Parallel Grouped Aggregation in DuckDB
Aggregate的相关优化~
Aggregation
SQL主要是通过Aggregate来计算一些数据的统计值,比如sum/avg/count/min/max等等,另外还可以通过GROUP BY子句来实现grouped aggregation。Aggregate和其他算子有一个显著的区别:它会改变输出的基数。大多数算子都是输入多少行数据,就输出多少行数据,而Aggregate则是根据有多少个group就输出多少行数据。比如:
-
Normal Aggregate: 有Group By子句和聚合函数
select col0, sum(col1) from table group by col0; -
Global Aggregate: 没有Group By子句,只有聚合函数
select sum(col0) from table; -
Distinct Aggregate: 没有Group By子句和聚合函数,有Distinct关键字,按对应列去重
select distinct col0 from table;表面上Distinct和Aggregate无关,但一般其实现原理就是把Distinct列作为HashTable的GroupKey,最后输出HashTable的GroupKey,因此Distinct实际是一个隐式的聚合函数
一般来说,影响Aggregate性能有如下要素:
- 输入数据的行数
- 给定的输入数据有多少group(数据分布)
GROUP BY字段的类型(不同类型计算hash的开销不同)和数量- Aggregate的算法,一般就两种
- Sort Aggregation: 排序之后,分组相同的数据自然就相邻
