 " while max_total_wal_size is %" PRIu64,
oldest_alive_log, total_log_size_.load(), GetMaxTotalWalSize());
既然没有从SwitchWAL这里删除,那么我的环境下WAL是什么时候才能删除呢?注意到WAL是被所有Column Family被共享,而由于我的多个Column Family的写入频率不同,导致某个更新频率较低的Column Family的Memtable中一直没有进行Flush,进而导致这个Memtable关联的WAL无法被删除。解决办法也很简单,首先需要合理设置max_total_wal_size,这样就能更频繁的调用SwitchWAL来触发Flush,也就能更快删除掉积压的WAL。
另外在调整
max_total_wal_size之后,可以考虑把atomic_flush设置为true。
Reference
https://github.com/facebook/rocksdb/wiki/Write-Ahead-Log-%28WAL%29#life-cycle-of-a-wal