LDBC Social Network Benchmark, part 2
继续介绍LDBC Social Network Benchmark,这一篇我们主要介绍SNB Workload里的各个Query是如何生成的,以及在性能测试中Driver是如何执行Workload。
Workload
在基准测试的准备阶段之后,总共生成了三类数据:
- Dataset:用于初始导入
- Update Streams:用于Driver在性能测试阶段实时更新
- Parameters:用于Driver在性能测试阶段读请求的参数
Write Query
由于SNB生成的数据非常复杂,因此在性能测试阶段不可能通过SNB Driver实时生成更新请求,因此实时更新的数据实际是由DataGen来完成的。我们在上一篇也提到过,使用时DataGen需要指定生成多长时间的数据,以及社交活动是从哪一年开始。Datagen会根据时间戳将所有数据进行切分,将90%数据作为Dataset,剩下的10%数据作为Update Streams用于后续更新的写请求。
对于所有写请求,DataGen都会将这次Update Query调度执行的时间、相关更新的参数生成到一个Json中。(为什么需要指定Query调度时间,我们后续会解释)
Read Query
SNB的读请求分为两大类:14个Complex read-only queries以及7个Short read-only queries。
Complex读请求都是以一个给定Person出发,查询一跳或者两跳子图内的相关信息。比如Interactive Complex 9(简称IC9)的查询pattern如下:给定一个起始的人,查询这个人的朋友或者朋友的朋友创建的最近20条消息。
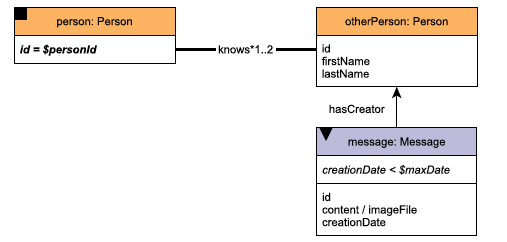
Short读请求分为两大类:一类是给定一个人,查询这个人的姓名、年龄等信息,或者是这个人的朋友以及这些朋友发送的消息。另一类则是给定一个消息,返回这条消息是的发送者以及发送者的相关信息。
完整的请求描述可以参见The LDBC Social Network Benchmark Specification,这里就不展开了。
Substitution Parameters
除了Dataset和Update Streams之外,DataGen还会生成不同读请求的参数(比如上面IC9的起点PersonId)。为了保证性能测试的结果能够稳定的衡量数据库的性能,SNB保证生成读请求的参数满足以下性质:
- 查询时间有上限:Complex Read和Short Read请求所触及的数据会因为起点不同而不同,但从宏观上看,其查询的子图都是有限的,因此其查询时间也会有一个合理的范围。
- 查询执行时间满足稳定的分布:同一个读请求的各个起点不同,查询数据量会不一样,但最终查询时间分布是稳定的。
- 逻辑计划相同:给定一个查询,无论起点如何不同,最终经过优化器优化之后生成的逻辑查询计划是相同的。这条性质保证每一个查询,能够稳定测试到图数据库中的一些技术难点(比如大量join、基数估计等)。
其中前两条还比较好理解,但最后一条可能做到吗?我们都知道一个优秀的优化器会根据查询参数决定实际执行时的join顺序。即便对于相同的查询Pattern,由于查询参数不同,最终的执行计划也会千变万化。我们看下DataGen是如何筛选参数,使同一个查询最终采用相同的查询计划。
首先,我们都知道查询数据量和查询时间是由强相关的。对于每一个查询pattern,LDBC在设计时都会有一个理想执行计划,在这个理想执行计划中,其数据量是可以通过起点预先计算出来的。
比如Complex 2,获取给定某个人的朋友发送的最近20个消息,其理想查询计划如下所示。对于这个理想执行计划,我们可以预处理得到每个起点的join的中间结果行数。比如对于PersonID=1542的起点,两次join的中间结果的数量分别为60和99。最终对于每个Query,会生成一个起点和中间join结果行数的表,称为Parameter-Count table。
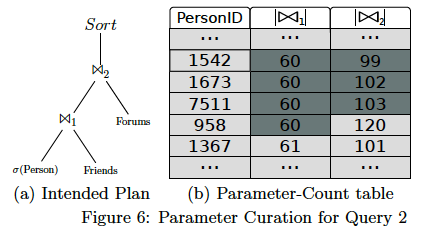
这个Parameter-Count table是由DataGen在生成数据过程中一起生成的。有了这张表,挑选参数的问题就变成了在这张表中挑选若干最相近的行。在这一步中采用的方式是贪心的启发式搜索:首先根据Join1中间结果数量,挑选最相近的若干行(Join1中值为60的几行),然后在这些行中再根据Join2的中间结果数量进行挑选(得到Join2值为99、102、103的几行),最终筛选出来的PersonID为1542、1673、7511。
这里存疑的是,按理来说应该先确定需要挑选参数的个数
k,然后再在Parameter-Count table进行筛选,否则按论文所说方法,可能会导致最终挑选的行数小于k。没有深究,但整体思路是合理的。
通过上述步骤,对于每一个Query类型,都会挑选出来若干个最相近的参数,从而尽可能使得查询计划相同。不过还剩一个问题,如何确定每个查询需要多少个参数,也就是不同查询的数量呢?