- Hash Aggregation: 对GROUP BY字段求哈希,哈希相同的数据进入到同一个bucket中,然后再对bucket内数据进行聚合
由于Sort Aggregation的复杂度通常来说都会比Hash Aggregation高,我们今天主要聚焦于Hash Aggregation。如果哈希表使用拉链法,在遍历链表时可能伴随内存随机寻址,对于locality不友好,并且插入性能往往会随着链表变长而下降。而开地址探测需要解决哈希表扩容的问题,每当哈希表扩容,大量数据需要进行拷贝或者移动。Velox和DuckDB都采用了相同的办法,Two-Part Aggregate HashTable。
Two-Part Aggregate HashTable
为了解决rehash时大量移动数据的问题,首先将HashTable拆为两部分:
- Payload blocks: 多张表,每张表保存一部分数据,固定大小
- Pointer: 哈希表,保存原始数据到payload的映射
以下图为例:有两个Payload Blocks。根据原始数据T,对T中的GROUP BY字段G求哈希,保存在对应的Payload Block中。同时建立Pointers到Payload Block的映射。
- Pointer的三列分别为
行号,Payload Block序号,对应Payload Block中的行号 - Payload的三列分别为
行号,GroupBy的字段,聚合函数的值(比如Sum、Count等)
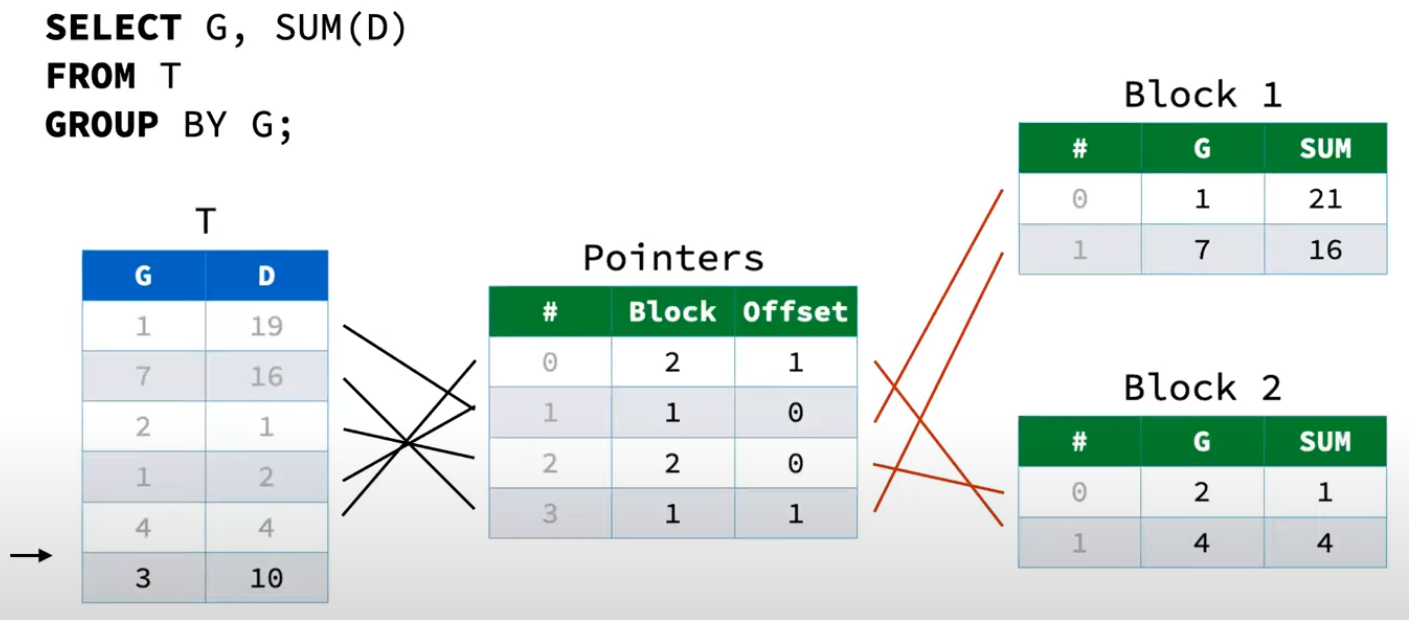
此时往HashTable中处理新的一行数据(3, 10)时,由于HashTable已经没有空位(或者负载因子大于特定值),需要进行扩容。对于Two-Part Aggregate HashTable的扩容步骤如下:
- 删掉老的Pointers
