RocksDB Iterator Internal, part 2
书接上篇,本文会分析MergingIterator内部是如何通过最小堆来保证迭代器输出的数据有序的。
数据结构
首先我们先需要理解MergingIterator的相关数据结构:
class MergingIterator : public InternalIterator {
// ...
// Which direction is the iterator moving?
enum Direction : uint8_t { kForward, kReverse };
Direction direction_;
const InternalKeyComparator* comparator_;
// We could also use an autovector with a larger reserved size.
// HeapItem for all child point iterators.
std::vector<HeapItem> children_;
// HeapItem for range tombstone start and end keys. Each range tombstone
// iterator will have at most one side (start key or end key) in a heap
// at the same time, so this vector will be of size children_.size();
// pinned_heap_item_[i] corresponds to the start key and end key HeapItem
// for range_tombstone_iters_[i].
std::vector<HeapItem> pinned_heap_item_;
// range_tombstone_iters_[i] contains range tombstones in the sorted run that
// corresponds to children_[i]. range_tombstone_iters_.empty() means not
// handling range tombstones in merging iterator. range_tombstone_iters_[i] ==
// nullptr means the sorted run of children_[i] does not have range
// tombstones.
std::vector<TruncatedRangeDelIterator*> range_tombstone_iters_;
// Levels (indices into range_tombstone_iters_/children_ ) that currently have
// "active" range tombstones. See comments above Seek() for meaning of
// "active".
std::set<size_t> active_;
// Cached pointer to child iterator with the current key, or nullptr if no
// child iterators are valid. This is the top of minHeap_ or maxHeap_
// depending on the direction.
IteratorWrapper* current_;
// If any of the children have non-ok status, this is one of them.
Status status_;
MergerMinIterHeap minHeap_;
// Max heap is used for reverse iteration, which is way less common than
// forward. Lazily initialize it to save memory.
std::unique_ptr<MergerMaxIterHeap> maxHeap_;
// Used to bound range tombstones. For point keys, DBIter and SSTable iterator
// take care of boundary checking.
const Slice* iterate_upper_bound_;
}
值得注意的有几个成员变量:
children_是每一层的point iterator。range_tombstone_iters_是每一层delete range生成的tombstone iterator,如果为空则代表当前层没有tombstone iterator,如果不为空,则对应的tombstone iterator中有一个范围[start, end),代表对应数据都被delete range所删除。range_tombstone_iters_为空代表没有任何层有tombstone iterator,如果range_tombstone_iters_不为空,必须保证range_tombstone_iters_和children_大小相同,对应level没有tombstone iterator填nullptr即可。pinned_heap_item_就用来保存tombstone iterator对应的HeapItem,HeapItem下面会具体介绍。active_保存仍然是active状态的tombstone iterator,active的含义下面会具体介绍。current_指向当前堆顶的迭代器。minHeap_就是最小堆,实际类型是BinaryHeap<HeapItem*, MinHeapItemComparator>,maxHeap_只会在反向移动迭代器时才会使用,为了节约内存会按需生成。iterate_upper_bound_是用户通过ReadOptions传入的上限,即只返回小于iterate_upper_bound_的数据。
全文中range tombstone和tombstone iterator都指同一个东西,在不同上下文中,语义稍微有点区别。使用range tombstone的地方会更强调由delete range生成的一个
[start, end)的tombstone,而使用tombstone iterator会更强调[start, end)的这个迭代器。
HeapItem
为了统一处理point iterator和tombstone iterator,MergingIterator会把每一个tombstone iterator的start和end分别也作为一个特殊类型的point key,然后统一用最小堆来管理这些point keys。对应的数据结构就是HeapItem,其中Type表名这个HeapItem对应的point iterator还是tombstone iterator,pinned_key就是对应的point iterator或者tombstone iterator指向的数据。通过HeapItem,每当对应的pinned_key已经out of range,就会这个HeapItem就会从堆中移出,这样就能够追踪当前还有多少point iterator和tombstone iterator仍然在生效。
struct HeapItem {
HeapItem() = default;
// 分别对应正常的pointer iterator, delete range start和delete range end
enum Type { ITERATOR, DELETE_RANGE_START, DELETE_RANGE_END };
IteratorWrapper iter;
size_t level = 0;
std::string pinned_key;
// Will be overwritten before use, initialize here so compiler does not
// complain.
