rocksdb delete range
RocksDB的DeleteRange代码走读。
写流程
Status DB::DeleteRange(const WriteOptions& opt,
ColumnFamilyHandle* column_family,
const Slice& begin_key, const Slice& end_key) {
WriteBatch batch;
Status s = batch.DeleteRange(column_family, begin_key, end_key);
if (!s.ok()) {
return s;
}
// 之后调用正常写入流程 通过WriteBatch写入memtable
return Write(opt, &batch);
}
Status WriteBatch::DeleteRange(ColumnFamilyHandle* column_family,
const Slice& begin_key, const Slice& end_key) {
return WriteBatchInternal::DeleteRange(this, GetColumnFamilyID(column_family),
begin_key, end_key);
}
Status WriteBatchInternal::DeleteRange(WriteBatch* b, uint32_t column_family_id,
const Slice& begin_key,
const Slice& end_key) {
LocalSavePoint save(b);
WriteBatchInternal::SetCount(b, WriteBatchInternal::Count(b) + 1);
if (column_family_id == 0) {
// rep_就是个string 格式参见write_batch.cc的注释
b->rep_.push_back(static_cast<char>(kTypeRangeDeletion));
} else {
b->rep_.push_back(static_cast<char>(kTypeColumnFamilyRangeDeletion));
PutVarint32(&b->rep_, column_family_id);
}
PutLengthPrefixedSlice(&b->rep_, begin_key);
PutLengthPrefixedSlice(&b->rep_, end_key);
b->content_flags_.store(b->content_flags_.load(std::memory_order_relaxed) |
ContentFlags::HAS_DELETE_RANGE,
std::memory_order_relaxed);
return save.commit();
}
Flush流程
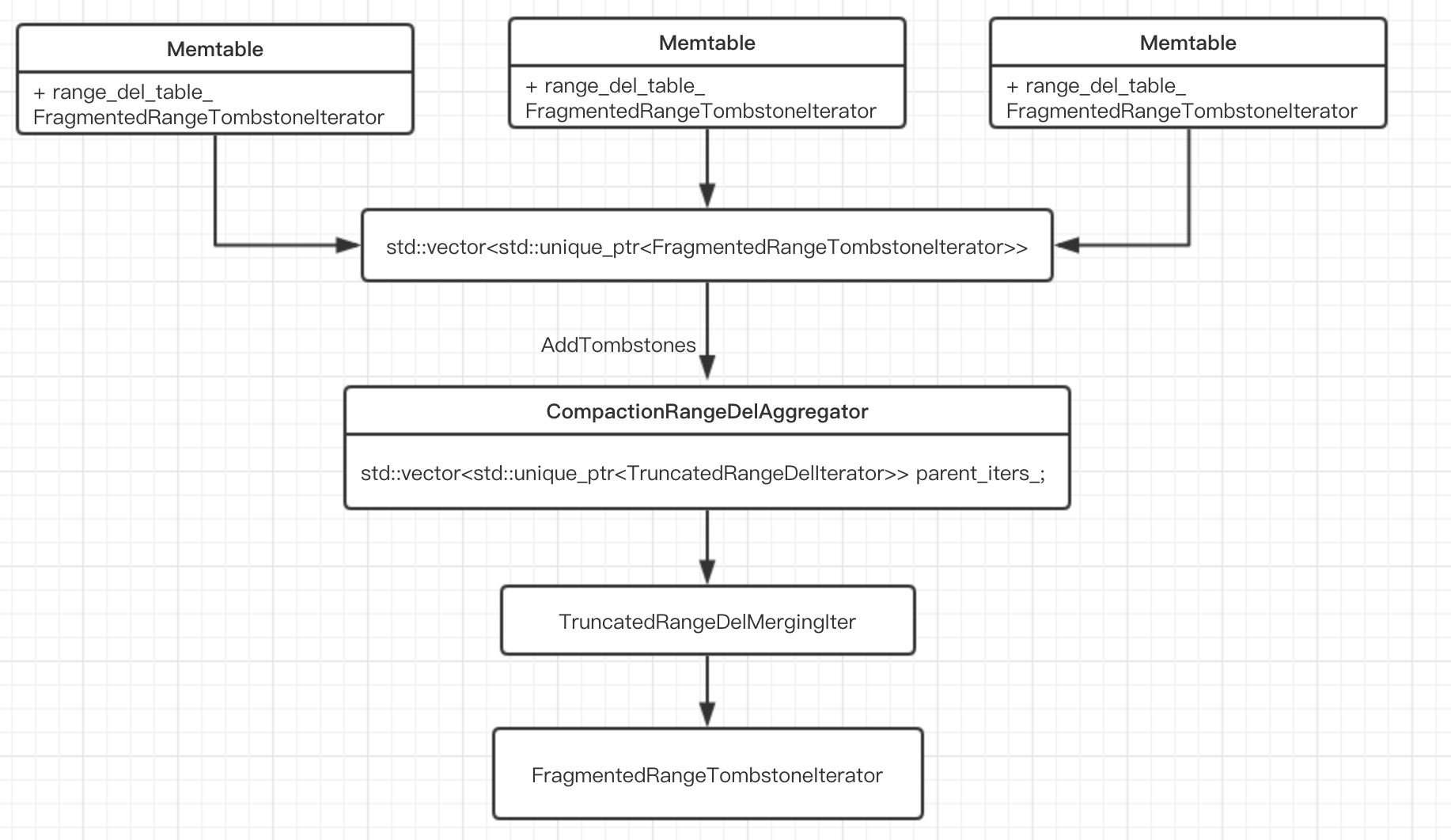
参见Flush中的WriteLevel0Table和BuildTable相关部分
WriteLevel0Table
对每一个memtable,调用NewRangeTombstoneIterator,构造FragmentedRangeTombstoneList,最终调用FragmentTombstones函数。
Status FlushJob::WriteLevel0Table() {
...
std::vector<std::unique_ptr<FragmentedRangeTombstoneIterator>>
range_del_iters;
...
// 根据要进行flush的各个memtable中的range delete,构建FragmentedRangeTombstoneIterator
for (MemTable* m : mems_) {
...
memtables.push_back(m->NewIterator(ro, &arena));
auto* range_del_iter =
m->NewRangeTombstoneIterator(ro, kMaxSequenceNumber);
if (range_del_iter != nullptr) {
range_del_iters.emplace_back(range_del_iter);
}
...
}
...
每个memtable生成由DeleteRange生成的TombStone的iterator
FragmentedRangeTombstoneIterator* MemTable::NewRangeTombstoneIterator(