- 生成原有大小两倍的空Pointers
- 重新扫描既有的Payload Blocks,对每一行数据执行如下操作:
- 根据GroupBy字段计算哈希值,对Pointers大小进行求模得到起始探测位置
- 如果起始探测位置为空,将Block id和Offset写入
- 如果起始探测位置不为空,进行线性探测,直到Pointers对应行为空,将Block id和Offset写入
- 扩容完成后,继续插入
(3, 10)
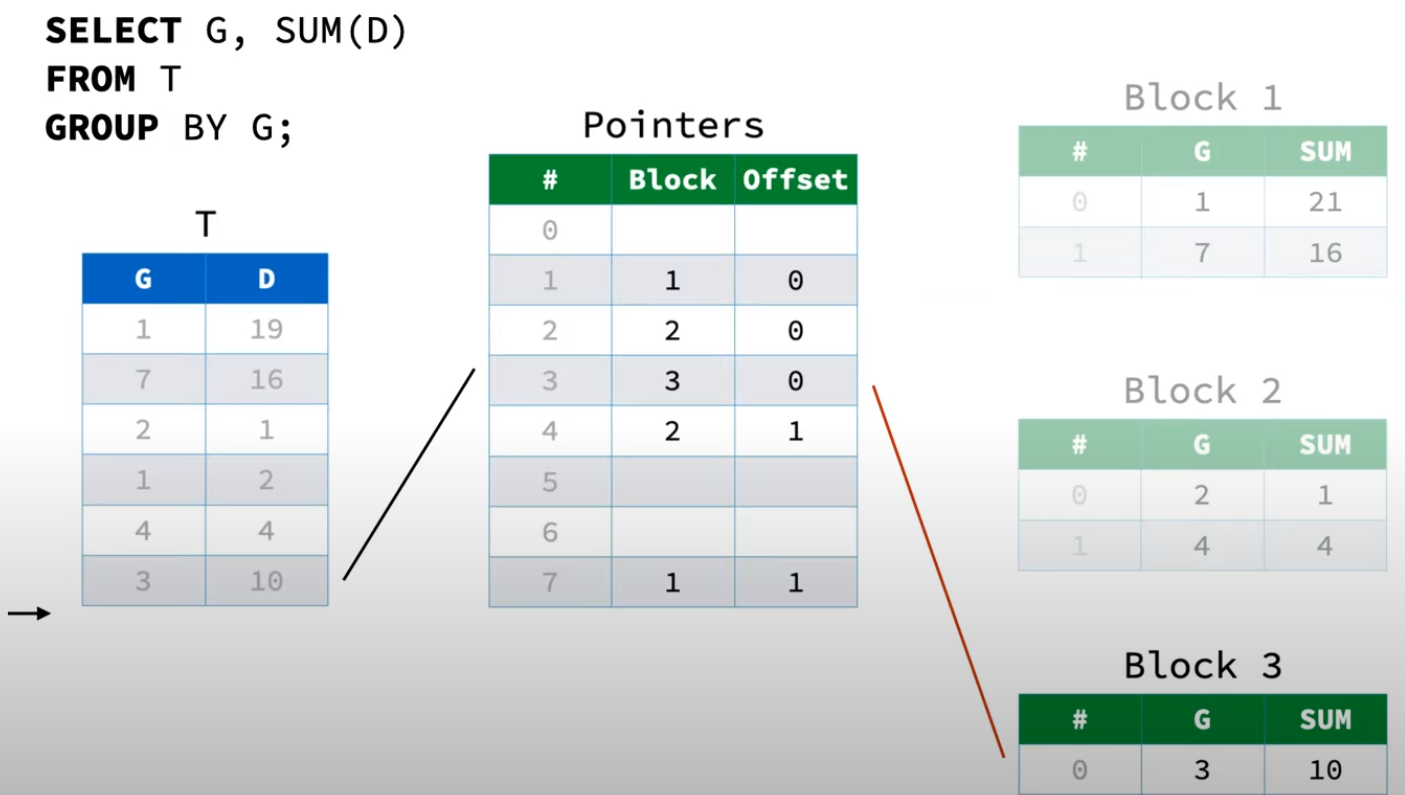
通过这样的做法Two-Part Aggregate HashTable在扩容的时候就能够避免移动数据。这里还有一个优化点,每次rehash的时候,遍历Payload Blocks中每一行数据计算哈希值的开销也不可忽略(尤其是对于字符串类型的数据)。因此DuckDB就在Payload Block中增加了一列,保存GroupBy字段的哈希值,避免每次rehash时重复计算哈希。本质上属于空间换时间的一种优化。
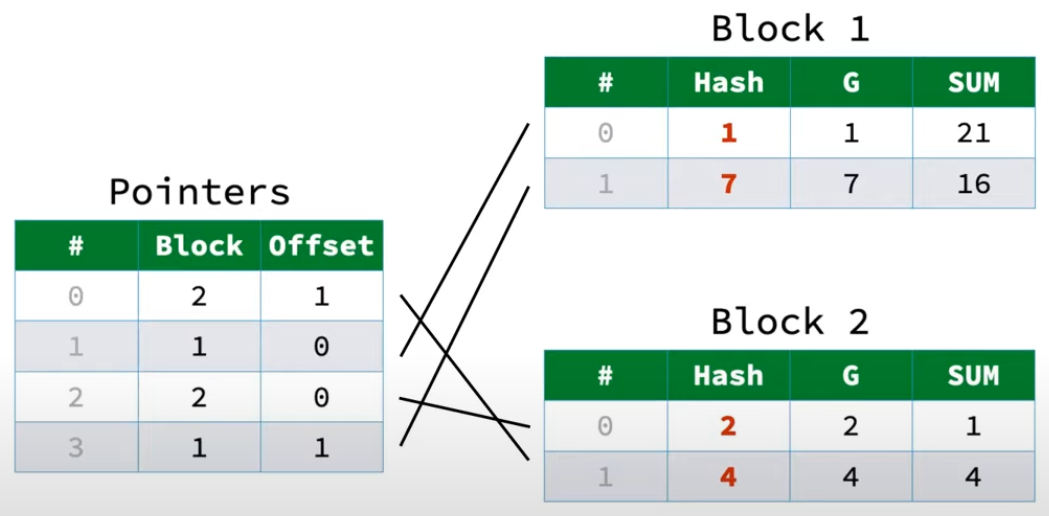
而Two-Part Aggregate HashTable也存在一些性能缺陷:每当查哈希表时,首先计算GroupBy字段的对应哈希值,然后确定Pointers表中的初始探测位置。在后续线性探测的过程中,一旦Pointers中每行不为空,就代表对应的Payload Block中可能有当前数据,此时需要去逐个遍历检查对应的Payload Block。(比如增加一个G = 7的数据,计算哈希,确定Pointers中起始探测位置为Pointers中第一行Block = 1 Offset = 0,此时需要去Block 1 Offset >= 0的遍历所有数据,以确定G = 7的数据是否存在于Block 1中)