Type type = ITERATOR;
explicit HeapItem(size_t _level, InternalIteratorBase<Slice>* _iter)
: level(_level), type(Type::ITERATOR) {
iter.Set(_iter);
}
// ...
};
class MinHeapItemComparator {
public:
MinHeapItemComparator(const InternalKeyComparator* comparator)
: comparator_(comparator) {}
bool operator()(HeapItem* a, HeapItem* b) const {
return comparator_->Compare(a->key(), b->key()) > 0;
}
private:
const InternalKeyComparator* comparator_;
};
using MergerMinIterHeap = BinaryHeap<HeapItem*, MinHeapItemComparator>;
对于point iterator,它的类型就是Type::ITERATOR,用来指向每一层当前指向的数据。
对于tombstone iterator,会把start 或者end放入堆中,且同一时刻最多只有一个HeapItem在堆中。如果是start在堆中,表示MergingIterator当前指向的数据仍然小于start。而如果某个tombstone iterator的start已经不在堆中,而是end在堆中,就能说明当前的tombstone iterator仍在生效,此时这个tomb iterator对应的level就在active_集合中。
当某个level的tombstone iterator在active_这个集合中时,pinned_heap_item_[level]一定是range_tombstone_iters_[level]的start key或者end key。
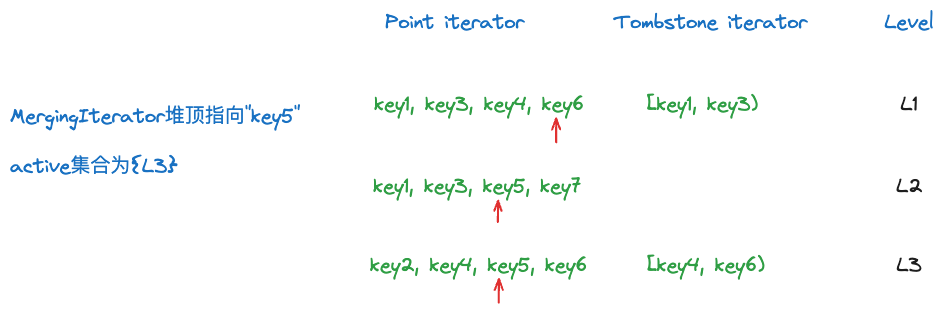
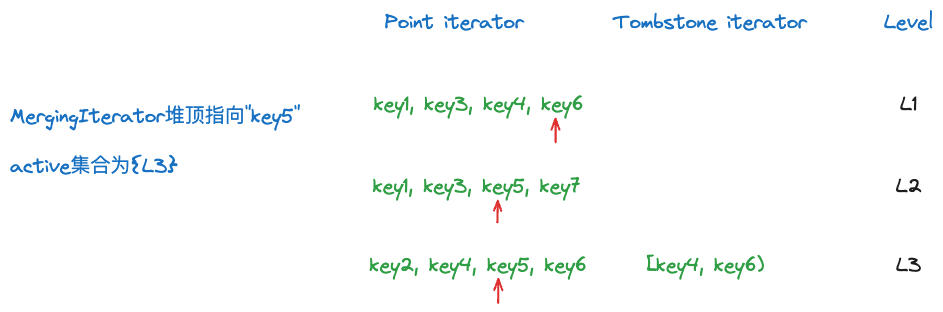
L1的[key1, key3)已经不可能在堆中,而L3的[key4, key6)的end = key6 > key5,此时仍然在堆中,因此active集合为{L3}。需要注意的是,某个tombstone iterator在active集合中,不代表当前堆顶的元素一定会输出,还需要结合堆顶元素的level和active集合中tombstone iterator的level来判断,具体细节会在下面的FindNextVisibleKey部分介绍。
最小堆相关实现
Build
MergingIterator中的children_和range_tombstone_iters_都是通过MergeIteratorBuilder在构造Iterator时候添加的:
virtual void AddIterator(InternalIterator* iter) {
children_.emplace_back(children_.size(), iter);
if (pinned_iters_mgr_) {
iter->SetPinnedItersMgr(pinned_iters_mgr_);
}
// Invalidate to ensure `Seek*()` is called to construct the heaps before
// use.
