Kuzu Graph Database Management System
最近看了Kuzu的论文,大致做一下总结~
Kuzu’s goal
Kuzu的核心思想主要是两个:
- 使用factorized tuples来保存join的中间结果和最终结果,大幅度减少join所占用的内存。(关于factorized下文会做简要介绍,详细解释可以看Kuzu的博客Factorization & Great Ideas from Database Theory。
- Kuzu的数据是在基于磁盘的列存,因此Kuzu只进行顺序扫描,从不进行随机IO。另外为了减少顺序扫描的开销,在一部分允许的场景下,在扫描数据和正反向邻接表时,只扫描必须的block。
我们可以结合论文中的例子来理解Kuzu为什么要这么做:
Example 1
---
MATCH (c:Acc)-[t2:Trnsfr]->(a:Acc)-[t1:Transfer]->(b:Acc)
WHERE a.owner = 'Karim' RETURN c.owner, b.owner
对于这样一个简单的两跳查询,一般的图数据库的执行计划如下所示(它这里假设是列存图数据库):
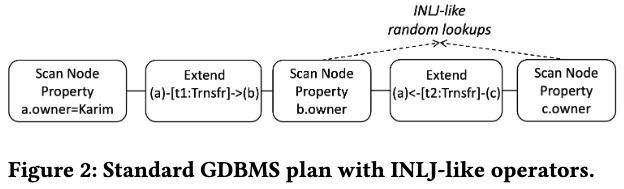
- 扫描满足
a.owner = 'Karim'的点,得到a.id - 通过正向邻接表进行拓展
(a:Acc)-[t1:Transfer]->(b:Acc),得到(a.id, b.id)的tuple - 扫描
b.owner,并和b.id进行join,得到(a.id, b.id, b.owner)的tuple - 通过反向邻接表进行拓展
(a:Acc)<-[t2:Trnsfr]-(c:Acc),得到(c.id, a.id)的tuple - 扫描
c.owner,并和c.id进行join,得到(c.id, b.owner, a.id)的tuple - 最后将第3步和第五步中间结果进行join,得到
(c.id, b.owner, a.id, b.id, b.owner)的tuple,进行输出
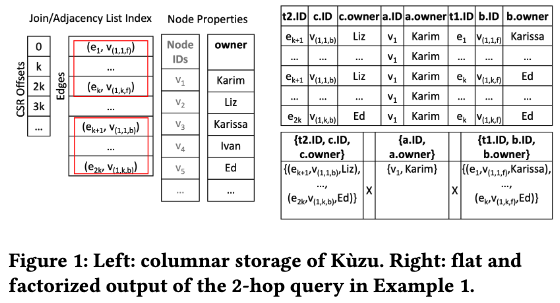
Kuzu中的正反向邻接表都是使用CSR进行保存,结果参照下面Figure1中的右上表格,即满足a.owner = Karim的点只有v1,它有k条入边和k条出边,因此这个表格总共有k^2行tuple。
可以看到,整个计划中总共进行了三次Join,使用flat tuple来保存join的结果非常消耗内存,因此可以使用factorization来进行优化(中文对应的词汇应该是因式分解)。由于v1分别有k条入边和k条出边,因此可以用入边 X 点 X 出边的形式来保存,参照Figure1中的右下表格。由于只有一个点满足a.name = Karim,因此整个表格只有一行,里面的数据量也变成了2k + 1,即k条出边,k条入边,以及一个点的数据。
而另一方面,在第2步和第4步进行join时候,理论上是可以进行随机IO的。比如在第2步进行join时,由于已经通过上一步拓展知道b.id集合,此时只要根据b.id中每个点的id去获取对应的b.owner即可以。而Kuzu认为用顺序IO + Filter的性能会优于随机IO,因此只进行顺序扫描。
顺序IO + Filter性能存疑,最后再讨论。
理解了其设计思想后,我们看一看Kuzu的一些关键实现。
Factorized Query Processor
Factorized Vectors
前面已经简单介绍过,通过隐式分解,大大简化join结果的内存表示,将一个flat table变成了不同结果集的笛卡尔积。具体有两种形式,flat和unflat,这里摘抄了下原文:

Flat: If curIdx ≥ 0, the vector group (e.g., Vector Group1 in the figure) is flattened and represents a single tuple that consists of the curIdx’th values in the vectors.