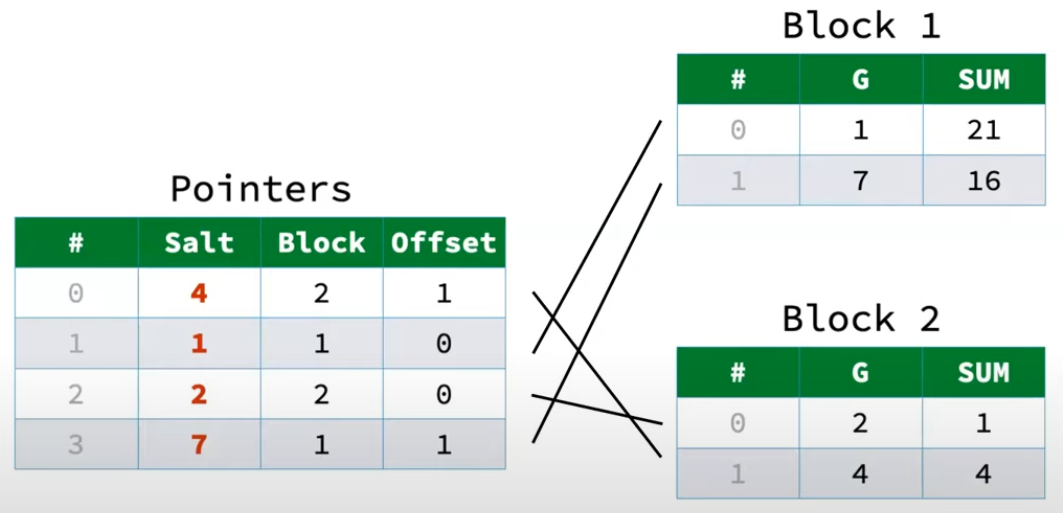
随着Pointers哈希表的负载不断提升,每次进行线性探测时,都需要去对于Block中进行顺序查找,这显然会导致大量的随机寻址(不断在Pointers和Payload Block间切换)。解决办法就是在Pointers中带上原始GroupBy字段哈希值的一部分,称为Salt。理论上Salt可以是完整的哈希值,但DuckDB中是两个字节,Velox中是一个字节,之所以只保存一部分是因为保证Pointers的一行保存在一个cache line中。
引入Salt之后,在线性探测时,每次就对比当前数据的Hash值的Salt和Pointers中的Salt。如果相等,再通过Block id和Offset找到对应数据进行比对,以检查对应的数据是否存在于Block中。如果不相等,则说明对应的Block中一定不存在这条数据。从这个角度看,Salt的作用和一个Bloom Filter类似,有一定的误报率,需要额外的存储空间,但能够大量避免无效的查找。
Velox中的原理也和DuckDB非常相似,可以参考这篇文章 Velox HashAggregation的spill实现 - 知乎 (zhihu.com)。Velox中的Pointers称为Tags,而Payload Block只有一个,称为RowContainer。
Parallelism Grouped Aggregation
上面的HashAggregation只是一个单线程的过程,当然,传统的火山模型中的Exchange Operator能达成多线程的Aggregate。但Exchange Operator有以下问题:
- 静态哈希,Exchange的分片只能在planning过程中确定
- 中间需要shuffle或者copy数据