current_ = nullptr;
}
void AddRangeTombstoneIterator(TruncatedRangeDelIterator* iter) {
range_tombstone_iters_.emplace_back(iter);
}
当所有子迭代器都添加完之后,MergeIteratorBuilder会调用MergingIterator::Finish,此时pinned_heap_item_中只初始化range tombstone的level。
void Finish() {
if (!range_tombstone_iters_.empty()) {
pinned_heap_item_.resize(range_tombstone_iters_.size());
for (size_t i = 0; i < range_tombstone_iters_.size(); ++i) {
pinned_heap_item_[i].level = i;
}
}
}
MergingIterator::InsertRangeTombstoneToMinHeap函数用来将range tombstone加入到最小堆中:
- start: 如果
range_tombstone_iters_[level]的start小于iterate_upper_bound_,代表这个range tombstone一定out of range,直接返回。否则将pinned_heap_item_[level]置为range tombstone的start,并加入到最小堆中。 - end: 直接将
pinned_heap_item_[level]置为range tombstone的end,并加入到最小堆中。
void InsertRangeTombstoneToMinHeap(size_t level, bool start_key = true,
bool replace_top = false) {
assert(!range_tombstone_iters_.empty() &&
range_tombstone_iters_[level]->Valid());
if (start_key) {
ParsedInternalKey pik = range_tombstone_iters_[level]->start_key();
// iterate_upper_bound does not have timestamp
if (iterate_upper_bound_ &&
comparator_->user_comparator()->CompareWithoutTimestamp(
pik.user_key, true /* a_has_ts */, *iterate_upper_bound_,
false /* b_has_ts */) >= 0) {
if (replace_top) {
// replace_top implies this range tombstone iterator is still in
// minHeap_ and at the top.
minHeap_.pop();
}
return;
}
pinned_heap_item_[level].SetTombstoneKey(std::move(pik));
pinned_heap_item_[level].type = HeapItem::DELETE_RANGE_START;
assert(active_.count(level) == 0);
} else {
// allow end key to go over upper bound (if present) since start key is
// before upper bound and the range tombstone could still cover a
// range before upper bound.