Unflat: If curIdx =−1 (e.g., Vector Group2), the vector group represents as many tuples as the size of the vectors it contains.
详细的原理可以参考原始论文:Columnar Storage and List-based Processing for Graph Database Management Systems
S-Join
Kuzu针对不同场景对join进行了各种优化。首先是S-Join,想法源于这篇论文Making RDBMSs Efficient on Graph Workloads through Predefined Joins。其核心思想在于,从HashBuild侧可以传一个semijoin filter到HashProbe侧,实际也就是dynamic filter。
我们用下面这个例子进行解释。
Example 2
---
MATCH (a:Account)-[t:Transfer]->(b:Account)
WHERE t.amount > 1000 RETURN a.owner, t.amount
它的大致执行流程如下:
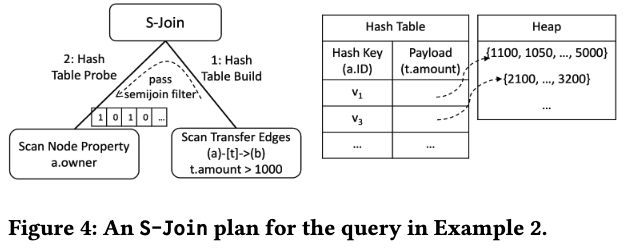
- Pipeline 1: 扫描满足
t.amount > 1000的Transfer边,得到若干条边,以a.id建立一个Hash table。并将a.id的集合作为semijoin filter传给Pipeline 2 - Pipeline 2: 由于Kuzu是列存,而query要求返回
a.owner,因此需要进行a.id和a.owner的join。由于在第一步已经得到了若干a.id,Kuzu采取的办法就是顺序扫描a.owner,并将第一步得到的a.id的集合作为filter,得到对应的a.owner。最后和第一步的结果进行join得到最终结果
另外,S-Join只能处理build side只有一部分数据是factorization structure,且join key是flat的情况(Figure 4中的HashTable就满足这个条件)。
Binary ASP-Join
如上所说,当join key不满足flat时,S-Join无法处理,这时候就会需要下一种Join:ASP-Join(Accumulate-Semijoin-Probe-Join)。我们再用Example1来解释一下:
MATCH (c:Acc)-[t2:Trnsfr]->(a:Acc)-[t1:Transfer]->(b:Acc)
WHERE a.owner = 'Karim' RETURN c.owner, b.owner
其中一个ASP-Join会处理(a:Acc)-[t1:Transfer]->(b:Acc)这一部分,其执行过程为:
- Pipeline 1 (Probe Accumulation): 扫描
a,然后扫描Transfer边,最终生成一个共享的factorized tuples。另外还会将满足条件的b.id作为semijoin filter传给Pipeline 2(factorized tuples此时已经有a.id, a.owner, b.id) - Pipeline 2 (Hash Table Build): 利用Pipeline 1的filter扫描
b.owner这一列,得到b.owner和b.id,作为HashBuild - Pipeline 3 (Hash Table Probe): 重新扫描factorized tuples,将第一步的中间结果和第二步的
b.id进行join,得到最终结果(a.id, a.owner) X (b.id, b.owner)
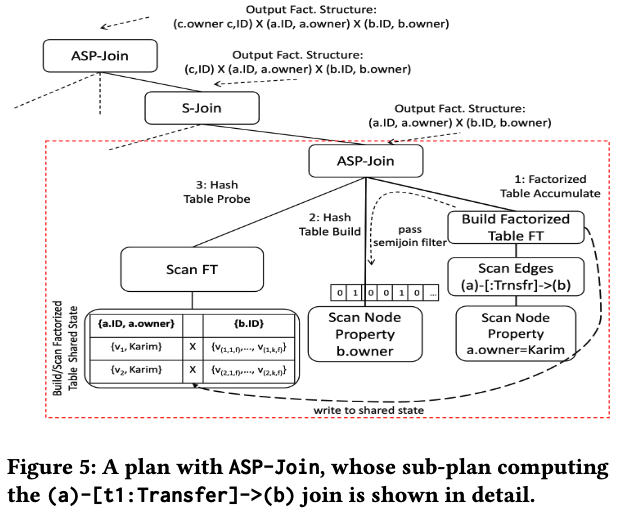
它的核心思想就在于将扫描出来的边保存在factorized tuple中,然后根据边的终点去获取对应属性,最终再重新扫描factorized tuple进行join。这样做的好处和其设计思想是一致的:
- 用factorized tuple保存join中间结果,节省了内存。并需要hash probe的数据就是factorized table
- 而hash build的数据可以通过类似的semijoin filter来获取,也避免了全盘扫描
Multiway WCO ASP Join