const ReadOptions& read_options, SequenceNumber read_seq) {
if (read_options.ignore_range_deletions ||
is_range_del_table_empty_.load(std::memory_order_relaxed)) {
return nullptr;
}
auto* unfragmented_iter = new MemTableIterator(
*this, read_options, nullptr /* arena */, true /* use_range_del_table */);
if (unfragmented_iter == nullptr) {
return nullptr;
}
// 构造FragmentedRangeTombstoneList 里面会调用核心方法FragmentTombstones
auto fragmented_tombstone_list =
std::make_shared<FragmentedRangeTombstoneList>(
std::unique_ptr<InternalIterator>(unfragmented_iter),
comparator_.comparator);
// 根据构造出来的FragmentedRangeTombstoneList 创建一个迭代器
auto* fragmented_iter = new FragmentedRangeTombstoneIterator(
fragmented_tombstone_list, comparator_.comparator, read_seq);
return fragmented_iter;
}
构造FragmentedRangeTombstoneList
遍历unfragmented_tombstones,其中unfragmented_tombstones的每个tombstone的key是delete-range中的start_key, value是delete-range的end_key。
FragmentedRangeTombstoneList::FragmentedRangeTombstoneList(
std::unique_ptr<InternalIterator> unfragmented_tombstones,
const InternalKeyComparator& icmp, bool for_compaction,
const std::vector<SequenceNumber>& snapshots) {
if (unfragmented_tombstones == nullptr) {
return;
}
bool is_sorted = true;
int num_tombstones = 0;
InternalKey pinned_last_start_key;
Slice last_start_key;
// 遍历memtable中的tombstone 检查是否有序 如果没有顺序在下面排序
for (unfragmented_tombstones->SeekToFirst(); unfragmented_tombstones->Valid();
unfragmented_tombstones->Next(), num_tombstones++) {
if (num_tombstones > 0 &&
icmp.Compare(last_start_key, unfragmented_tombstones->key()) > 0) {
is_sorted = false;
break;
}
if (unfragmented_tombstones->IsKeyPinned()) {
last_start_key = unfragmented_tombstones->key();
} else {
pinned_last_start_key.DecodeFrom(unfragmented_tombstones->key());
last_start_key = pinned_last_start_key.Encode();
}
}
if (is_sorted) {
FragmentTombstones(std::move(unfragmented_tombstones), icmp, for_compaction,
snapshots);
return;
}
// 每个tombstone的key是delete-range中的start_key, value是delete-range的end_key
// Sort the tombstones before fragmenting them.