pinned_heap_item_[level].SetTombstoneKey(
range_tombstone_iters_[level]->end_key());
pinned_heap_item_[level].type = HeapItem::DELETE_RANGE_END;
active_.insert(level);
}
if (replace_top) {
minHeap_.replace_top(&pinned_heap_item_[level]);
} else {
minHeap_.push(&pinned_heap_item_[level]);
}
}
Seek
接下来就是Seek,它会把MergingIterator指向第一个大于等于target的key的位置。如果存在range tombstone,则被range tombstone覆盖的key会被跳过。所以准确说,Seek会将MergingIterator指向第一个大于等于target,且没有被range tombstone覆盖的key。
void Seek(const Slice& target) override {
assert(range_tombstone_iters_.empty() ||
range_tombstone_iters_.size() == children_.size());
SeekImpl(target);
FindNextVisibleKey();
direction_ = kForward;
{
PERF_TIMER_GUARD(seek_min_heap_time);
current_ = CurrentForward();
}
}
既然Seek之后,MergingIterator对外表现就是一个普通的迭代器,因此堆顶一定不是tombstone iterator(无法对外输出下一个key/value),因此要么堆空了,要么堆顶是一个point iterator。进一步说,如果堆顶是一个point iterator时,所有active_中的tombstone iterator的level一定大于这个point iterator。
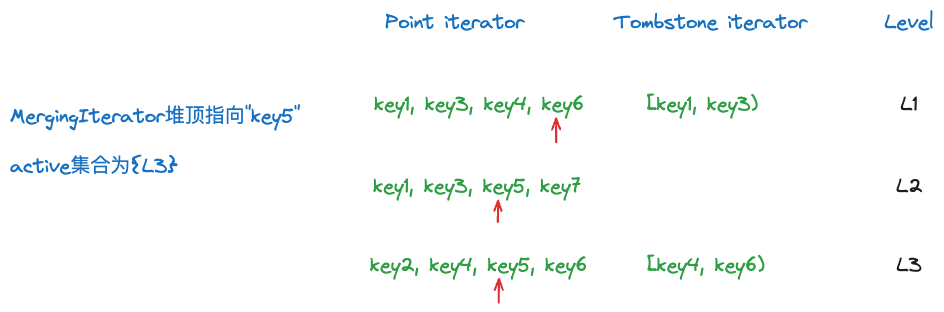
比如上面的例子,MergingIterator堆顶指向key5,每一层的point iterator指向红箭头所在元素。由于L1的tombstone iterator范围是[key1, key3),此时range tombstone的end已经不在最小堆中了,因此这个range tombstone不在active集合中。而L3的tombstone iterator范围是[key4, key6),此时range tombstone的end仍然在最小堆中,因此这个range tombstone在active集合中。
准确说,Seek会把children_[starting_level:]范围内的所有子迭代器,都指向到第一个大于等于target的位置,主要步骤如下:
SeekImpl会把每个level的pointer iterator和tombstone iterator都加入到最小堆中FindNextVisibleKey- 将
current_指向堆顶元素
SeekImpl
这里会采用类似pebble的cascading seek优化。即在第L层,如果有一个range tombstone的范围[start, end)覆盖了当前要查找的target,那么这个range tombstone一定对于所有level > L的层次也生效。即对于所有的层次,我们可以将要查找的target改为end。这个优化可以不断在更大的层次执行,因此被称为cascading seek。(下面会举一个例子)
在这个函数中会分为几步初始化最小堆:
- 清空既有的最小堆
- 将level在
[0:starting_level]范围内的有效子迭代器,加入到最小堆中(有效指迭代器Valid()为true)- 将
children_[0:starting_level]内的所有point iterator都加入到最小堆中 - 将
range_tombstone_iters_[0:starting_level]内的所有tombstone iterator都加入到最小堆中
- 将
- 对每一层执行以下逻辑:
- 对
children_[level]调用Seek - 对
range_tombstone_iters_[level]调用Seek- 如果
target < start,将start加入最小堆,否则将end加入最小堆 - cascading seek: 如果
start ≤ current_search_key,则将current_search_key更新为end
- 如果
- 将
children_[level]加入最小堆
- 对
void MergingIterator::SeekImpl(const Slice& target, size_t starting_level,
bool range_tombstone_reseek) {
// active range tombstones before `starting_level` remain active
ClearHeaps(false /* clear_active */);
ParsedInternalKey pik;
if (!range_tombstone_iters_.empty()) {
// pik is only used in InsertRangeTombstoneToMinHeap().
ParseInternalKey(target, &pik, false).PermitUncheckedError();
}
// TODO: perhaps we could save some upheap cost by add all child iters first
// and then do a single heapify.
// 将level在[0:starting_level]范围内的有效point iterator,加入到最小堆中
for (size_t level = 0; level < starting_level; ++level) {
PERF_TIMER_GUARD(seek_min_heap_time);
AddToMinHeapOrCheckStatus(&children_[level]);
}
if (!range_tombstone_iters_.empty()) {
// 将level在[0:starting_level]范围内的有效tombstone iterator,加入到最小堆中
// Add range tombstones from levels < starting_level. We can insert from
// pinned_heap_item_ for the following reasons:
// - pinned_heap_item_[level] is in minHeap_ iff
// range_tombstone_iters[level]->Valid().