- 不能根据不同group中的数据量动态调整执行流程
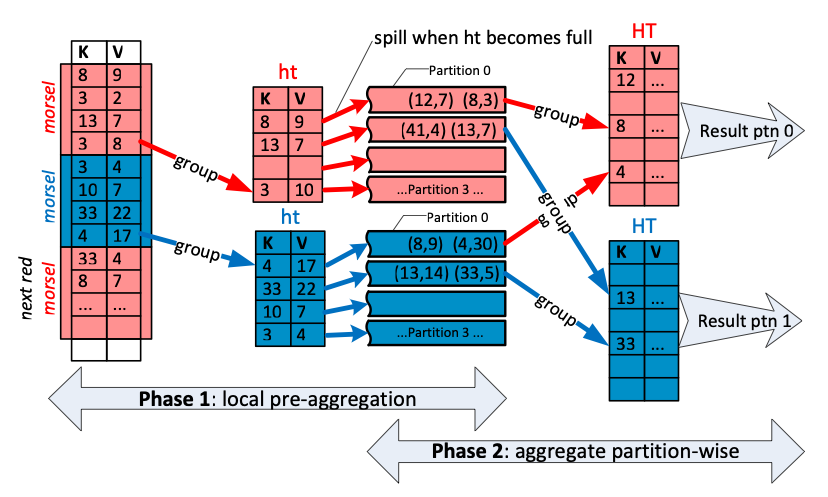
根据Morsel-Driven Parallelism这篇论文的介绍,DuckDB为了实现多线程的Aggregate,将原始数据切分为多个morsel,由多个线程独立处理一部分morsel,并构建ThreadLocalHashTable。同时,根据hash值,将ThreadLocalHashTable分为多个Partition,相同hash值的数据一定会分到相同的Partition。最终再由多个线程将多个ThreadLocalHashTable中,按Partition进行聚合。具体流程如下:
- 首先进行ThreadLocal的聚合,即每个线程处理自己的Mosel,将结果保存至当前线程的pre-aggregation table中。这个table固定大小,其中会按哈希值分成若干Partition。如果某个Partition满了,就会spill。总计会有N个Table,M个Partition。
- 第一步完成之后,总计会有N个Table,每个Table中有M个Partition。此时将N个Table中的同一个Partition进行最终的聚合,因此将M个Partition的聚合任务提交给线程池。由一个线程池进行同一个Partition的HashTable的聚合。
- 如果某个核处理完一个Partition之后,会接着处理下一个Partition。处理完的Partition可以直接对外输出,不必等待其他Partition。
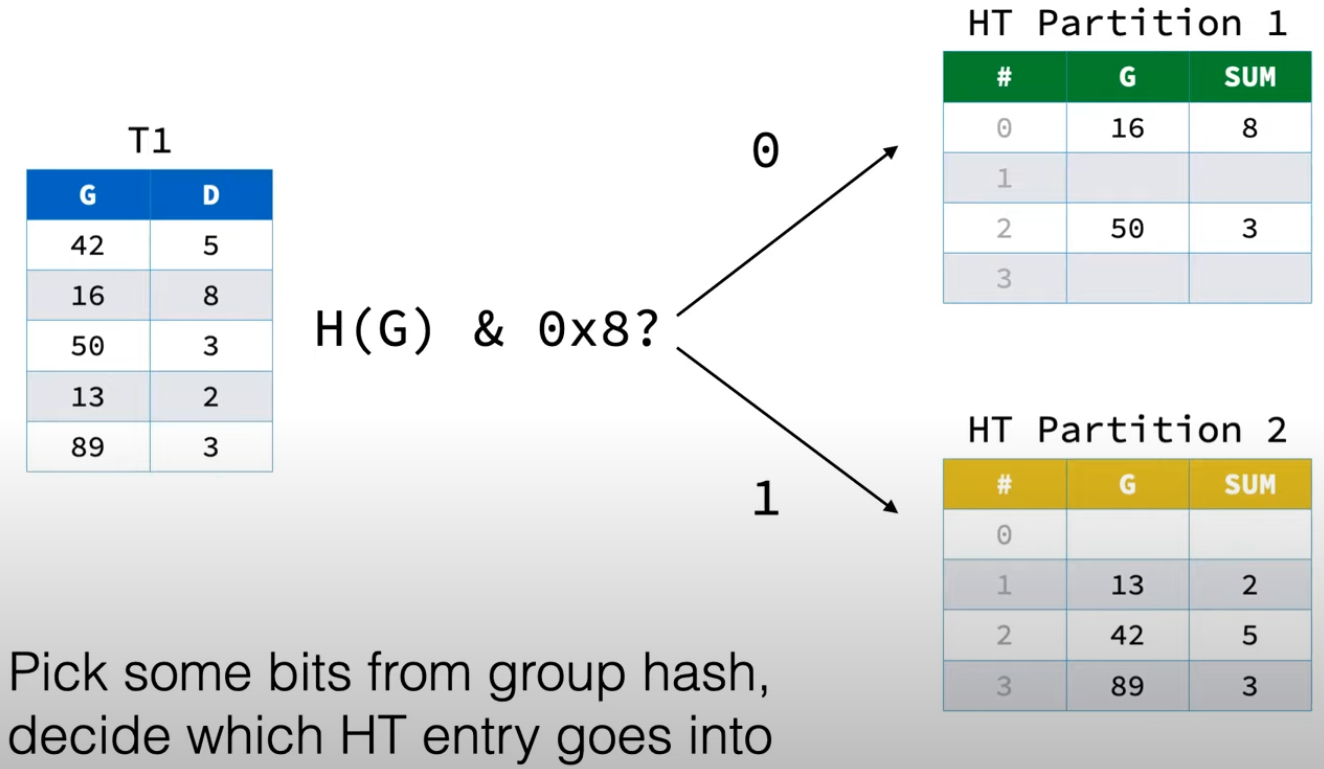
一个实际例子如下:G为GroupBy字段,对G求哈希之后,按位与上0x8,如果是0则属于Partition 1,如果是1则属于Partition 2。每个线程处理自己的数据之后,都会得到两个Partition的ThreadLocalHashTable。