std::vector<std::string> keys, values;
keys.reserve(num_tombstones);
values.reserve(num_tombstones);
for (unfragmented_tombstones->SeekToFirst(); unfragmented_tombstones->Valid();
unfragmented_tombstones->Next()) {
keys.emplace_back(unfragmented_tombstones->key().data(),
unfragmented_tombstones->key().size());
values.emplace_back(unfragmented_tombstones->value().data(),
unfragmented_tombstones->value().size());
}
// VectorIterator implicitly sorts by key during construction.
// 按start key从小到大排序
auto iter = std::unique_ptr<VectorIterator>(
new VectorIterator(std::move(keys), std::move(values), &icmp));
FragmentTombstones(std::move(iter), icmp, for_compaction, snapshots);
}
在FragmentedRangeTombstoneList的构造中会调用FragmentTombstones
处理memtable中经过排序的delete-range,确保以下两点:no range tombstones overlap and range tombstones are ordered by start key
遍历排序后的delete-range列表 当后一个delete-range的start_key和前面的start_key不相等的时候会调用flush_current_tombstones函数
这个函数比较复杂 可以看下面例子
void FragmentedRangeTombstoneList::FragmentTombstones(
std::unique_ptr<InternalIterator> unfragmented_tombstones,
const InternalKeyComparator& icmp, bool for_compaction,
const std::vector<SequenceNumber>& snapshots) {
Slice cur_start_key(nullptr, 0);
auto cmp = ParsedInternalKeyComparator(&icmp);
// Stores the end keys and sequence numbers of range tombstones with a start
// key less than or equal to cur_start_key. Provides an ordering by end key
// for use in flush_current_tombstones.
std::set<ParsedInternalKey, ParsedInternalKeyComparator> cur_end_keys(cmp);
// 进入到flush_current_tombstones时 cur_end_keys中可能已经有很多个end_key
// 这个函数要做的事情就是处理[cur_start_key, next_start_key)范围里的delete-range tombstone fragment
// 有两种碎片:
// 1. delete-range的start_key和end_key都小于next_start_key
// 2. delete-range的start_key小于next_start_key 但end_key大于next_start_key
// Given the next start key in unfragmented_tombstones,
// flush_current_tombstones writes every tombstone fragment that starts
// and ends with a key before next_start_key, and starts with a key greater
// than or equal to cur_start_key.
auto flush_current_tombstones = [&](const Slice& next_start_key) {
auto it = cur_end_keys.begin();
bool reached_next_start_key = false;
for (; it != cur_end_keys.end() && !reached_next_start_key; ++it) {
Slice cur_end_key = it->user_key;
if (icmp.user_comparator()->Compare(cur_start_key, cur_end_key) == 0) {
// Empty tombstone.
continue;
}
if (icmp.user_comparator()->Compare(next_start_key, cur_end_key) <= 0) {
// All of the end keys in [it, cur_end_keys.end()) are after
// next_start_key, so the tombstones they represent can be used in
// fragments that start with keys greater than or equal to
// next_start_key. However, the end keys we already passed will not be
// used in any more tombstone fragments.