// - If `level` is in active_, then range_tombstone_iters_[level]->Valid()
// and pinned_heap_item_[level] is of type RANGE_DELETION_END.
for (size_t level = 0; level < starting_level; ++level) {
if (range_tombstone_iters_[level] &&
range_tombstone_iters_[level]->Valid()) {
// use an iterator on active_ if performance becomes an issue here
if (active_.count(level) > 0) {
assert(pinned_heap_item_[level].type == HeapItem::DELETE_RANGE_END);
// if it was active, then start key must be within upper_bound,
// so we can add to minHeap_ directly.
minHeap_.push(&pinned_heap_item_[level]);
} else {
// this takes care of checking iterate_upper_bound, but with an extra
// key comparison if range_tombstone_iters_[level] was already out of
// bound. Consider using a new HeapItem type or some flag to remember
// boundary checking result.
InsertRangeTombstoneToMinHeap(level);
}
} else {
assert(!active_.count(level));
}
}
// levels >= starting_level will be reseeked below, so clearing their active
// state here.
active_.erase(active_.lower_bound(starting_level), active_.end());
}
status_ = Status::OK();
IterKey current_search_key;
current_search_key.SetInternalKey(target, false /* copy */);
// Seek target might change to some range tombstone end key, so
// we need to remember them for async requests.
// (level, target) pairs
autovector<std::pair<size_t, std::string>> prefetched_target;
for (auto level = starting_level; level < children_.size(); ++level) {
{
PERF_TIMER_GUARD(seek_child_seek_time);
children_[level].iter.Seek(current_search_key.GetInternalKey());
}
PERF_COUNTER_ADD(seek_child_seek_count, 1);
if (!range_tombstone_iters_.empty()) {
if (range_tombstone_reseek) {
// This seek is to some range tombstone end key.
// Should only happen when there are range tombstones.
PERF_COUNTER_ADD(internal_range_del_reseek_count, 1);
}
if (children_[level].iter.status().IsTryAgain()) {
prefetched_target.emplace_back(
level, current_search_key.GetInternalKey().ToString());
}
auto range_tombstone_iter = range_tombstone_iters_[level];
if (range_tombstone_iter) {
range_tombstone_iter->Seek(current_search_key.GetUserKey());
if (range_tombstone_iter->Valid()) {
// insert the range tombstone end that is closer to and >=
// current_search_key. Strictly speaking, since the Seek() call above
// is on user key, it is possible that range_tombstone_iter->end_key()
// < current_search_key. This can happen when range_tombstone_iter is
// truncated and range_tombstone_iter.largest_ has the same user key
// as current_search_key.GetUserKey() but with a larger sequence
// number than current_search_key. Correctness is not affected as this
// tombstone end key will be popped during FindNextVisibleKey().
InsertRangeTombstoneToMinHeap(
level, comparator_->Compare(range_tombstone_iter->start_key(),
pik) > 0 /* start_key */);
// cascading seek优化, 更新current_search_key
// current_search_key < end_key guaranteed by the Seek() and Valid()
// calls above. Only interested in user key coverage since older
// sorted runs must have smaller sequence numbers than this range
// tombstone.
//
// TODO: range_tombstone_iter->Seek() finds the max covering
// sequence number, can make it cheaper by not looking for max.
if (comparator_->user_comparator()->Compare(
range_tombstone_iter->start_key().user_key,
current_search_key.GetUserKey()) <= 0) {
// Since range_tombstone_iter->Valid(), seqno should be valid, so
// there is no need to check it.
range_tombstone_reseek = true;
// Current target user key is covered by this range tombstone.
// All older sorted runs will seek to range tombstone end key.