最后一种Join优化则是针对带环的join,称为WCO Join (Worst-Case Optimal Join),Kuzu中把带环的join交给Multiway WCO ASP Join算子完成。如下例子中的c就在pattern中出现了两次。(c为有intersection的部分,而a和b只出现了一次,没有intersection)。
Example 3
---
MATCH (c:Acc)<-[t3:DD]-(a:Acc)-[t1:Trn]->(b:Acc)-[t2:Trn]->(c)
WHERE a.owner ='Karim' RETURN a.owner, b.ID, c.ID
对于成环的query,Multiway WCO ASP Join的处理流程和ASP Join是非常相似:
- Pipeline 1首先把除了intersection的部分先求出结果,这个例子中就是
a和b,保存在factorized tuples中 - Pipeline 2和3再分别从
a和b去获取满足semijoin filter的id - Pipeline 4最后再次扫描factorized tuples,进行join
Multiway Join的最大优势在于,它把多个Binary Join转换成一个Multiway Join,本质上大大减少了join所需的运算量。以上面例子为例,先获取到(a:Acc)-[t1:Trn]->(b:Acc)部分的数据之后,如果是普通的Binary Join,需要分别从a向后拓展以及从b向前拓展得到两个c的集合记作c1和c2,最终需要再对c1和c2进行一次Binary Join。但实际上从a和b分别进行拓展时,由于pattern成环,只有c1和c2的交集才能满足最终结果,因此在进行多次Binary Join时,势必会进行大量无用计算。而Multiway Join则通过一个算子,反复利用第一步得到的factorized tuples,大大减少join的运算量。
My Random Words
论文里还有benchmark的相关对比,用的LDBC sf100数据集,不过只对比了short reads的几个query,感兴趣的可以去看看。Kuzu针对图里面的join做了不少优化,非常有借鉴意义,尤其是factorization和Multiway Join Operator。(文中其他的优化我们目前系统也基本做了)
不过我比较存疑的一点在于盲目的使用顺序扫描真的合理吗?这里引用一段原文S-Join时的执行流程:
Pipeline 2 (Hash Table Probe): Sequentially scans the a.owner column (only the values that pass the semijoin filter) and probes the hash table to join a.owner values with hashed factorized tuples.
在扫描a.owner的时候的确可以顺序扫描,但显然要想高效利用semijoin filter,单纯顺序IO是不够的,只读取满足过滤条件的对应a.owner更合理。换句话说Sequentially scan和only the values that pass the semijoin filter这两部分是矛盾的,最多可以做到在顺序扫描时,根据semijoin filter的提示,跳过一些不必要的data block。当然这可能和Kuzu使用列存有一些关系,而在目前我们基于行存的图数据库上,一旦数据量足够大,少量的随机IO开销有可能远低于全表扫描。
Reference
- KÙZU Graph Database Management System
- Making RDBMSs Efficient on Graph Workloads through Predefined Joins
- Columnar Storage and List-based Processing for Graph Database Management Systems
- Why (Graph) DBMSs Need New Join Algorithms: The Story of Worst-case Optimal Join Algorithms
- Factorization & Great Ideas from Database Theory