//
// Remove the fully fragmented tombstones and stop iteration after a
// final round of flushing to preserve the tombstones we can create more
// fragments from.
reached_next_start_key = true;
// 当前it指向的end_key已经大于等于next_start_key 也就说明[cur_start_key, next_start_key)范围内的已经处理完了
// 上面说的fully fragmented tombstones就是 start_key和end_key都小于next_start_key的delete-range所产生的的tombstone
cur_end_keys.erase(cur_end_keys.begin(), it);
cur_end_key = next_start_key;
}
// Flush a range tombstone fragment [cur_start_key, cur_end_key), which
// should not overlap with the last-flushed tombstone fragment.
assert(tombstones_.empty() ||
icmp.user_comparator()->Compare(tombstones_.back().end_key,
cur_start_key) <= 0);
// Sort the sequence numbers of the tombstones being fragmented in
// descending order, and then flush them in that order.
// 将所有[cur_start_key, cur_end_key)范围内的delete-range 按seqnums排序
autovector<SequenceNumber> seqnums_to_flush;
for (auto flush_it = it; flush_it != cur_end_keys.end(); ++flush_it) {
seqnums_to_flush.push_back(flush_it->sequence);
}
std::sort(seqnums_to_flush.begin(), seqnums_to_flush.end(),
std::greater<SequenceNumber>());
size_t start_idx = tombstone_seqs_.size();
size_t end_idx = start_idx + seqnums_to_flush.size();
// for_compaction默认是false
if (for_compaction) {
// Drop all tombstone seqnums that are not preserved by a snapshot.
// 这段还没看 应该是对于同一个范围的delete-range-fragment 只保留seqnum最大的
SequenceNumber next_snapshot = kMaxSequenceNumber;
for (auto seq : seqnums_to_flush) {
if (seq <= next_snapshot) {
// This seqnum is visible by a lower snapshot.
tombstone_seqs_.push_back(seq);
seq_set_.insert(seq);
auto upper_bound_it =
std::lower_bound(snapshots.begin(), snapshots.end(), seq);
if (upper_bound_it == snapshots.begin()) {
// This seqnum is the topmost one visible by the earliest
// snapshot. None of the seqnums below it will be visible, so we
// can skip them.
break;
}
next_snapshot = *std::prev(upper_bound_it);
}
}
end_idx = tombstone_seqs_.size();
} else {
// 对于flush就直接写入到tombstone_seqs_中
// The fragmentation is being done for reads, so preserve all seqnums.
tombstone_seqs_.insert(tombstone_seqs_.end(), seqnums_to_flush.begin(),
seqnums_to_flush.end());
seq_set_.insert(seqnums_to_flush.begin(), seqnums_to_flush.end());
}
assert(start_idx < end_idx);
// [cur_start_key, cur_end_key)之间的tombstone的seqnum 保存在tombstone_seqs_[start_indx, end_idx)
tombstones_.emplace_back(cur_start_key, cur_end_key, start_idx, end_idx);
cur_start_key = cur_end_key;
}
if (!reached_next_start_key) {
// 所有的cur_end_keys中的end_key都小于next_start_key
// There is a gap between the last flushed tombstone fragment and
// the next tombstone's start key. Remove all the end keys in
// the working set, since we have fully fragmented their corresponding
// tombstones.
cur_end_keys.clear();
}
cur_start_key = next_start_key;
};
pinned_iters_mgr_.StartPinning();
bool no_tombstones = true;
for (unfragmented_tombstones->SeekToFirst(); unfragmented_tombstones->Valid();
unfragmented_tombstones->Next()) {
const Slice& ikey = unfragmented_tombstones->key();
Slice tombstone_start_key = ExtractUserKey(ikey);
SequenceNumber tombstone_seq = GetInternalKeySeqno(ikey);
if (!unfragmented_tombstones->IsKeyPinned()) {
pinned_slices_.emplace_back(tombstone_start_key.data(),
tombstone_start_key.size());
tombstone_start_key = pinned_slices_.back();
}
no_tombstones = false;
Slice tombstone_end_key = unfragmented_tombstones->value();
if (!unfragmented_tombstones->IsValuePinned()) {
pinned_slices_.emplace_back(tombstone_end_key.data(),
tombstone_end_key.size());
tombstone_end_key = pinned_slices_.back();
}
// 遍历排序后的delete-range列表 当后一个delete-range的start_key和前面的start_key不相等的时候会调用flush_current_tombstones函数
if (!cur_end_keys.empty() && icmp.user_comparator()->Compare(
cur_start_key, tombstone_start_key) != 0) {
// The start key has changed. Flush all tombstones that start before
// this new start key.