// Note that for prefix seek case, it is possible that the prefix
// is not the same as the original target, it should not affect
// correctness. Besides, in most cases, range tombstone start and
// end key should have the same prefix?
// If range_tombstone_iter->end_key() is truncated to its largest_
// boundary, the timestamp in user_key will not be max timestamp,
// but the timestamp of `range_tombstone_iter.largest_`. This should
// be fine here as current_search_key is used to Seek into lower
// levels.
current_search_key.SetInternalKey(
range_tombstone_iter->end_key().user_key, kMaxSequenceNumber);
}
}
}
}
// child.iter.status() is set to Status::TryAgain indicating asynchronous
// request for retrieval of data blocks has been submitted. So it should
// return at this point and Seek should be called again to retrieve the
// requested block and add the child to min heap.
if (children_[level].iter.status().IsTryAgain()) {
continue;
}
{
// Strictly, we timed slightly more than min heap operation,
// but these operations are very cheap.
PERF_TIMER_GUARD(seek_min_heap_time);
AddToMinHeapOrCheckStatus(&children_[level]);
}
}
if (range_tombstone_iters_.empty()) {
for (auto& child : children_) {
if (child.iter.status().IsTryAgain()) {
child.iter.Seek(target);
{
PERF_TIMER_GUARD(seek_min_heap_time);
AddToMinHeapOrCheckStatus(&child);
}
PERF_COUNTER_ADD(number_async_seek, 1);
}
}
} else {
for (auto& prefetch : prefetched_target) {
// (level, target) pairs
children_[prefetch.first].iter.Seek(prefetch.second);
{
PERF_TIMER_GUARD(seek_min_heap_time);
AddToMinHeapOrCheckStatus(&children_[prefetch.first]);
}
PERF_COUNTER_ADD(number_async_seek, 1);
}
}
}
FindNextVisibleKey
FindNextVisibleKey会不断检查堆顶的元素,直到堆中没有任何元素,或者堆顶是一个没有被range tombstone覆盖的point iterator。当堆顶是一个第L层的point iterator,指向数据k。
- 如果
k在level ≤ L的range tombstone范围内,range_tombstone_iters_[level]在active_集合内,这个point iterator无效(准确说level = L的range tombstone会比较seqno)。 - 如果
k在level > L的range tombstone范围内,即便range_tombstone_iters_[level]在active_集合内,这个point iterator有效。
我们结合一个例子来理解:
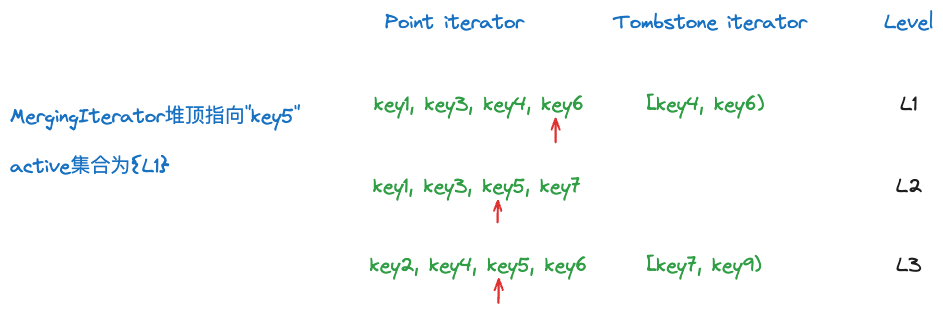
比如当前堆顶的数据key5来自L2,被L1的[key4, key6)覆盖了,由于L1 < L2,因此这个point iterator无效,key5这个数据会跳过。另外由于会采用前面介绍的cascading seek,即对每一层使用这个range tombstone的end,即key6进行Seek,之后每一层point iterator会重新指向新的位置。此时MergingIterator指向key6,没有被任何active的tombstone所覆盖,因此point iterator有效,key6可以被输出。
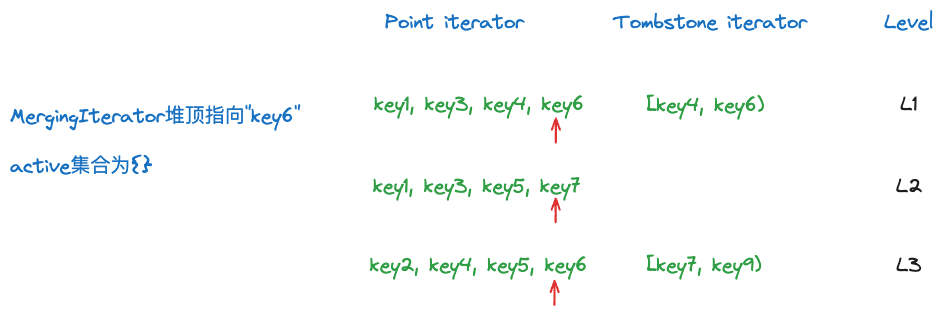
而如果一开始L3有一个[key4, key6)的range tombstone,覆盖堆顶指向的元素key5,而此时key5所在L2 < L3,即便此时L3的range tombstone在active_集合内,此时堆顶元素的这个point iterator有效,key5会输出。