Query Mix
首先,LDBC SNB Interactive Workload期望数据库在性能测试过程中,Update Query、Complex Query和Short Query的执行时间比例依次是10%、50%和40%。这个比例一方面是为了模拟真实的社交网络负载,一般来说读请求会远多于写请求,另外这个负载也要能够真实反映数据库的性能。
尽管在上一步中,DataGen保证了同一个查询中的不同参数的执行时间相近。但不同查询的数据量和执行数据有巨大的差别。因此为了能够避免某一个类型的查询对最终测试结果起决定性作用,不同类型查询的数量需要精心的设计。
SNB Interactive Workload主要认为Complex Read Query应该主导是性能测试分数。Complex Read Query的数量是由Update Query的数量决定的,如下表所示
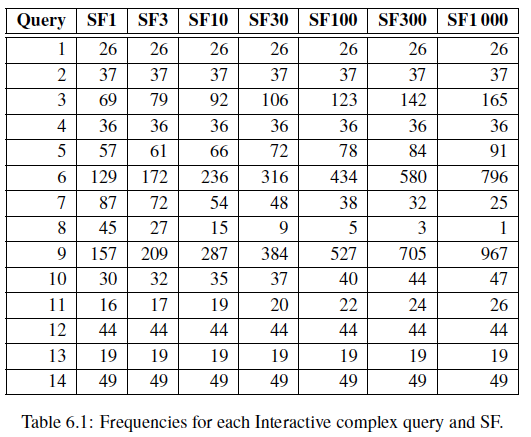
比如在SF100中每执行527个Update Query之后应该执行一次Complex Read Query 9。前面提过,每个Update Query的调度时间由DataGen已经决定了,因此每一个Complex Read的调度时间也就确定了。这里可以暂时将调度时间理解为相对于性能测试开始时间的一个相对时间,这个相对时间实际还会受到SNB Driver相关参数的影响。之所以是调度时间而不是执行时间的原因在于待测数据库可能已经满负载或者没有响应,导致某个Query可能已经到了调度时间,但无法及时执行Query。
这里就可以理解为什么SNB号称其测试结果可重复,关键之处就是DataGen生成的数据是确定性的。一旦Update Query调度时间确定,也就确定了Complex Read Query的调度时间,进而确保其性能测试结果可重复。了解这一点对于后续理解性能测试的结果以及SNB Driver的相关参数是至关重要的。
而Short Query会被穿插在每一个Complex Query之后。前面提到过Short Query分为两大类,查询人的相关信息以及查询消息的相关信息。准确来说,不同类型的Complex Query可能会返回不同信息,根据Complex Query的查询结果,后续会从Short Query中挑选一类,并把Complex Read的结果(比如Person或者Message的标识符)作为Short Query的参数进行查询。
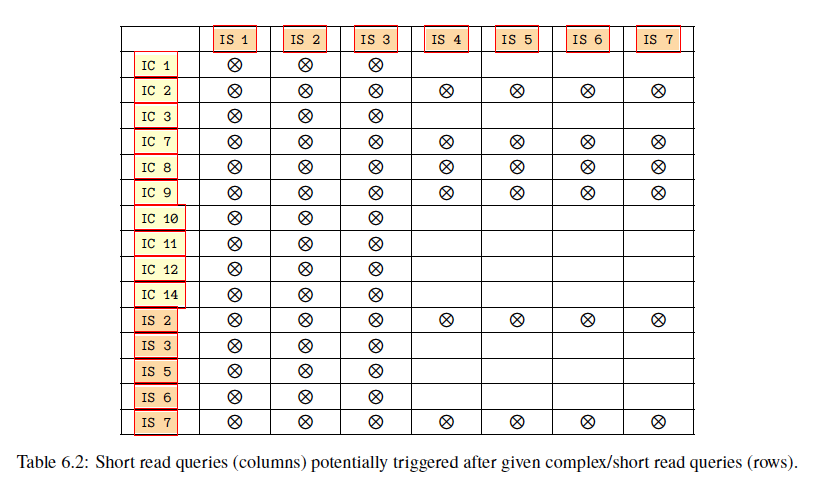
一个Short Query被调度之后,后续有可能会调度另一个Short Query,每次概率逐渐降低。即一个Complex Query之后,可能调度一连串Short Query(论文中称为short read random walk)。不同的Query后面可能触发的Short Query类型不同,如下表所示,比如IC10之后就只能触发IS1、IS2和IS3。
和Complex Query不同的时,Short Query的调度时间是由Driver根据它所依赖的Complex Read的完成时间所动态决定的。但触发多少个Short Query就是由上面说的概率决定,而所有性能测试过程中使用的随机生成器是相同的,综上所述整个基准测试过程中所有Query的比例和顺序是确定的。
Driver
Driver依赖DataGen生成的Dataset、Update Streams和Parameters,它主要能完成两个任务:
- Validate:校验数据库的正确性
- Benchmark:验证数据库的性能
Validate比较简单,根据Update Streams和Parameters,生成若干用于校验的参数,为了验证数据库的结果正确性,Validate依赖于确定的顺序执行查询,因此只能单线程执行。最终会输出数据库是否通过校验。
Benchmark则是根据Dataset、Update Streams和Parameters以及相关配置,生成确定的Workload(即一个Operation序列,其中包含Query和对应调度时间),根据调度时间,按顺序发送给待测数据库,同时保存其调度时间、开始执行时间和结束执行时间,最终输出性能报告。
Driver主要由Runtime、Workload、Database Connector、Report这几部分组成。
Runtime & Workload