flush_current_tombstones(tombstone_start_key);
}
cur_start_key = tombstone_start_key;
cur_end_keys.emplace(tombstone_end_key, tombstone_seq, kTypeRangeDeletion);
}
if (!cur_end_keys.empty()) {
ParsedInternalKey last_end_key = *std::prev(cur_end_keys.end());
flush_current_tombstones(last_end_key.user_key);
}
if (!no_tombstones) {
pinned_iters_mgr_.PinIterator(unfragmented_tombstones.release(),
false /* arena */);
}
}
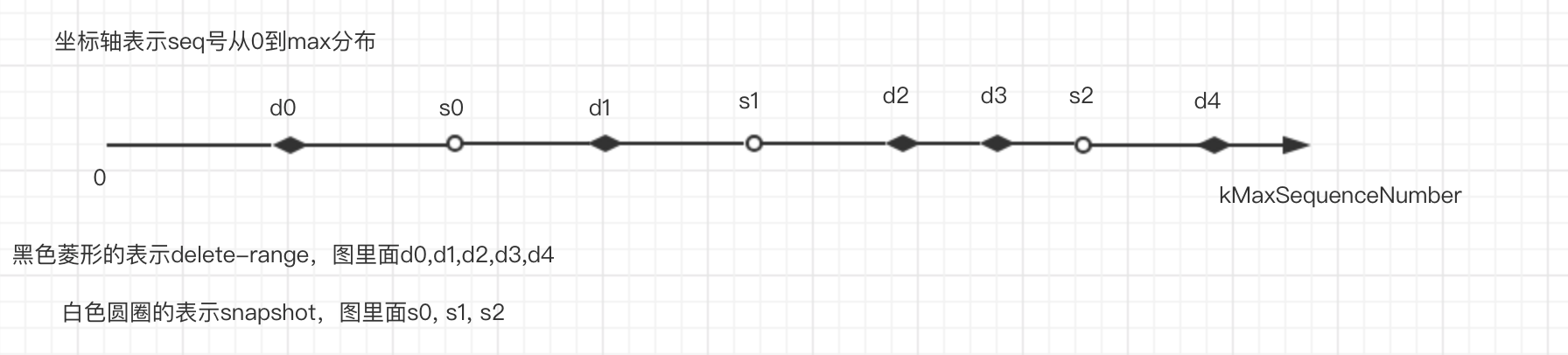
[start_key, end_key, seq)这个表示一个delete-range,假设有[a, c, 2) [a, b, 3) [a, b, 4) [a, e, 6) [d, g, 5)这几个delete-range。
FragmentTombstones这个是按照start_key排序遍历delete-range,在碰到[d, g, 5)这个delete-range对之前,cur_end_keys里面存储了{[b,4], [b,3], [c,2], [e,6]}
flush_current_tombstones函数遍历cur_end_keys,然后构造出来RangeTombstoneStack(也就是四元组cur_start_key, cur_end_key, start_idx, end_idx)如下
图里面最终结果是放在
tombstone_seqs_里面 实际代码是在tombstones_变量中(通过取对应tombstone_seqs_中的对应下标[start_indx, end_idx))

其实就是根据不同delete-range的范围,确定各个范围的seqnums
BuildTable
- 构造
CompactionRangeDelAggregator - 构造
CompactionIterator
Status BuildTable(...) {
// 构造CompactionRangeDelAggregator
std::unique_ptr<CompactionRangeDelAggregator> range_del_agg(
new CompactionRangeDelAggregator(&internal_comparator, snapshots));
...