理解原理之后,我们看一下具体实现。
inline void MergingIterator::FindNextVisibleKey() {
// When active_ is empty, we know heap top cannot be a range tombstone end
// key. It cannot be a range tombstone start key per PopDeleteRangeStart().
PopDeleteRangeStart();
while (!minHeap_.empty() &&
(!active_.empty() || minHeap_.top()->IsDeleteRangeSentinelKey()) &&
SkipNextDeleted()) {
PopDeleteRangeStart();
}
}
SkipNextDeleted中,有三种情况会从堆中将堆顶元素pop:
- 堆顶元素是point iterator,且指向一个sst文件的smallest/largest key哨兵
- 堆顶元素是point iterator,且指向的key被任何range tombstone所覆盖
- 堆顶元素是range iterator,且类型是
HeapItem::DELETE_RANGE_END(代表这个range tombstone已经失效了)
bool MergingIterator::SkipNextDeleted() {
// 3 types of keys:
// - point key
// - file boundary sentinel keys
// - range deletion end key
auto current = minHeap_.top();
if (current->type == HeapItem::DELETE_RANGE_END) {
active_.erase(current->level);
assert(range_tombstone_iters_[current->level] &&
range_tombstone_iters_[current->level]->Valid());
range_tombstone_iters_[current->level]->Next();
if (range_tombstone_iters_[current->level]->Valid()) {
InsertRangeTombstoneToMinHeap(current->level, true /* start_key */,
true /* replace_top */);
} else {
minHeap_.pop();
}
return true /* current key deleted */;
}
if (current->iter.IsDeleteRangeSentinelKey()) {
// If the file boundary is defined by a range deletion, the range
// tombstone's end key must come before this sentinel key (see op_type in
// SetTombstoneKey()).
assert(ExtractValueType(current->iter.key()) != kTypeRangeDeletion ||
active_.count(current->level) == 0);
// LevelIterator enters a new SST file
current->iter.Next();
if (current->iter.Valid()) {
assert(current->iter.status().ok());
minHeap_.replace_top(current);
} else {
minHeap_.pop();
}
// Remove last SST file's range tombstone end key if there is one.
// This means file boundary is before range tombstone end key,
// which could happen when a range tombstone and a user key
// straddle two SST files. Note that in TruncatedRangeDelIterator
// constructor, parsed_largest.sequence is decremented 1 in this case.
if (!minHeap_.empty() && minHeap_.top()->level == current->level &&
minHeap_.top()->type == HeapItem::DELETE_RANGE_END) {
minHeap_.pop();
active_.erase(current->level);
}
if (range_tombstone_iters_[current->level] &&
range_tombstone_iters_[current->level]->Valid()) {
InsertRangeTombstoneToMinHeap(current->level);
}
return true /* current key deleted */;
}
assert(current->type == HeapItem::ITERATOR);
// Point key case: check active_ for range tombstone coverage.