无论最终性能测试在什么环境、待测图数据库是什么,只要Driver的输入(数据和配置)相同,其生成的Workload就是相同的。为了得到最高的吞吐量,一般会把Workload拆成多个stream。对于图来说,多个操作是有前后依赖关系的,比如好友存在才能添加好友关系。因此,Driver支持由多个线程来执行这个序列(由thread_count参数控制),但也需要保证即便有多个线程来执行,操作之前的依赖关系没有被破坏,仍然满足DataGen生成的调度时间关系。这部分原理就不展开介绍,感兴趣的可以阅读论文中的相关部分。
Workload中的每个Operation包括以下信息:
- Query类型
- Query参数
- 调度时间
- 期望结果(只在Validate中使用)
前面提到过所有Update Query和Complex Query的调度时间都是DataGen预先确定好的,Driver会根据调度时间通过Database Connector,把Query发送给数据库执行。显然,如果这些调度时间都是一个固定值,我们是无法获知数据库的真实性能的。在Driver中有一个参数time_compression_ratio(默认为1),可以在时间维度上拉伸或者压缩整个Workload,比如time_compression_ratio为2.0代表这个benchmark的运行持续时间会变成默认的两倍,也就是将Query之间的间隔时间变为原来的两倍。同理,time_compression_ratio为0.1代表Driver发送Query的速度会比默认情况下快10倍。注意,修改time_compression_ratio不会影响Query序列中各个类型Query的比例、Query的参数和执行顺序。
Database Connector
为了将数据库对接至SNB,厂商需要实现对应的Database Connector。其主要任务就是对接目标数据库:
- 将Driver框架的Query类型和参数,转换为目标图数据库的Query
- 将Query通过Database Connector发送给目标图数据库
这部分都只需要实现Driver的若干接口即可,可以参考https://github.com/ldbc/ldbc_snb_interactive_v1_driver以及相关文档。
Driver Configuration
Benchmark的主要目的就是在保证大于95%的及时率前提下,得到最优的time_compression_ratio(越小代表性能越高)。Operation如果在期望调度时间过后的1秒之内被Driver调度,就认为是及时的:
actual_start_time − scheduled_start_time < 1 second
此外,一次有效的benchmark需要至少需要测试两个小时(预热的半个小时期间,性能是不计入在结果之内)。
为了运行一次有效的Benchmark,Driver有几个重要的参数需要调整。
time_compression_ratio:调整Workload的执行速度,准确说是期望执行速度operation_count:Driver总共需要生成多少个Operation,配合time_compression_ratio修改,以保证Benchmark的时长thread_count:执行Operation的线程池大小,根据待测数据库的性能,可能也需要调整并发执行Query的数量
Report
最终Driver会生成如下性能指标:
- Start Time: 第一个Operation开始时间
- Finish Time: 最后一个Operation完成时间
- Total Run Time: Finish Time和Start Time的差值
- Total Operation Count: 总共执行了多少个Operation
系统的QPS可以通过Total Operation Count / Total Run Time得到。
对于每个类型的Query,Driver也会输出每个Query的总数,执行时间的平均值、中位数、P95、P99等、以及调度时间的延迟分布等。
Reference
有关LDBC SNB Interactive的介绍基本就到这了,后续可能还会总结一下这个基准测试的一些设计思想。另外我们自己系统在测试过程中,也出现了一些因为对SNB本身不够理解而当时看来十分诡异的现象,这也是花时间总结这几篇文章的初衷。
ldbc-snb-interactive-sigmod-2015.pdf (ldbcouncil.org)