CompactionIterator c_iter(
iter, internal_comparator.user_comparator(), &merge, kMaxSequenceNumber,
&snapshots, earliest_write_conflict_snapshot, snapshot_checker, env,
ShouldReportDetailedTime(env, ioptions.statistics),
true /* internal key corruption is not ok */, range_del_agg.get(),
blob_file_builder.get(), ioptions.allow_data_in_errors,
/*compaction=*/nullptr,
/*compaction_filter=*/nullptr, /*shutting_down=*/nullptr,
/*preserve_deletes_seqnum=*/0, /*manual_compaction_paused=*/nullptr,
db_options.info_log, full_history_ts_low);
c_iter.SeekToFirst();
// 正常的key/value
for (; c_iter.Valid(); c_iter.Next()) {
const Slice& key = c_iter.key();
const Slice& value = c_iter.value();
const ParsedInternalKey& ikey = c_iter.ikey();
// Generate a rolling 64-bit hash of the key and values
s = output_validator.Add(key, value);
if (!s.ok()) {
break;
}
builder->Add(key, value);
meta->UpdateBoundaries(key, value, ikey.sequence, ikey.type);
...
}
if (!s.ok()) {
c_iter.status().PermitUncheckedError();
} else if (!c_iter.status().ok()) {
s = c_iter.status();
}
if (s.ok()) {
auto range_del_it = range_del_agg->NewIterator();
for (range_del_it->SeekToFirst(); range_del_it->Valid();
range_del_it->Next()) {
auto tombstone = range_del_it->Tombstone();
auto kv = tombstone.Serialize();
// sst文件里面有专门的一个range_del_block存储delete-range数据
builder->Add(kv.first.Encode(), kv.second);
meta->UpdateBoundariesForRange(kv.first, tombstone.SerializeEndKey(),
tombstone.seq_, internal_comparator);
}
}
...
}
CompactionRangeDelAggregator::AddTombstones
void CompactionRangeDelAggregator::AddTombstones(
std::unique_ptr<FragmentedRangeTombstoneIterator> input_iter,
const InternalKey* smallest, const InternalKey* largest) {
if (input_iter == nullptr || input_iter->empty()) {
return;
}
assert(input_iter->lower_bound() == 0);
assert(input_iter->upper_bound() == kMaxSequenceNumber);
parent_iters_.emplace_back(new TruncatedRangeDelIterator(
std::move(input_iter), icmp_, smallest, largest));
// 将delete-range按snapshot分开
auto split_iters = parent_iters_.back()->SplitBySnapshot(*snapshots_);
for (auto& split_iter : split_iters) {
auto it = reps_.find(split_iter.first);
if (it == reps_.end()) {
bool inserted;
SequenceNumber upper_bound = split_iter.second->upper_bound();
SequenceNumber lower_bound = split_iter.second->lower_bound();
std::tie(it, inserted) = reps_.emplace(
split_iter.first, StripeRep(icmp_, upper_bound, lower_bound));