ParsedInternalKey pik;
ParseInternalKey(current->iter.key(), &pik, false).PermitUncheckedError();
for (auto& i : active_) {
if (i < current->level) {
// range tombstone is from a newer level, definitely covers
assert(comparator_->Compare(range_tombstone_iters_[i]->start_key(),
pik) <= 0);
assert(comparator_->Compare(pik, range_tombstone_iters_[i]->end_key()) <
0);
std::string target;
AppendInternalKey(&target, range_tombstone_iters_[i]->end_key());
SeekImpl(target, current->level, true);
return true /* current key deleted */;
} else if (i == current->level) {
// range tombstone is from the same level as current, check sequence
// number. By `active_` we know current key is between start key and end
// key.
assert(comparator_->Compare(range_tombstone_iters_[i]->start_key(),
pik) <= 0);
assert(comparator_->Compare(pik, range_tombstone_iters_[i]->end_key()) <
0);
if (pik.sequence < range_tombstone_iters_[current->level]->seq()) {
// covered by range tombstone
current->iter.Next();
if (current->iter.Valid()) {
minHeap_.replace_top(current);
} else {
minHeap_.pop();
}
return true /* current key deleted */;
} else {
return false /* current key not deleted */;
}
} else {
return false /* current key not deleted */;
// range tombstone from an older sorted run with current key < end key.
// current key is not deleted and the older sorted run will have its range
// tombstone updated when the range tombstone's end key are popped from
// minHeap_.
}
}
// we can reach here only if active_ is empty
assert(active_.empty());
assert(minHeap_.top()->type == HeapItem::ITERATOR);
return false /* current key not deleted */;
}
Next
当用户调用Seek之后,就可以通过不断调用Valid和Prev/Next来遍历相应的数据了。Next本质上就是调用堆顶迭代器current_的Next,然后检查此时current_是否仍然有效:
current_有效:堆顶元素指向的key变了,调整最小堆current_无效:从堆中pop堆顶元素
由于堆顶元素可能发生变化,需要重新调用FindNextVisibleKey以满足堆顶元素是一个合理的迭代器,并修改current_。
void Next() override {
assert(Valid());
// Ensure that all children are positioned after key().
// If we are moving in the forward direction, it is already
// true for all of the non-current children since current_ is
// the smallest child and key() == current_->key().
if (direction_ != kForward) {
// The loop advanced all non-current children to be > key() so current_
// should still be strictly the smallest key.
SwitchToForward();
}
// For the heap modifications below to be correct, current_ must be the
// current top of the heap.
assert(current_ == CurrentForward());
// as the current points to the current record. move the iterator forward.
current_->Next();
if (current_->Valid()) {
// current is still valid after the Next() call above. Call
// replace_top() to restore the heap property. When the same child
// iterator yields a sequence of keys, this is cheap.
assert(current_->status().ok());
minHeap_.replace_top(minHeap_.top());
} else {
// current stopped being valid, remove it from the heap.
considerStatus(current_->status());
minHeap_.pop();
}
FindNextVisibleKey();
current_ = CurrentForward();
}
到这里我们已经把MergingIterator常用接口分析完了,其本质上就是通过一个最小堆,把多个子迭代器的结果有序输出。用户只需要通过DBImpl::NewIterator获取一个MergingIterator,即可迭代遍历完相应数据,而完全不感知内部多个子迭代器的存在。另外由于篇幅限制,我们只介绍了最小堆实现,最大堆主要就是向前遍历的Prev使用,除了按需生成最大堆以外,其余原理和最小堆一样。另外对于一个MergingIterator,如果在遍历的过程中改变方向,即陆续调用Prev和Next,会导致内部需要重新生成最小堆或者最大堆,造成额外开销。