按位与的这个思路在这篇论文中也有过介绍Main-Memory Hash Joins on Multi-Core CPUs,称为Radix Partitioning。
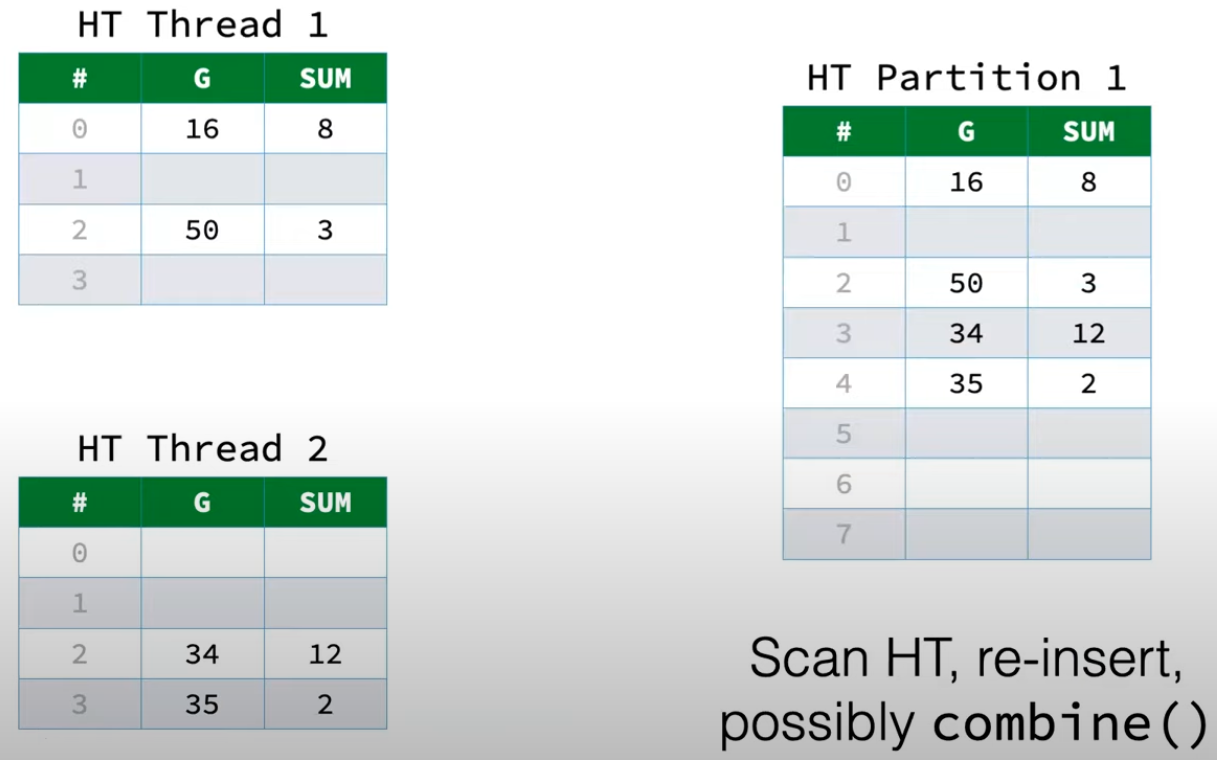
当所有线程都完成Local pre-aggregation之后,就可以将不同线程的同一个Partition的ThreadLocalHashTable进行合并,得到这个Partition的最终结果。
通过这种形式的拆分,能够解决传统的火山摸型中Exchange Operator的一些痛点:
- 能够根据不同group中的数据量,进行不同Partition的合并(都是将合并多个Partition提交给一组线程池)
- 能够适应海量group的聚合
- 能够动态调整并行度
- 不需要移动数据
然而,对数据进行分片不是没有代价的,所以DuckDB只有当某个线程的数据量达到一个阈值之后,才会启用。
大概的思想就是这样,实际上Velox和DuckDB针对Aggregate做了大量优化,这篇文章只是一个初步介绍,有机会可以结合代码展开一下。
Reference
Parallel Grouped Aggregation in DuckDB - DuckDB
Velox HashAggregation的spill实现 - 知乎 (zhihu.com)
DuckDB:高性能并行分组聚合 - 知乎 (zhihu.com)
Main-Memory Hash Joins on Multi-Core CPUs/ Tuning to the Underlying Hardware 论文解读 - 知乎 (zhihu.com)