assert(inserted);
}
assert(it != reps_.end());
it->second.AddTombstones(std::move(split_iter.second));
}
}
上面的函数会调用TruncatedRangeDelIterator::SplitBySnapshot又会接着调用FragmentedRangeTombstoneIterator::SplitBySnapshot,可以看下面的例子:
SplitBySnapshot函数会生成如下结果:
[s0, FragmentedRangeTombstoneIterator(s0, 0)]
[s1, FragmentedRangeTombstoneIterator(s1, s0+1)]
[s2, FragmentedRangeTombstoneIterator(s2, s1+1)]
[max, FragmentedRangeTombstoneIterator(max, s2+1)]
最后在CompactionRangeDelAggregator::AddTombstones中的结果会保存在std::map<SequenceNumber, StripeRep> reps_中
reps_ = {
{s0, StripeRep[s0, 0, vector<std::unique_ptr>[FragmentedRangeTombstoneIterator...]]}
{s1, StripeRep[s1, s0+1, vector<std::unique_ptr>[FragmentedRangeTombstoneIterator...]]}
}
Compact流程
CompactionIterator::NextFromInput函数里面会调用ShouldDelete函数,判断如果在这个key和能够覆盖这个key的delete-range之间没有snapshot存在,那么flush到L0文件的时候可以直接丢弃这个key。
CompactionRangeDelAggregator::ShouldDelete
- 如果reps里面没有找到>=key的seq号,就直接return false, 这种情况是当前key比任何一个delete-range还大
- 调用StripeRep::ShouldDelete函数,flush/compation的时候都是kForwardTraversal模式,先遍历所有的iter,然后调用ForwardRangeDelIterator::AddNewIter
- ForwardRangeDelIterator::AddNewIter会先调用iter->seek函数,然后调用PushIter
- 最后调用ForwardRangeDelIterator::ShouldDelete,比较能够cover这个key的最大的seq和key的seq大小关系
- 假设k1的seq在d3和s2之间,那么k1应该保留,不能删除
- 假设k2的seq在s2和d4之间,并且d4可以cover k2,那么就可以删除,否则不能删除
- 假设k3的seq在d4之后,那么就要保留
读流程
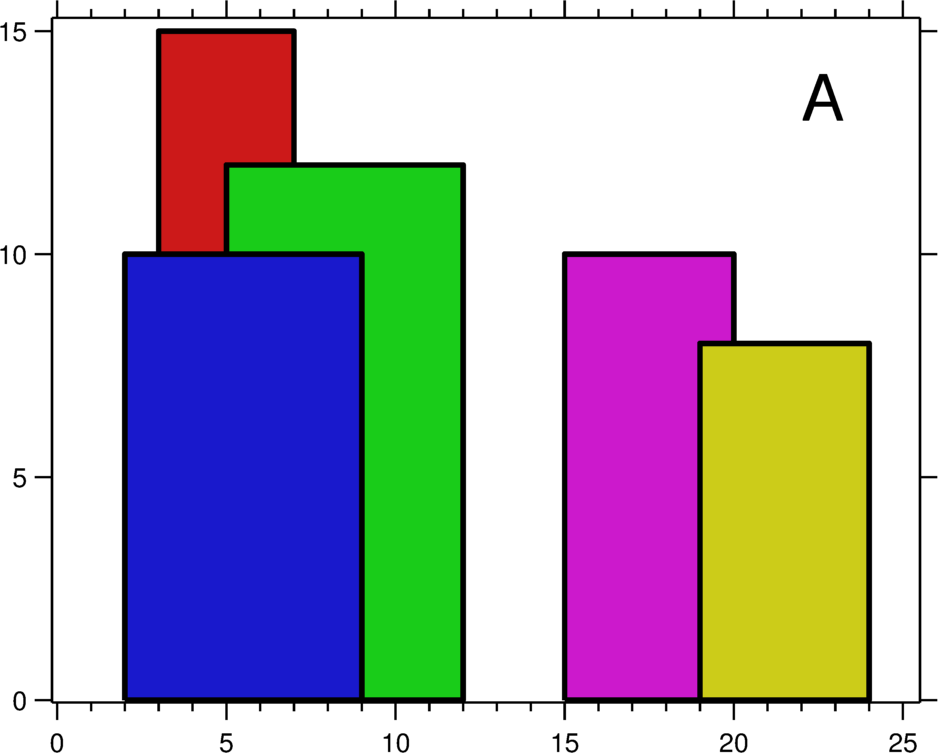
构建skyline,加速读性能。横轴代表的是key,纵轴代表该key对应的seqnum。其中A区域代表构建skyline之前,range tombstone存放在不同的区域,且其中可能有重叠的部分。构建完成skyline之后就变成了图B的样子,能够提供二分查找,减少了在不同区域的重复查找问题。
调用链路:
DBIter::Seek -> DBIter::FindNextUserEntry -> DBIter::FindNextUserEntryInternal
-> ReadRangeDelAggregator::ShouldDelete -> ReadRangeDelAggregator::ShouldDeleteImpl
-> RangeDelAggregator::StripeRep::ShouldDelete
-> ForwardRangeDelIterator::ShouldDelete
先看RangeDelAggregator::StripeRep::ShouldDelete,这个类主要就是维护了delete-range的前后向iterator
std::vector<std::unique_ptr<TruncatedRangeDelIterator>> iters_;
ForwardRangeDelIterator forward_iter_;
ReverseRangeDelIterator reverse_iter_;
SequenceNumber upper_bound_;
SequenceNumber lower_bound_;
bool RangeDelAggregator::StripeRep::ShouldDelete(
const ParsedInternalKey& parsed, RangeDelPositioningMode mode) {
if (!InStripe(parsed.sequence) || IsEmpty()) {
return false;
}
switch (mode) {
case RangeDelPositioningMode::kForwardTraversal:
InvalidateReverseIter();
// Pick up previously unseen iterators.
for (auto it = std::next(iters_.begin(), forward_iter_.UnusedIdx());
it != iters_.end(); ++it, forward_iter_.IncUnusedIdx()) {
auto& iter = *it;
forward_iter_.AddNewIter(iter.get(), parsed);
}
return forward_iter_.ShouldDelete(parsed);
case RangeDelPositioningMode::kBackwardTraversal:
InvalidateForwardIter();
// Pick up previously unseen iterators.
for (auto it = std::next(iters_.begin(), reverse_iter_.UnusedIdx());
it != iters_.end(); ++it, reverse_iter_.IncUnusedIdx()) {
auto& iter = *it;
reverse_iter_.AddNewIter(iter.get(), parsed);
}
return reverse_iter_.ShouldDelete(parsed);
default:
assert(false);
return false;
}
}
ForwardRangeDelIterator类则是维护还有哪些TruncatedRangeDelIterator还可以用于判断
应该是维护了两个堆,active_iters_中维护end_key, inactive_iters维护start_key
const InternalKeyComparator* icmp_;
size_t unused_idx_;
ActiveSeqSet active_seqnums_;
BinaryHeap<ActiveSeqSet::const_iterator, EndKeyMinComparator> active_iters_;
BinaryHeap<TruncatedRangeDelIterator*, StartKeyMinComparator> inactive_iters_;
ForwardRangeDelIterator的PushIter就是判断parsed这个key,如果parsed < iter->start_key(),那么说明这个delete-range无法覆盖这个key,直接跳过。
void PushIter(TruncatedRangeDelIterator* iter,
const ParsedInternalKey& parsed) {
if (!iter->Valid()) {
// The iterator has been fully consumed, so we don't need to add it to
// either of the heaps.
return;
}
int cmp = icmp_->Compare(parsed, iter->start_key());
if (cmp < 0) {
PushInactiveIter(iter);
} else {
PushActiveIter(iter);
}
}
void PushActiveIter(TruncatedRangeDelIterator* iter) {
auto seq_pos = active_seqnums_.insert(iter);
active_iters_.push(seq_pos);
}
判断active_iters_中是否有key能够覆盖parsed这个key
bool ForwardRangeDelIterator::ShouldDelete(const ParsedInternalKey& parsed) {
// parsed > end_key 换到下一个
// Move active iterators that end before parsed.
while (!active_iters_.empty() &&
icmp_->Compare((*active_iters_.top())->end_key(), parsed) <= 0) {
TruncatedRangeDelIterator* iter = PopActiveIter();
do {
iter->Next();
} while (iter->Valid() && icmp_->Compare(iter->end_key(), parsed) <= 0);
PushIter(iter, parsed);
assert(active_iters_.size() == active_seqnums_.size());
}
// Move inactive iterators that start before parsed.
while (!inactive_iters_.empty() &&
icmp_->Compare(inactive_iters_.top()->start_key(), parsed) <= 0) {
TruncatedRangeDelIterator* iter = PopInactiveIter();
while (iter->Valid() && icmp_->Compare(iter->end_key(), parsed) <= 0) {
iter->Next();
}
PushIter(iter, parsed);
assert(active_iters_.size() == active_seqnums_.size());
}
// 检查是否能覆盖
return active_seqnums_.empty()
? false
: (*active_seqnums_.begin())->seq() > parsed.sequence;
}
reference
http://rocksdb.org/blog/2018/11/21/delete-range.html https://blog.csdn.net/Z_Stand/article/details/110270317 https://bravoboy.github.io/2019/04/05/rocksdb-deleterange